Download as PDF, PPTX










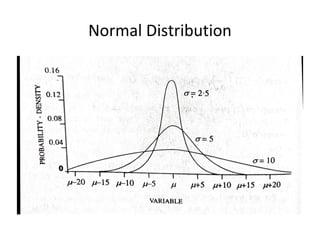
![Normal Distribution
• Most used form of distribution for a continuous
variable because
• – has very simple properties – comparatively easy to
deal with
• - many non-normal distributions become
asymptotically normal
• - transformation of variables often make them follow
normal distribution
• Central limit theorem and law of large numbers
• f(Y) = (1/(σ√2π) exp[-(Y-μ)2
/2σ2
], -∞ ≤Y ≤ +∞
• Mean(Y) = μ, Var(Y)= σ2](https://image.slidesharecdn.com/architaghoshstatisticalinferencehypothesistesting-240818045824-1186638c/85/Statistical-Inference-Hypothesis-Testing-pdf-10-320.jpg)


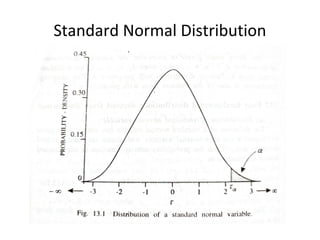
![Statistical Inference
Let us denote by τα,
a value of τ, such that
Pr[τ > τα
] = α
and Pr[τ < τ1-α
] = α
⇒ Pr[τ < τα
] = 1-α
For statistical inference value of α is normally
considered as 0.01 (99 per cent) or 0.05 (95 per cent)
and Pr[ -τα/2
< τ < τα/2
] = 1-α
The interval is defined as confidence limit and (1-α) is
confidence coefficient](https://image.slidesharecdn.com/architaghoshstatisticalinferencehypothesistesting-240818045824-1186638c/85/Statistical-Inference-Hypothesis-Testing-pdf-15-320.jpg)
![Interval estimation
• Constructing a range of values (interval) within which
the unknown parameter has a chance to belong
• If y is sample mean (samples being y1
, y2
, ......., yn
), it
can be shown that E(y) = μ, Var(y)= σ2
/n (sampling
with replacement)
• If y1
, y2
, ......., yn
follow normal distribution, y also
follows normal distribution
• Define τ = (y- μ)/ (σ/√n ), τ = [y- Mean(y)]/ √Var(y),
• τ follows standard normal distribution](https://image.slidesharecdn.com/architaghoshstatisticalinferencehypothesistesting-240818045824-1186638c/85/Statistical-Inference-Hypothesis-Testing-pdf-16-320.jpg)
![Interval estimation
99 per cent confidence interval of μ is
Pr [-2.576 ≤ (y- μ)/ (σ/√n ) ≤2.576] = 0.99
Pr [-2.576 (σ/√n ) ≤ (y- μ) ≤2.576 (σ/√n )] = 0.99
Pr [- y- 2.576 (σ/√n ) ≤ - μ ≤ -y +2.576 (σ/√n )] = 0.99
=> Pr [y- 2.576 (σ/√n ) ≤ μ ≤ y +2.576 (σ/√n )] = 0.99
=> In repeated sampling, in 99 per cent of the cases the
above interval will include μ (the probability that the
above interval will include μ is 0.99)](https://image.slidesharecdn.com/architaghoshstatisticalinferencehypothesistesting-240818045824-1186638c/85/Statistical-Inference-Hypothesis-Testing-pdf-17-320.jpg)



![t-distribution
• When σ is unknown, it is replaced by its sample
estimate.
• Then the ratio [(y-mean)/std. dev] follows
t-distribution
• The (1-α) percent confidence interval is
Pr [y- tα/2,n-1
(s’/√n ) ≤ μ ≤ y + tα/2,n-1
(s’/√n )] = 1-α](https://image.slidesharecdn.com/architaghoshstatisticalinferencehypothesistesting-240818045824-1186638c/85/Statistical-Inference-Hypothesis-Testing-pdf-21-320.jpg)


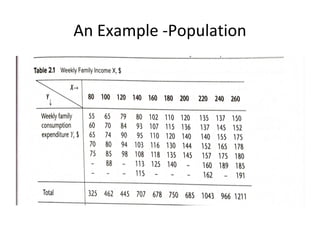
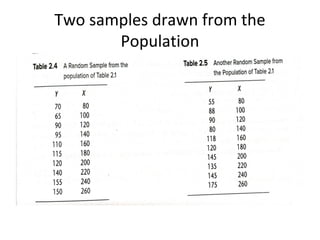
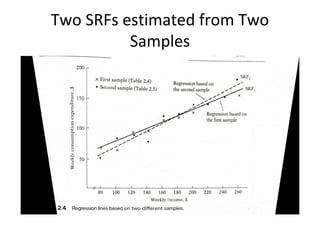




The document discusses statistical inference and hypothesis testing, illustrating how sample statistics can estimate population parameters and the methodologies for testing hypotheses. It covers concepts such as probability distributions, normal distributions, interval estimation, and hypothesis testing in various scenarios, including bivariate regression. The document emphasizes the importance of confidence intervals and significance levels in making statistical conclusions.






























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




