Downloaded 11 times
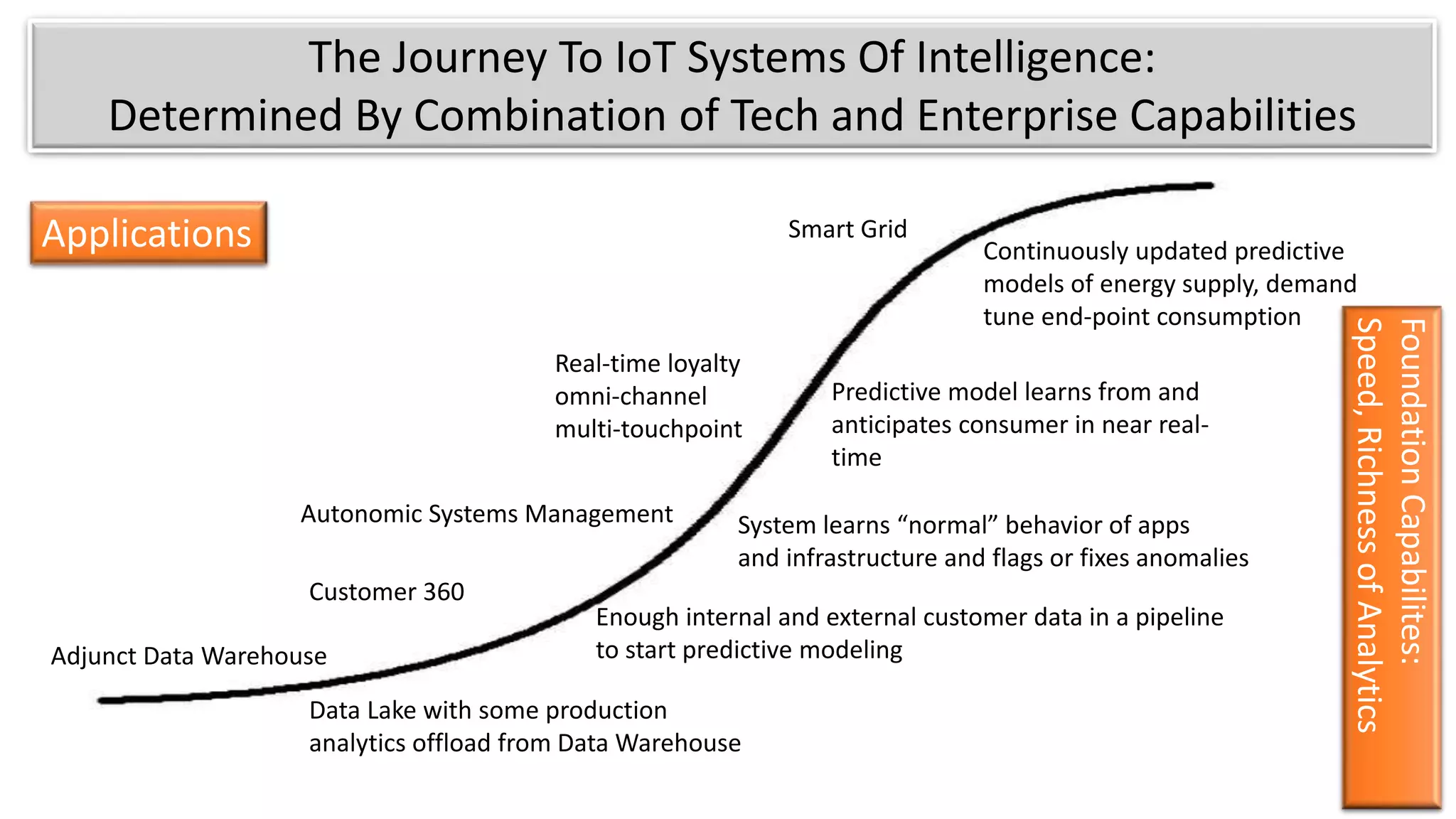


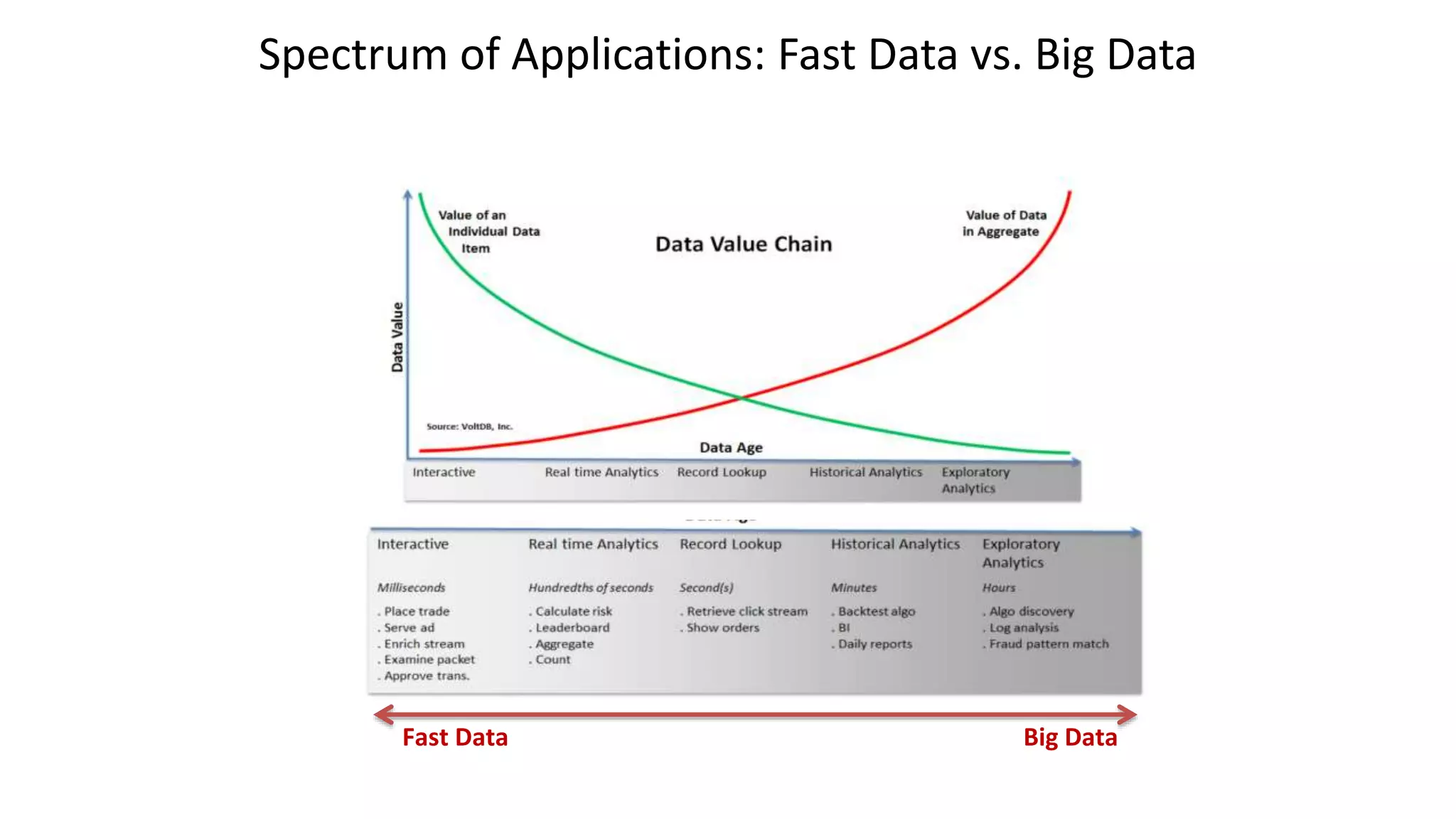
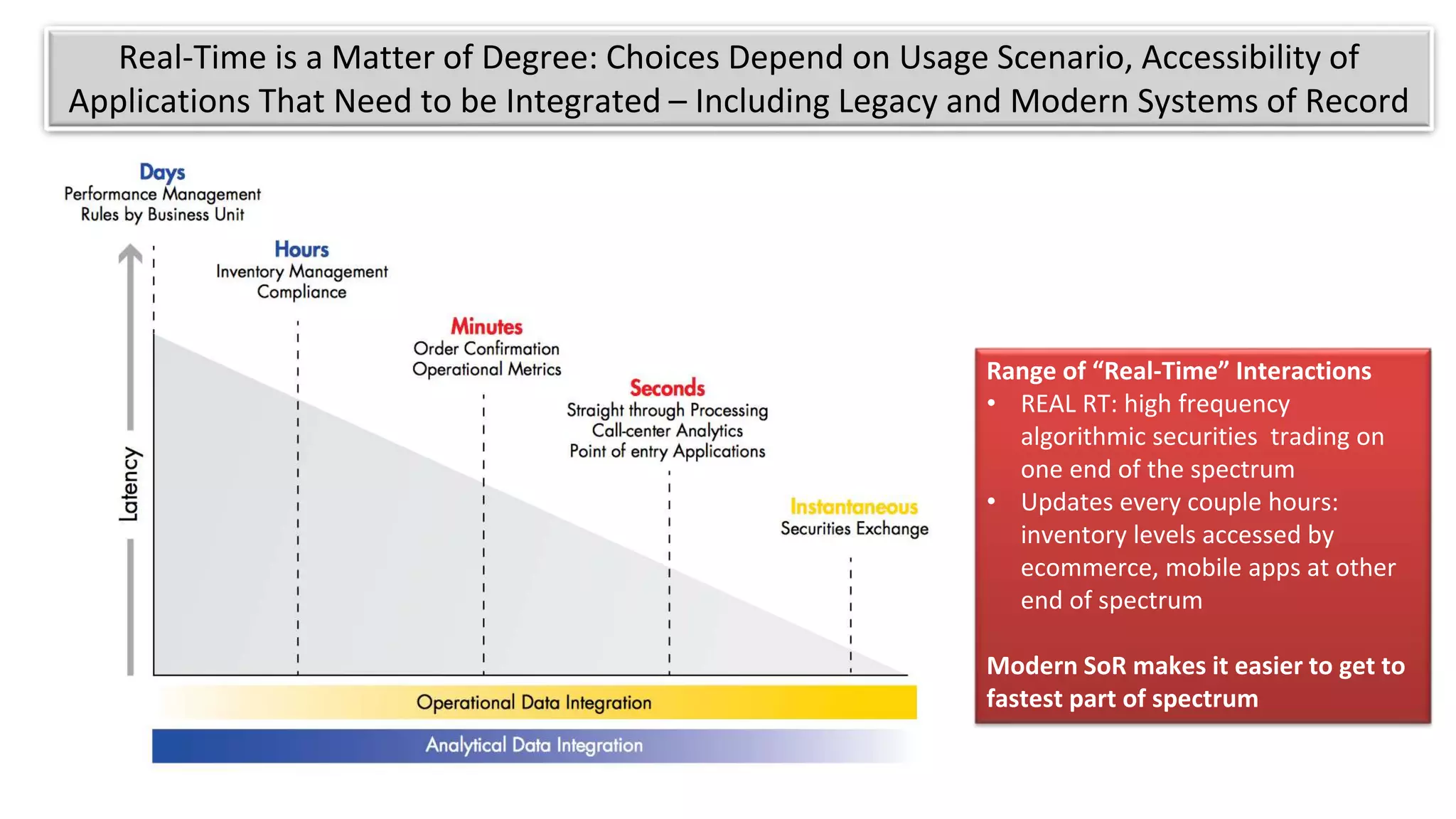
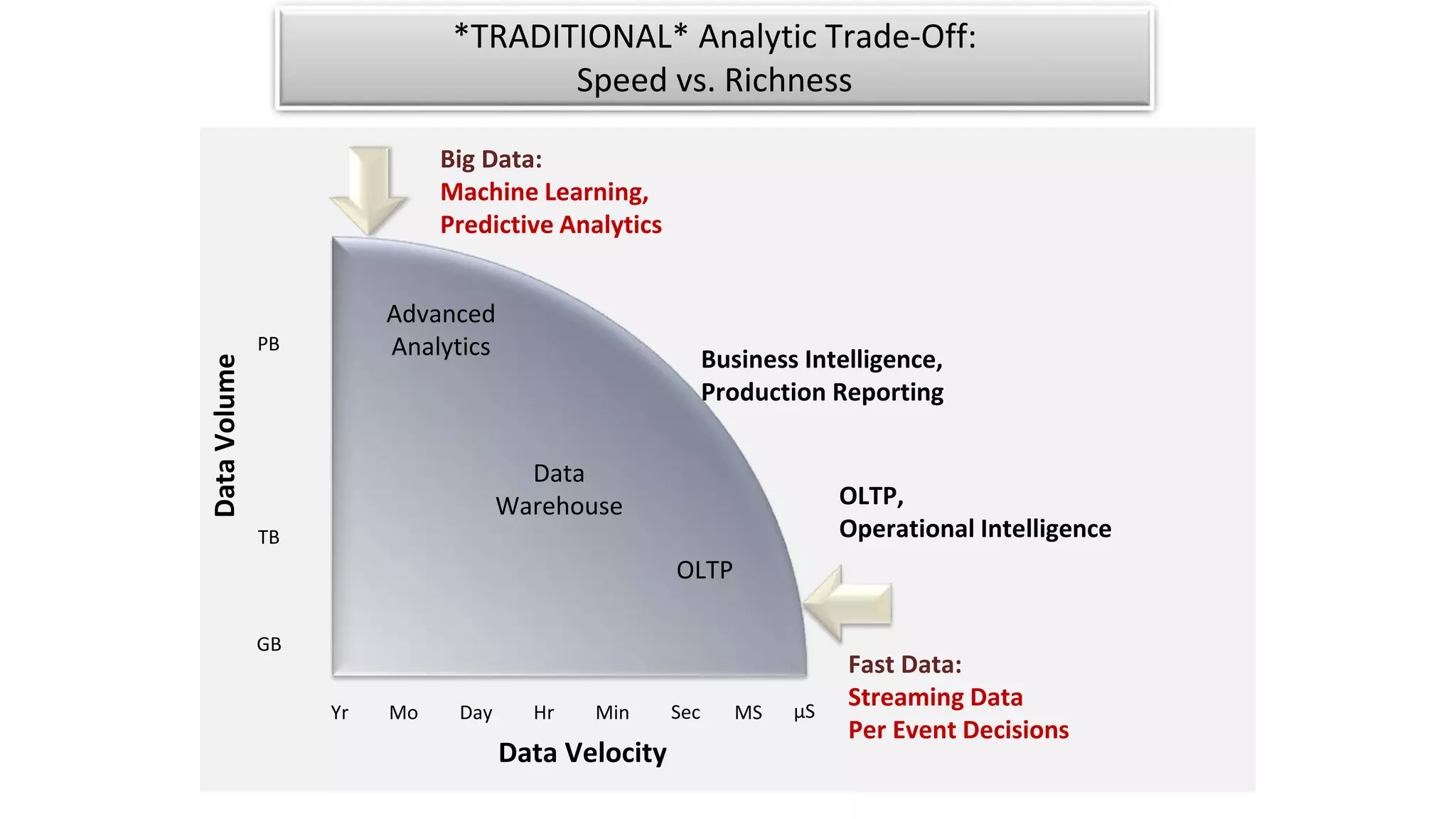
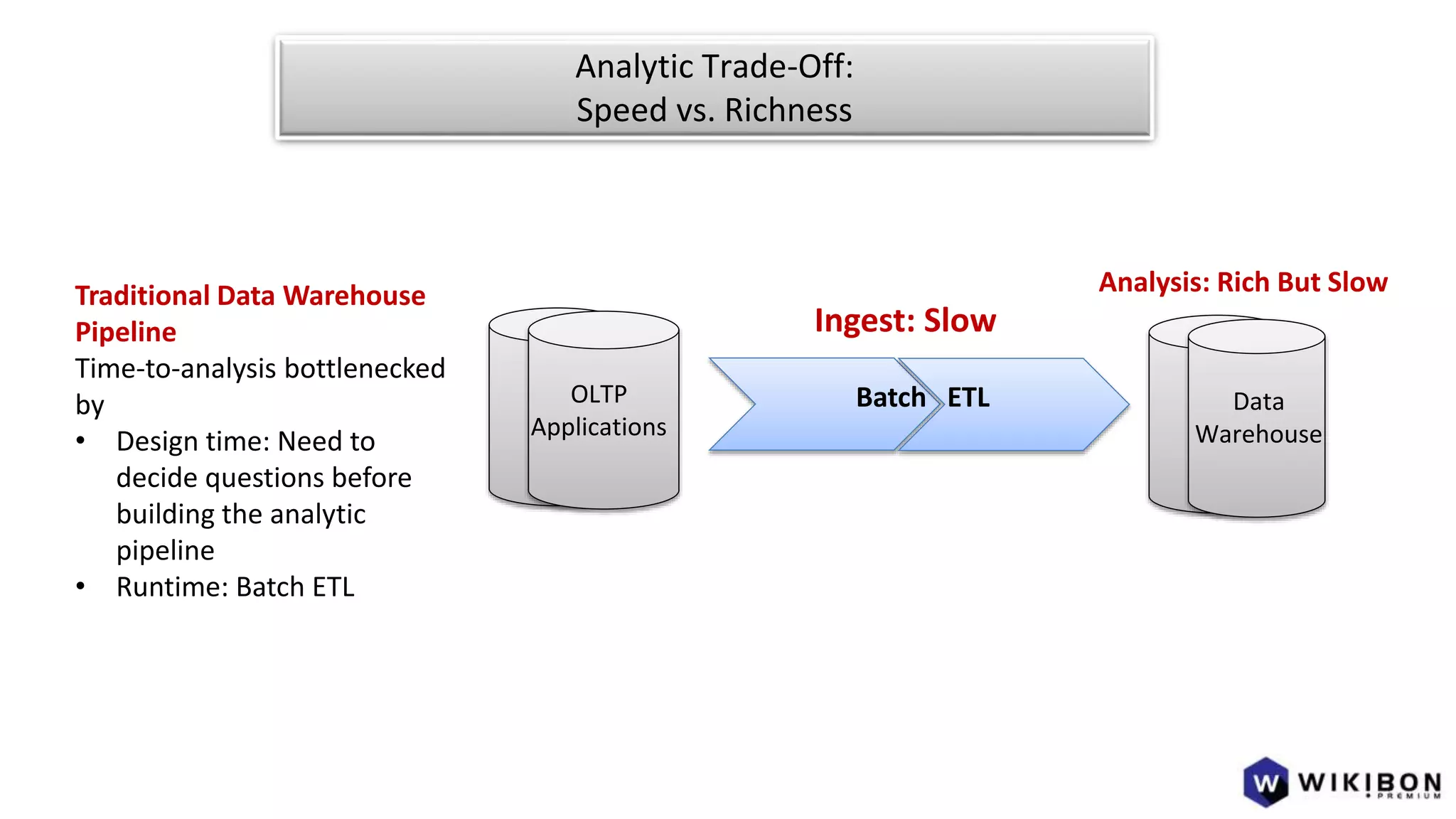
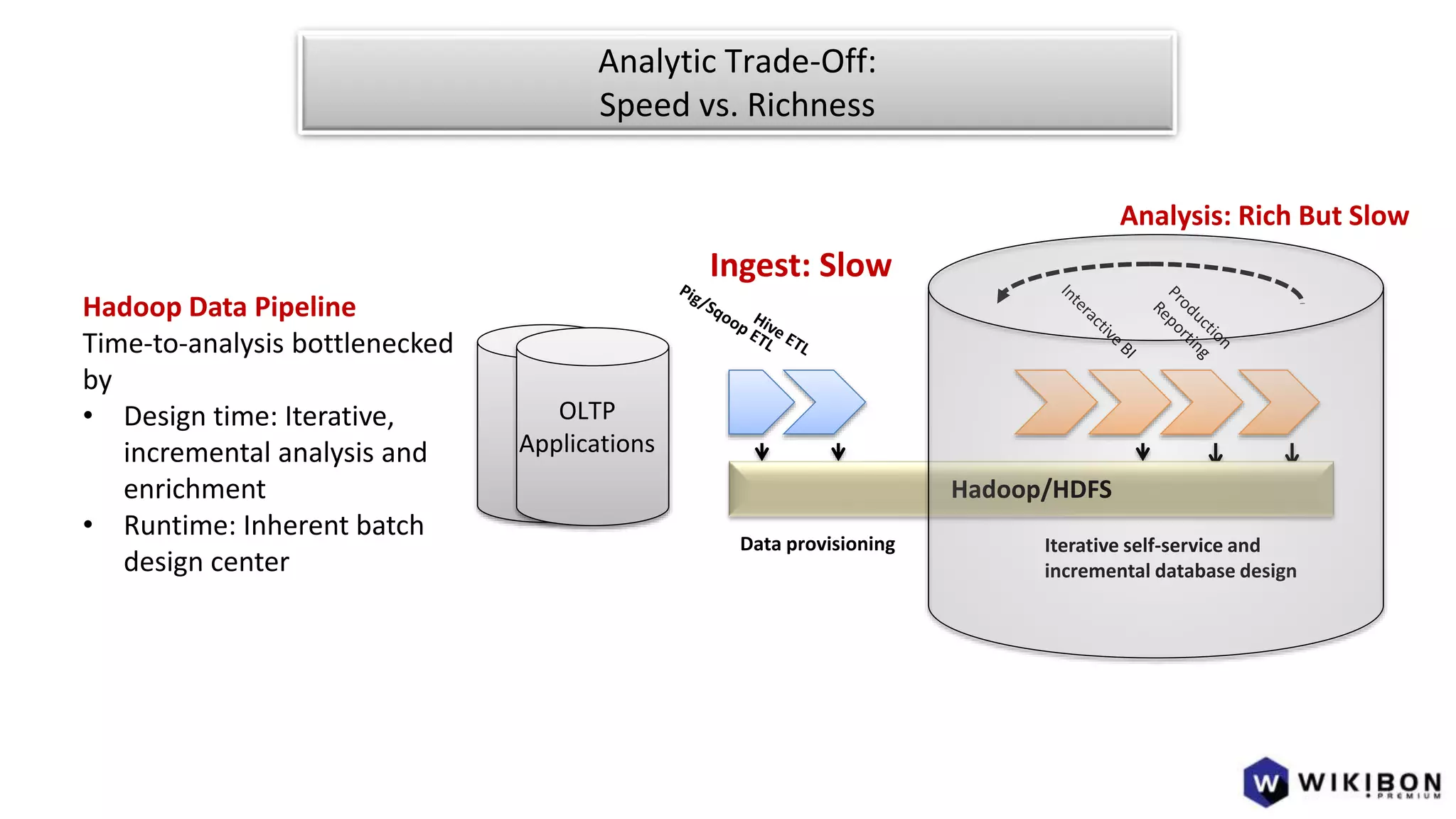
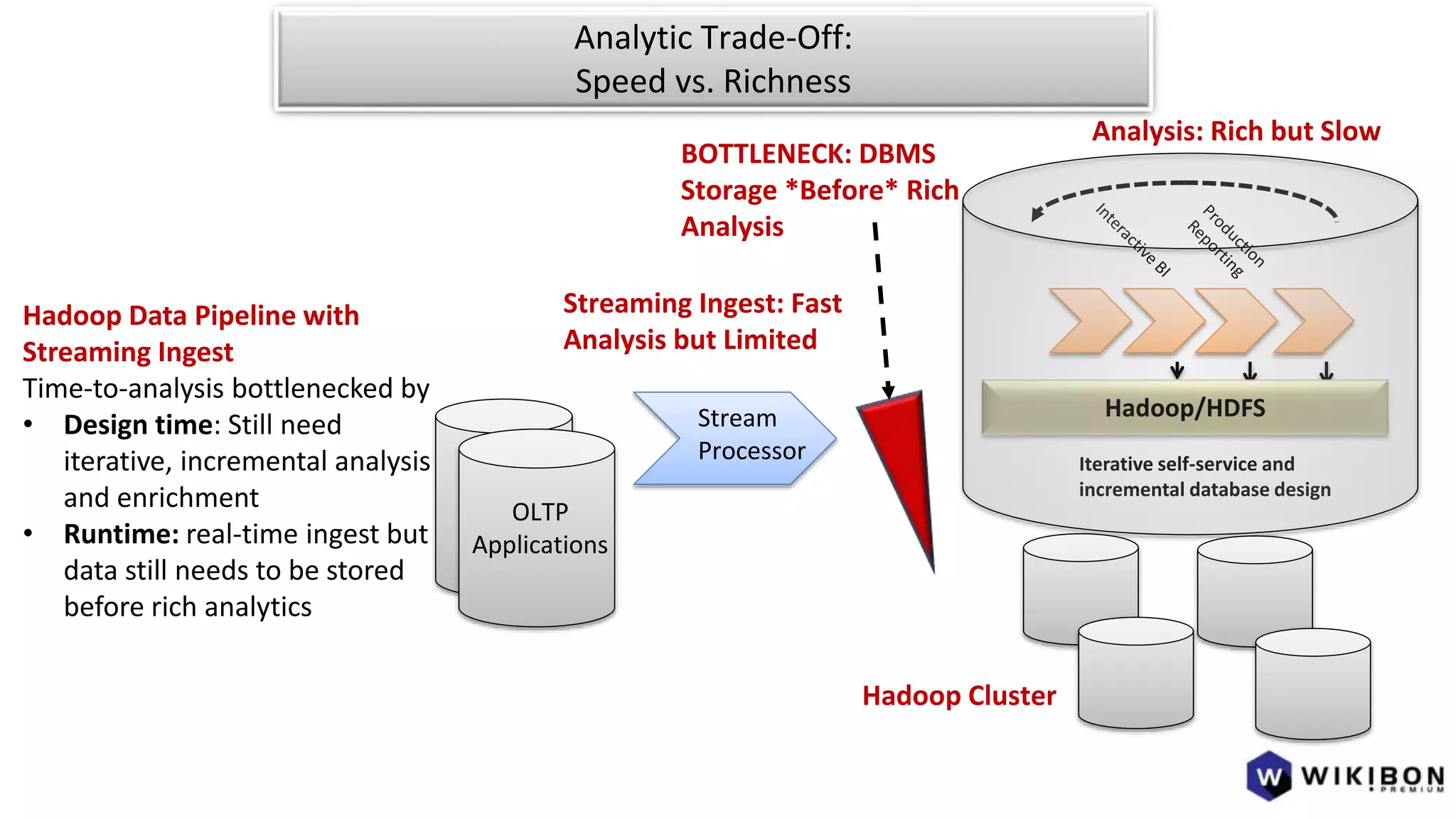
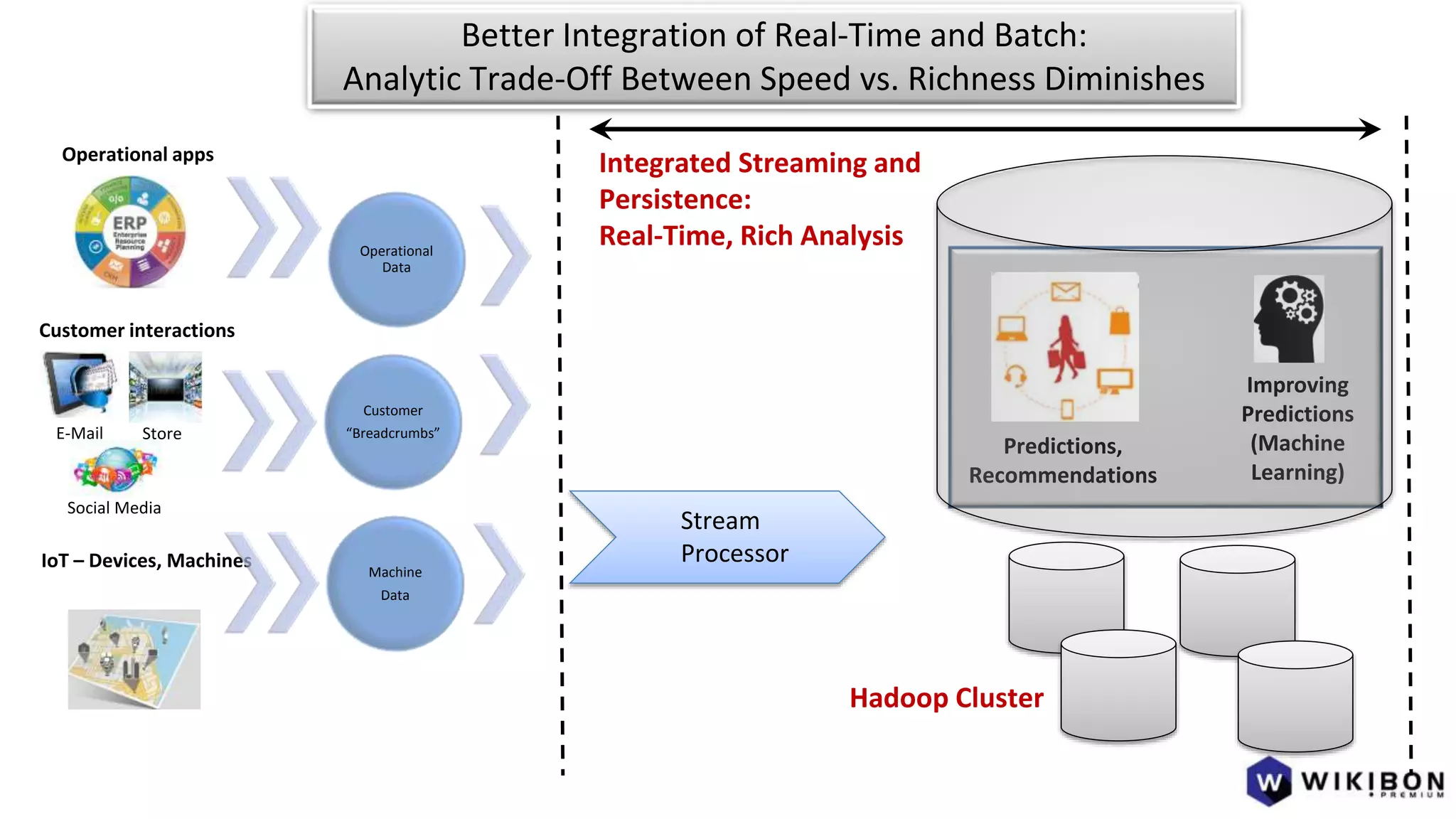
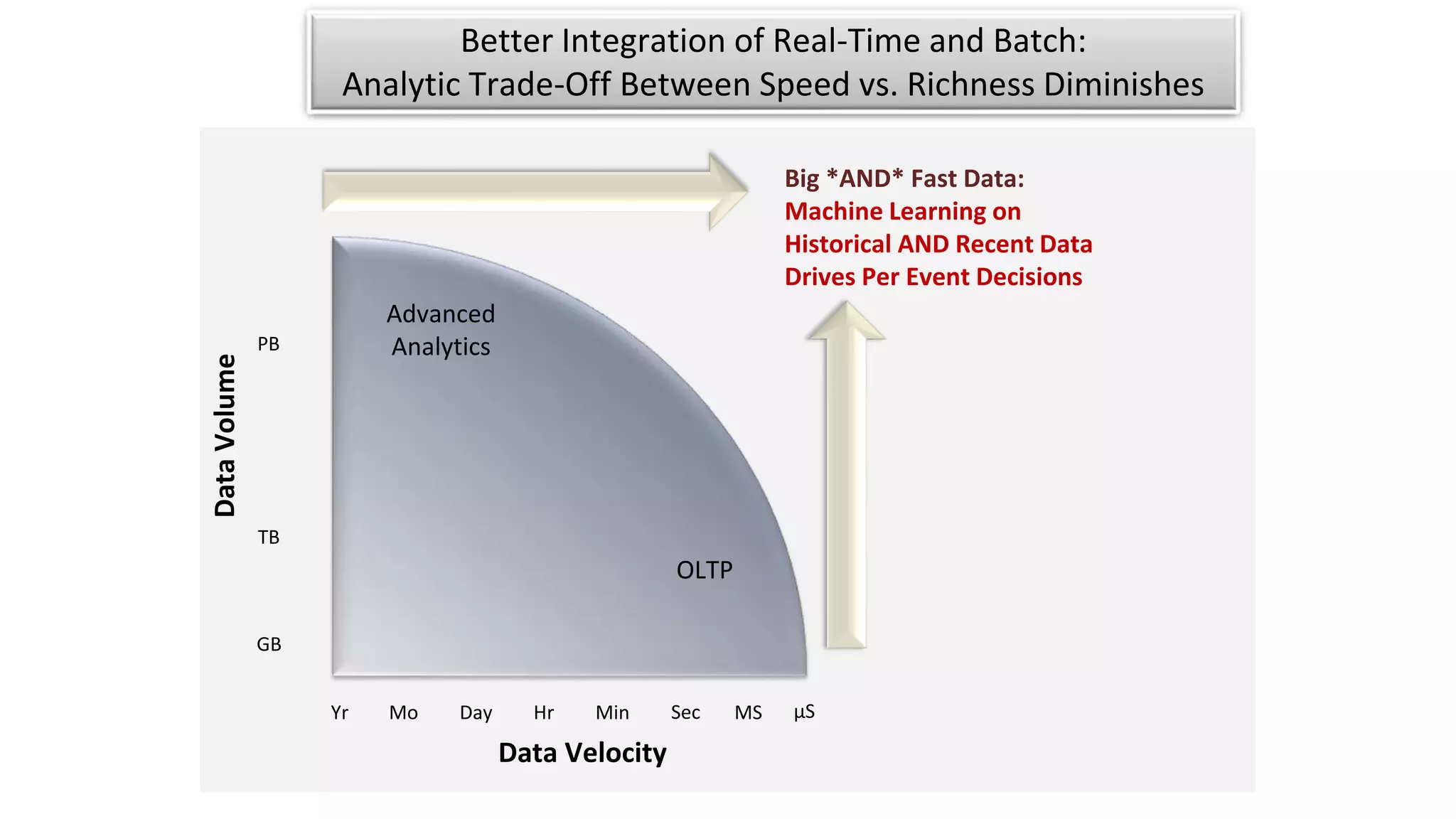
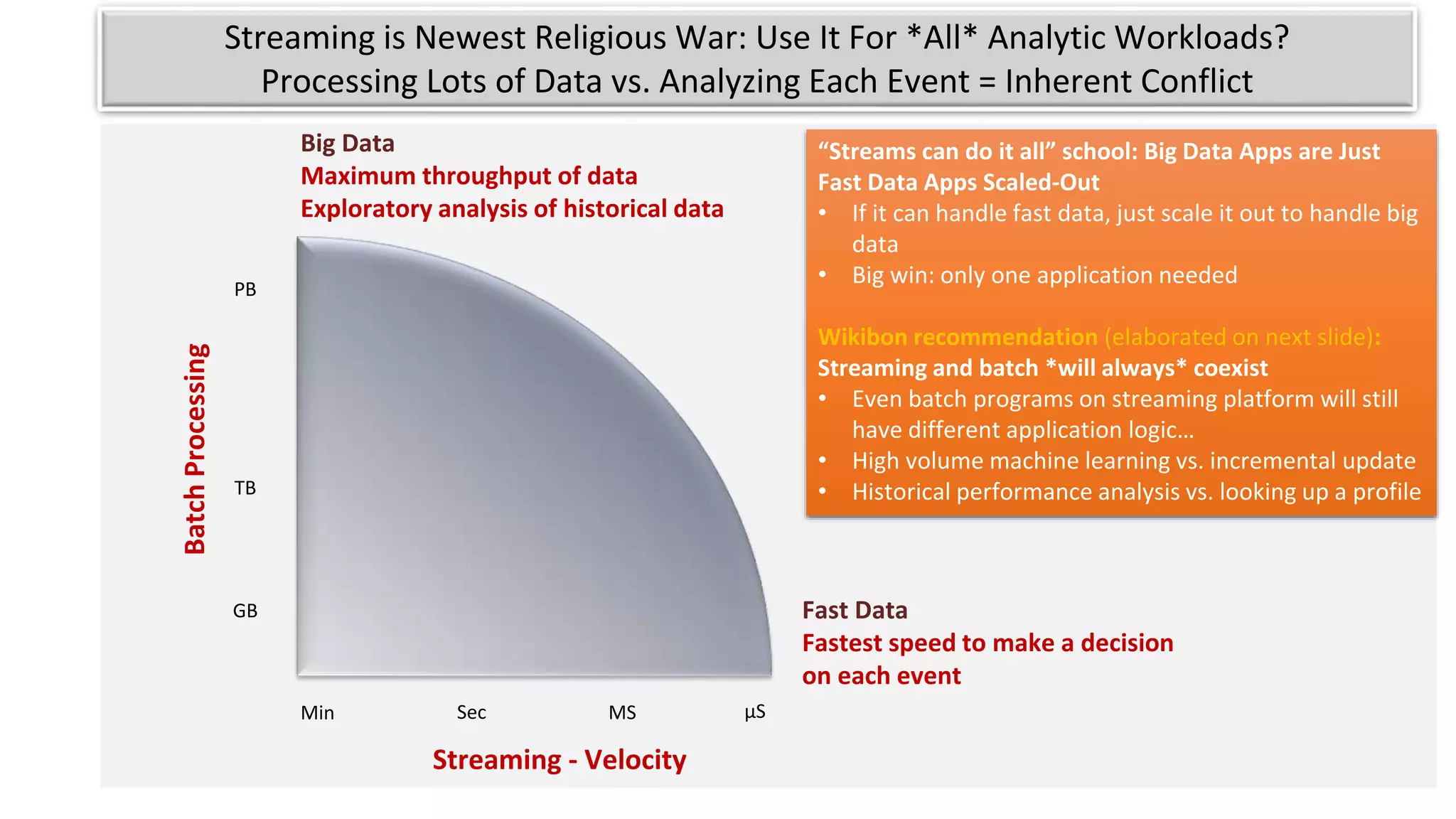
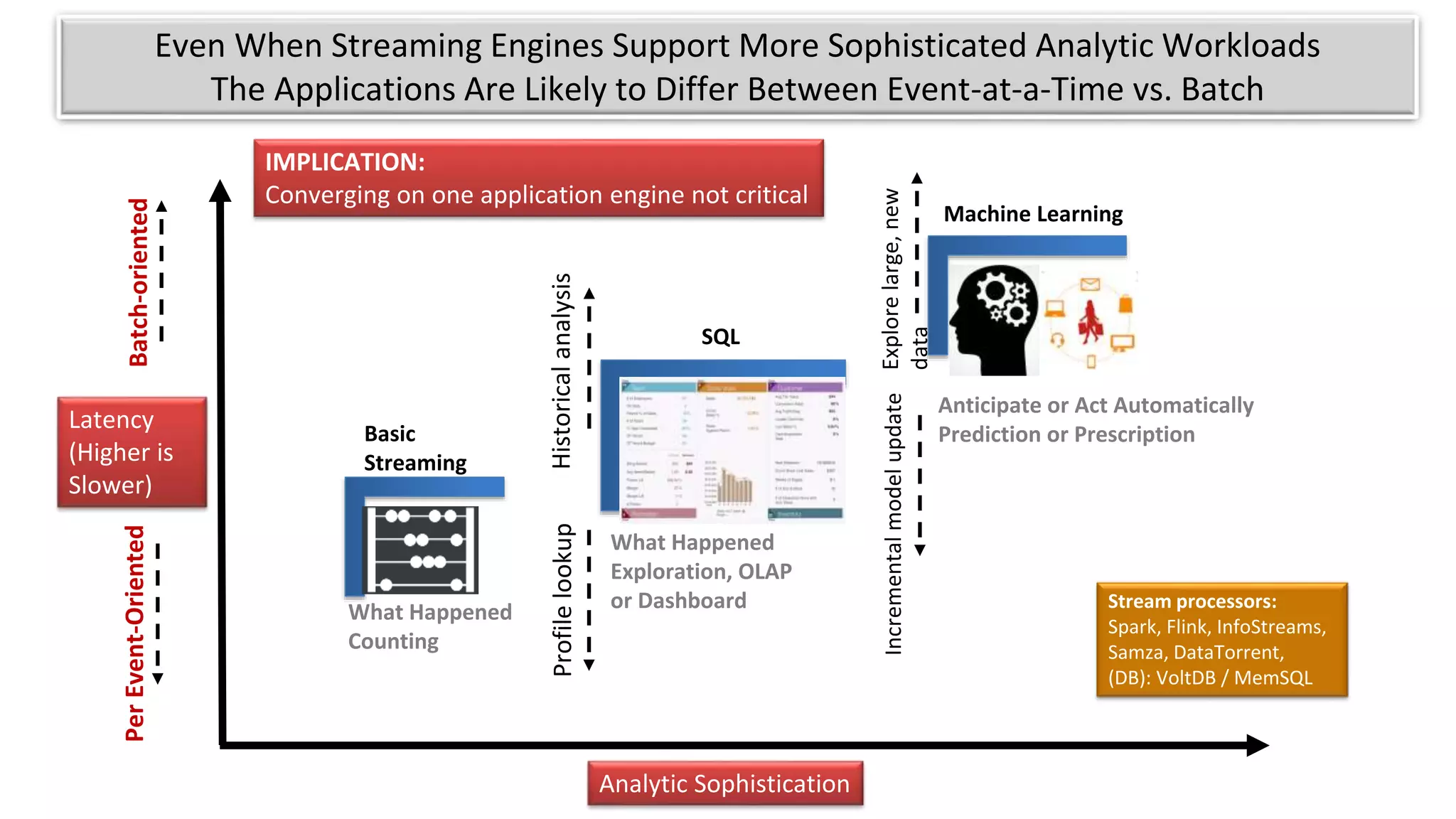
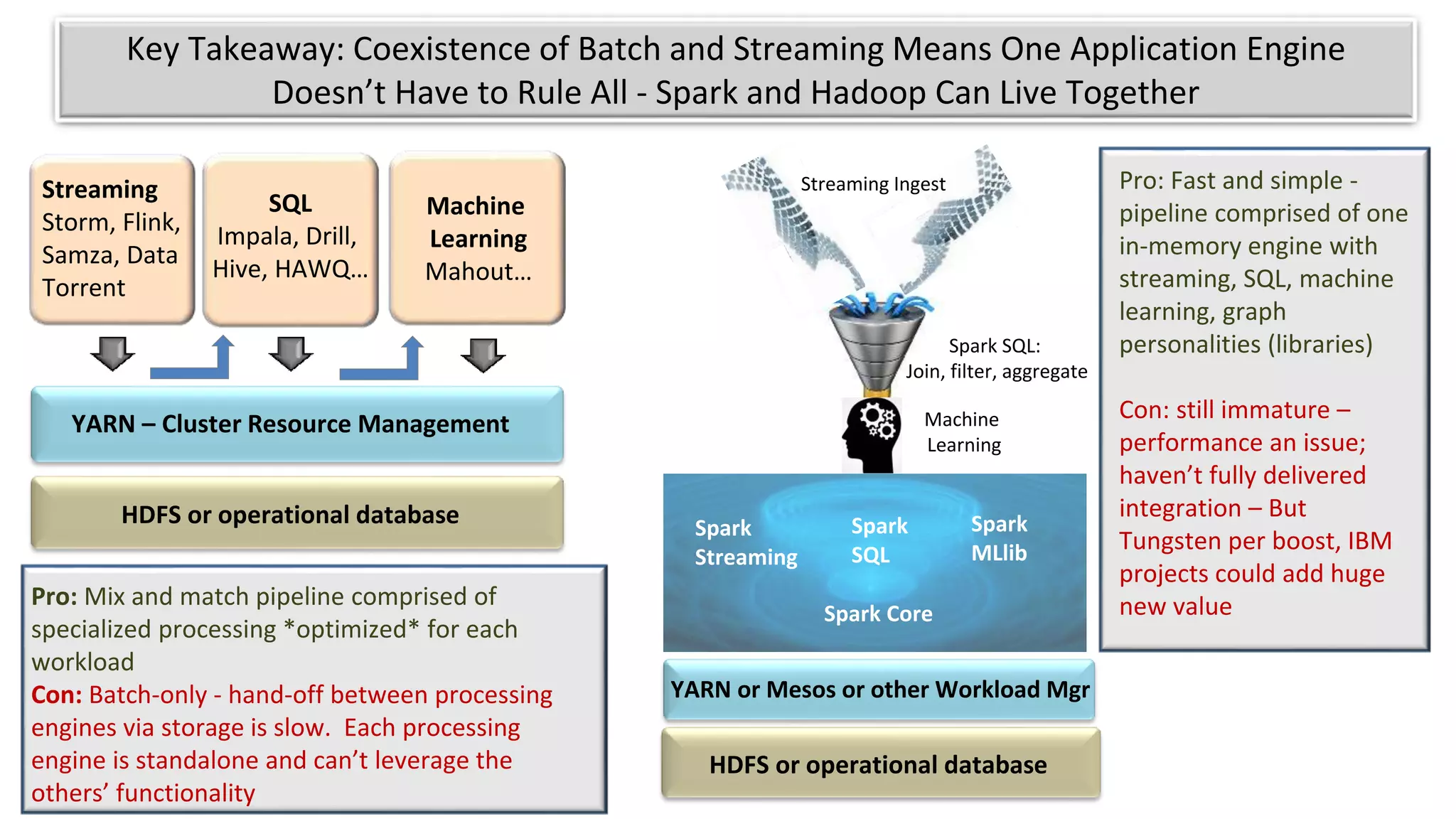

The document discusses the evolution of IoT systems and their integration with enterprise capabilities, emphasizing the shift from traditional telecom operations to intelligent service providers that utilize real-time data analytics. It outlines how predictive models, real-time updates, and advanced analytics enhance customer service, network performance, and operational efficiency. Additionally, it explores the trade-offs between speed and richness in data processing, highlighting the coexistence of batch processing and streaming analytics in modern applications.









































































