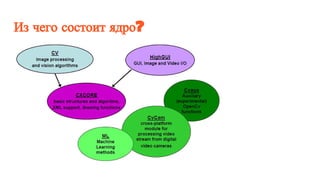
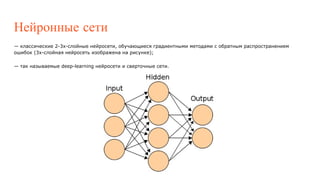
Документ описывает использование Ruby и OpenCV для различных задач компьютерного зрения, таких как интерпретация изображений и распознавание жестов. Он также затрагивает сложности в робототехнике, алгоритмах глубокого обучения и методы распознавания символов. Особое внимание уделяется функциональности модулей OpenCV и применению нейросетей в различных областях.