The document discusses using machine learning algorithms and text mining of financial news headlines to predict stock market changes. It tests various algorithms, including Bayesian classifiers and support vector machines, on headline data from seven companies. The Bayesian classifier achieved the best results but prediction accuracy remained below 50%. While sophisticated models may eventually outperform by better understanding language, current methods cannot easily match human-level analysis of headlines. With continued improvement in algorithms and data mining, prediction accuracy may increase in the future.
Stock Market Prediction
UsingData Mining
By
Shivakumar Soppannavar
CMPE 239
Under the Guidance of
Prof. Eirinaki Magdalini
11/10/2015
2.
Different machine learningalgorithms are used to predict the stock market trading.
Use text from different sources and use Text and Data Mining (TDM) to extract pattern or
information or any hidden data of interest to predict the Ups and downs of the targeted
stocks.
Then
Data Mining Isn't a Good Bet For Stock-Market Predictions [2]
Aug. 8, 2009 - JASON ZWEIG , Wall Street Journal
Now
How Traders Are Using Text and Data Mining to Beat the Market [3]
Feb 12 2015 - Market Roy Kaufman , The Street
Applying Machine Learning to Stock Market Trading - Bryce Taylor [1]
Machine learning algorithm to read headlines from financial news magazines and
make predictions on the directional change of stock prices after a moderate-length
time interval
[Stanford Student project 2013, CS 229]
Introduction
3.
Data Sources andResearch question
Twitter data to predict stock market changes
Change in management, M&A
Intermittent headlines to react to the first headlines up or down ???
Data sources:
Headlines from financial analysts
http://seekingalpha.com/
Historic stock prices
http://www.nasdaq.com/
7 targeted companies
IBM, NFLX, GOOG, ANF, MCD, SHLD, AAPL
Research Questions:
“Given a headline released today about some company X, will the stock price of X
rise by more than P percent over the next time period T?”
T= 3 months
4.
Bayesian Classifiers
Bayesian Classifier
Simple multinomial Bayesian classifier that analyze the headlines based on the
presence of each token in the headline
51202 tokens -> Laplace smoothening -> 693 tokens -> Top 10 tokens
Classification Error for Reduced features < 0.5
Precision/Recall
Increase in P increases the Positive error and decrease in Negative error
Support Vector Machines
SVM (Polynomial, linear, etc) was used on reduced data set, didn’t beat the
result obtained from Bayesian classifier
5.
Naïve Baye’s TestingError
Table 1: Bayesian classifier result
run for top 10 most indicative
symbols
6.
Few more waysof analysis!
Natural Language Processing
Stanford has a publicly available Natural Language Processing Toolkit that
provides sentiment analysis to sentences with high accuracy (>80%)
Use of NLP didn’t achieve high success
Natural language processors would need to be specifically tailored to processing
headline-like data to be able to make a meaningful contribution towards
answering my research questions.
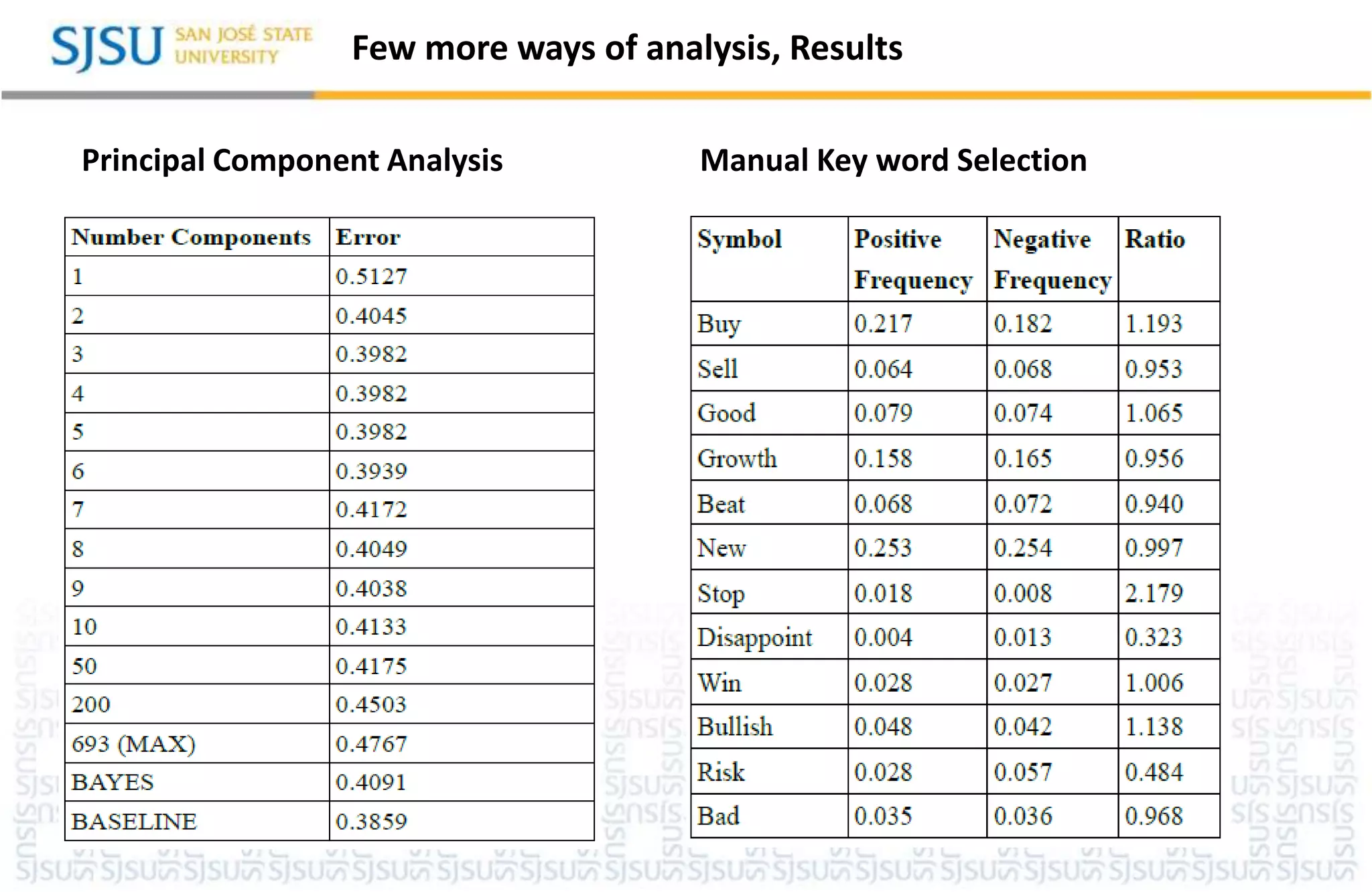
Principal Component Analysis
Principal component analysis are run on the data and then tested linear SVMs on
several of the top principal components.
Manual Key word Selection
Keywords are selected manually
7.
Few more waysof analysis, Results
Principal Component Analysis Manual Key word Selection
8.
Conclusion
Sophisticated model ableto beat overall market trends by reading financial news
headlines cannot be easily found without fairly sophisticated human-like processing
of the headlines. –By Author
Examples:
Tweet on Credit card breach at Home Depot (HD) -> Stocks 2% down. (9/2/2014) [3]
Nate Silver's uncannily accurate predictions of the U.S. national elections. (2012) [3]
Yes, by using Text and Data Mining and superior algorithms in near future, we may be
able to predict the stock market with greater accuracy.
References
1. B. Taylor.(2013). “Applying Machine Learning to Stock Market Trading”. Retrieved from
Stanford CS229 project lists 2013.
http://cs229.stanford.edu/proj2013/Taylor-
Applying%20Machine%20Learning%20to%20Stock%20Market%20Trading.pdf
2. JASON ZWEIG , (Aug. 8, 2009). Retrieved from Wall Street Journal website
http://www.wsj.com/articles/SB124967937642715417
3. M. R. Kaufman,(Feb 12 2015). Retrieved from The Street website
http://www.thestreet.com/story/13044694/2/how-traders-are-using-text-and-data-
mining-to-beat-the-market.html
4. http://cs229.stanford.edu/projects2013.html
Editor's Notes
#3 Text mining is the data analysis of natural language works (articles, books, etc.), using text as a form of data. It is often joined with data mining, the numeric analysis of data works (like filings and reports), and referred to as "text and data mining" or, simply, "TDM.“ [3]
#5 https://en.wikipedia.org/wiki/Laplacian_smoothing
Support vector machines (SVMs) are supervised learning models with associated learning algorithms that analyze data and recognize patterns, used for classification and regression analysis.

![Different machine learning algorithms are used to predict the stock market trading.
Use text from different sources and use Text and Data Mining (TDM) to extract pattern or
information or any hidden data of interest to predict the Ups and downs of the targeted
stocks.
Then
Data Mining Isn't a Good Bet For Stock-Market Predictions [2]
Aug. 8, 2009 - JASON ZWEIG , Wall Street Journal
Now
How Traders Are Using Text and Data Mining to Beat the Market [3]
Feb 12 2015 - Market Roy Kaufman , The Street
Applying Machine Learning to Stock Market Trading - Bryce Taylor [1]
Machine learning algorithm to read headlines from financial news magazines and
make predictions on the directional change of stock prices after a moderate-length
time interval
[Stanford Student project 2013, CS 229]
Introduction](https://image.slidesharecdn.com/stockmarketpredictionusingdatamining-shivakumar-soppanavar-151110225342-lva1-app6892/75/Stock-market-prediction-using-data-mining-2-2048.jpg)




![Conclusion
Sophisticated model able to beat overall market trends by reading financial news
headlines cannot be easily found without fairly sophisticated human-like processing
of the headlines. –By Author
Examples:
Tweet on Credit card breach at Home Depot (HD) -> Stocks 2% down. (9/2/2014) [3]
Nate Silver's uncannily accurate predictions of the U.S. national elections. (2012) [3]
Yes, by using Text and Data Mining and superior algorithms in near future, we may be
able to predict the stock market with greater accuracy.](https://image.slidesharecdn.com/stockmarketpredictionusingdatamining-shivakumar-soppanavar-151110225342-lva1-app6892/75/Stock-market-prediction-using-data-mining-8-2048.jpg)






















































































