Downloaded 62 times










![Documents{ author : "roger",date : "Sat Jul 24 2010 19:47:11 GMT-0700 (PDT)", text : "Spirited Away",tags : [ "Tezuka", "Manga" ],comments : [ {author : "Fred",date : "Sat Jul 24 2010 20:51:03 GMT-0700 (PDT)",text : "Best Movie Ever” } ]}](https://image.slidesharecdn.com/scalingwithmongodb-110720123004-phpapp02/85/Scaling-with-mongo-db-SF-Mongo-User-Group-7-19-2011-11-320.jpg)

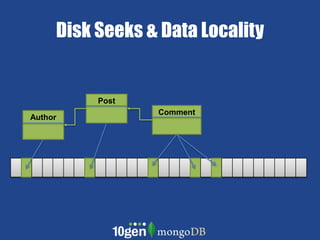


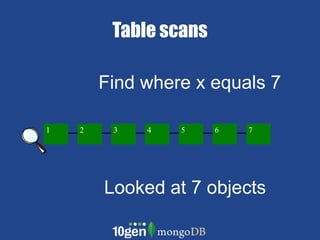

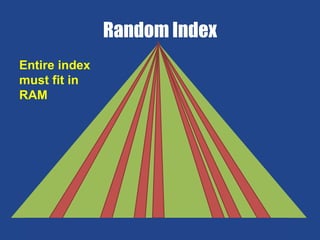

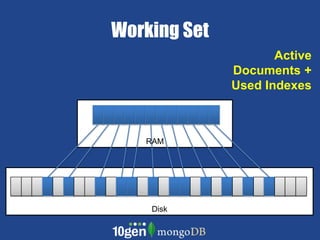
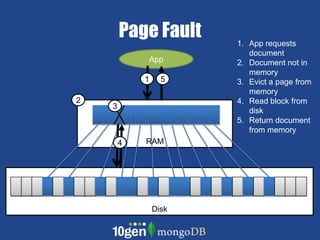



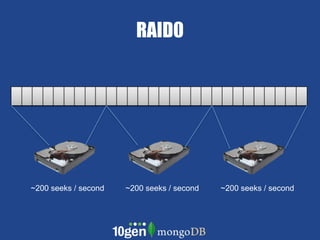
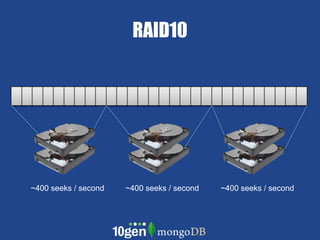

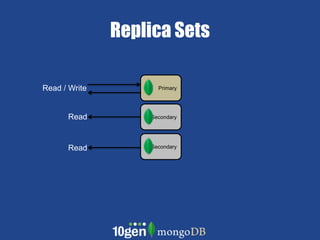
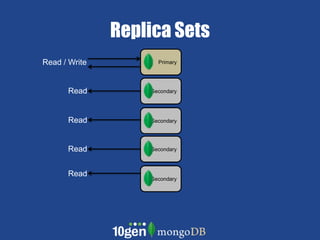

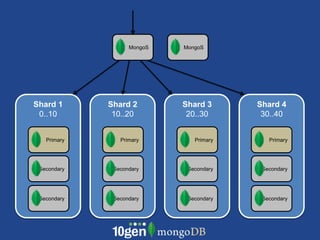

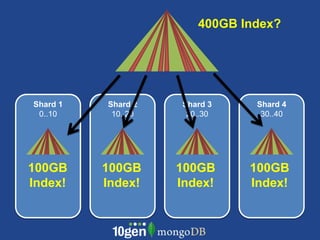



- MongoDB allows scaling by using documents, optimizing indexes, and understanding your working data set size. - Replica sets can scale reads by adding secondary nodes for load balancing, while sharding scales writes and RAM usage by splitting data across multiple shards. - Proper disk configuration and replication are important to maximize performance when scaling with MongoDB.
























































