Download to read offline















































![AMD SME -contd
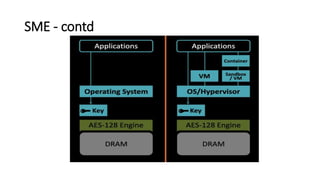
• Support for SME can be determined
through the CPUID instruction.
The CPUID function 0x8000001f[eax]
reports if SME is supported.
• If support for SME is present,
MSR 0xc00100010 (MSR_K8_SYSCFG)
Bit[21] can be used to determine if
memory encryption is enabled.
• Bits[5:0] pagetable bit number used
to activate memory encryption.(C-bit)](https://image.slidesharecdn.com/summaryoflinuxkernelprotectionforonline-221231200608-bb775fbc/85/Summary-of-linux-kernel-security-protections-61-320.jpg)













The document provides an overview of Linux kernel security protections and associated attacks, discussing kernel configuration, memory mapping, and self-protection techniques. Specific topics include strict memory permissions, randomization methods like KASLR, stack protection mechanisms, and methods to counter various exploitation techniques. Additionally, it highlights vulnerabilities and countermeasures such as module signing and hardware-assisted protections like SMEP and MAP.





























![Jaime Peñalba - Kernel exploitation. ¿El octavo arte? [rooted2019]](https://cdn.slidesharecdn.com/ss_thumbnails/rooted2019-kernelexploitation-190403185847-thumbnail.jpg?width=640&height=640&fit=bounds)



































