Downloaded 54 times


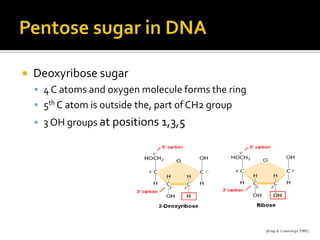
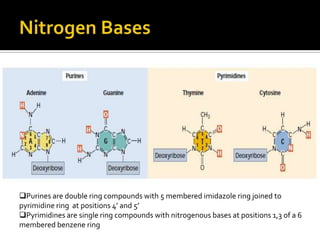


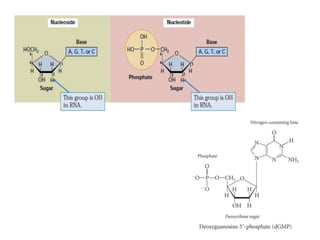
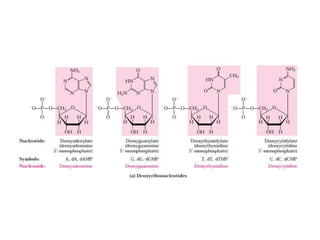
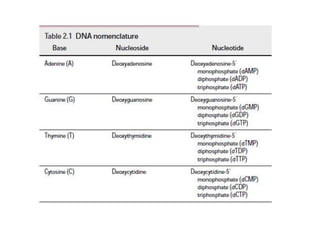
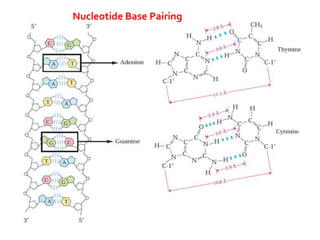
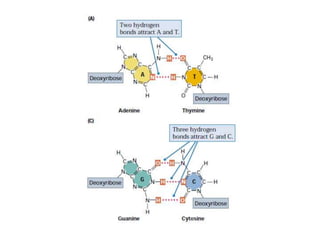
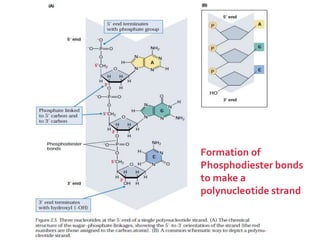
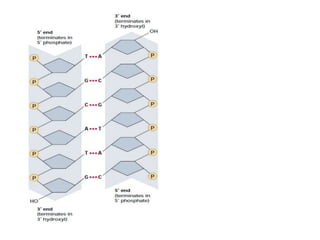

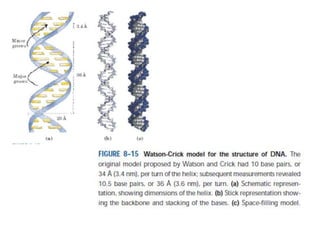

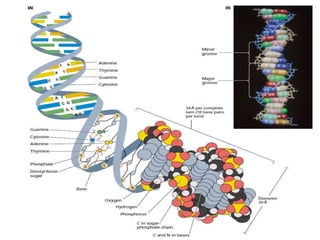


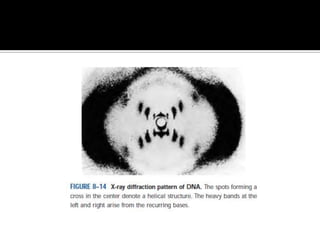






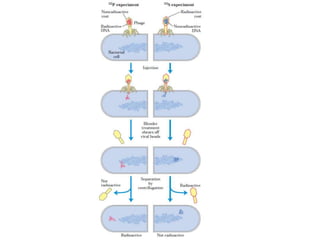

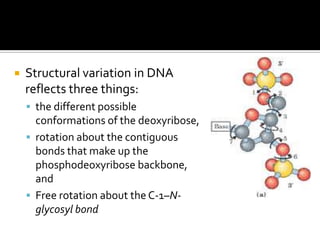

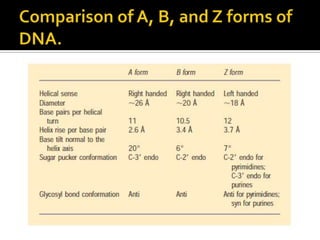
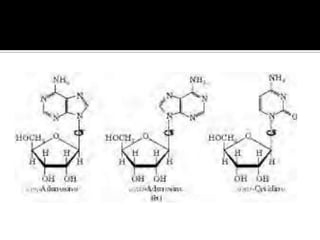






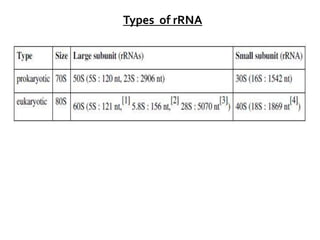

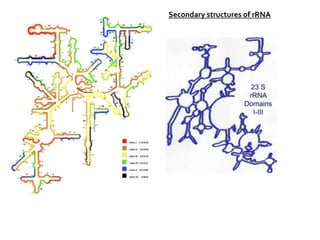
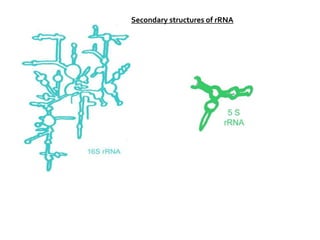







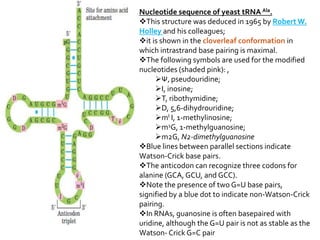
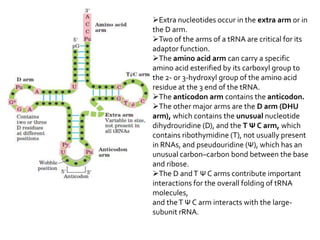

1. DNA is composed of nucleotides containing deoxyribose, phosphate groups, and one of four nitrogenous bases (A, T, G, C). 2. RNA is similar in structure but contains ribose rather than deoxyribose and uracil rather than thymine. 3. There are three main types of RNA - rRNA, tRNA, and mRNA - which have different functions like forming ribosomes or carrying genetic code for protein synthesis.























































