This document provides an overview of statistics used in meta-analysis. It discusses key concepts like odds ratios, relative risk, confidence intervals, heterogeneity, and fixed and random effects models. It also summarizes different types of meta-analyses including realist reviews, meta-narrative reviews, and network meta-analyses. Software for performing meta-analyses and potential pitfalls in systematic reviews are also briefly covered.












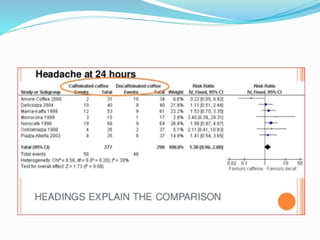
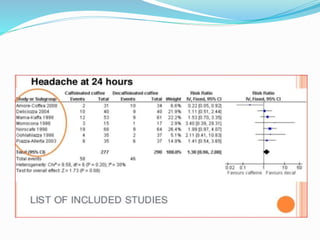
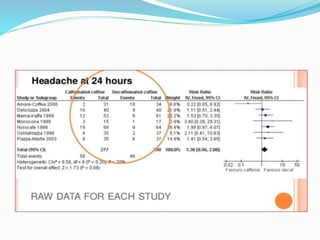
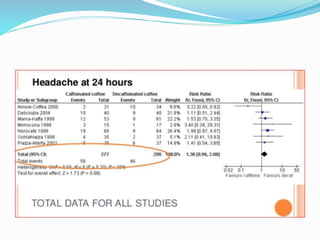
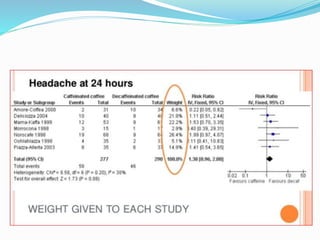
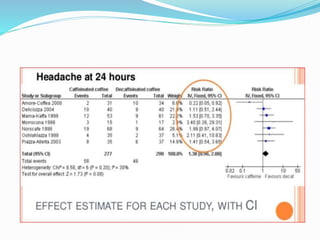
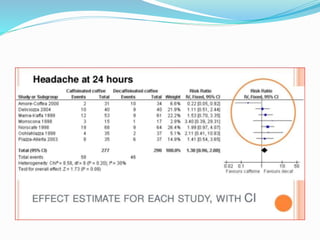
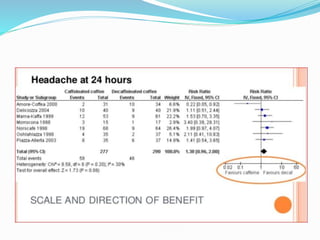
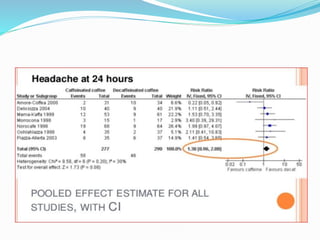






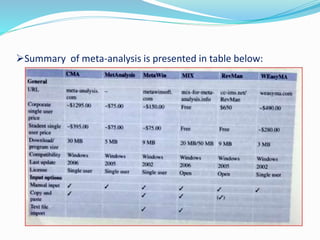








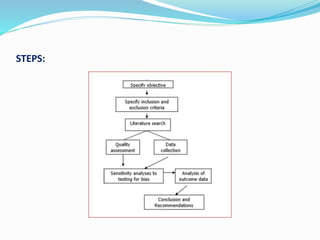



























































![ONFH[AVN HIP] -TRIPLE REGIME -A NOVAL SURGICAL CONCEPT .pptx](https://cdn.slidesharecdn.com/ss_thumbnails/onfhavnhip2026koaconcalicutdrgokuldevdrmashraf-260210064517-213ec005-thumbnail.jpg?width=640&height=640&fit=bounds)

















