Downloaded 12 times














































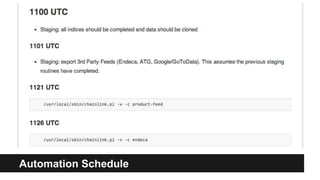














This document summarizes strategies for scaling a Magento installation. It discusses code management techniques like using good IDE tools and avoiding modifying core files. It outlines hardware profiles including networks, databases, caches and utility servers. It describes the team structure with 16 committers across 5 departments and 31 vendors. Effective communication practices and documentation are emphasized. Release processes, deployments, community participation and collaboration texts are also summarized.













































































