This document provides an overview of categorical data analysis techniques. It discusses categorical and quantitative variables, different types of categorical variables, and common distributions for categorical data like binomial and multinomial. Methods for categorical data like chi-square tests, logistic regression, and Poisson regression are presented. Examples are provided to illustrate hypothesis testing, confidence intervals, and likelihood ratio tests for categorical proportions.






![Example 1.4: Suppose proportions of individuals with genotypes AA, Aa, and aa in
a large population are (πAA , πAa, πaa) = (0.25, 0.5, 0.25): Randomly sample n = 5
individuals from the population. The chance of getting 2 AA’s, 2 Aa’s, and 1 aa is
R code
dmultinom(Y=c(y1,y2, , , , y𝑐), prob = c(π1,π2…,π𝑐))
dmultinom(x=c(2,2,1),prob = c(0.25,0.5,0.25))
[1] 0.1171875
dmultinom(x=c(0,3,2), prob = c(0.25,0.5,0.25))
[1] 0.078125
• If (Y1,Y2, , , , Y𝑐) has a multinomial distribution with n trials and category
probabilities (π1,π2…,π𝑐) then
E(Y𝑖) = nπ𝑐, for i= 1.2…..c
Var (Y𝑖) = n π (1 − nπ
Cov(Y𝑖, Y𝑗) = -π𝑖π𝑗](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-8-320.jpg)
![The Poisson distribution
• Poisson distribution is a discrete probability distribution, which is useful for
modeling the number of successes in a certain time, space.
Example 1.5: In a small city, 10 accidents took place in a time of 50 days. Find the
probability that there will be a) two accidents in a day and b) three or more
accidents in a day.
Solution: There are 0.2 accidents per day. Let X be the random variable, the number
of accidents per day
X ~poiss (𝜆 = 0.2) X = 0, 1, 2, ….
𝑃 (𝑋 = 2) =
(0.2)2𝑒−0.2
2!
= 0.0164
b) P (X ≥ 3) = P(X = 3) + P(X = 4) + P(X = 5) +...
= 1- [P(X = 0) + P(X = 1) + P(X = 2)] . . . . . . since
= 1- [0.8187 + 0.1637 + 0.0164] = 0.0012](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-9-320.jpg)

























![Thus, the Pearson chi-squared and likelihood-ratio statistics for independence,
respectively, are
𝑋2 = 𝑖=1
𝑟
𝑗=1
𝑐 (𝑛𝑖𝑗−µ𝑖𝑗)2
µ𝑖𝑗
~ 𝑋2 [(r-1) (c-1)] and
𝐺2
= 𝑖=1
𝑟
𝑗=1
𝑐
𝑛𝑖𝑗 log(
𝑛𝑖𝑗
µ𝑖𝑗
) ~ 𝑋2
[(r-1) (c-1)]
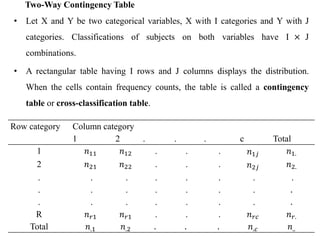
Example 2.3: The following cross classification shows the distribution of patients
by the survival outcome (active, dead, transferred to other hospital and loss-to-
follow) and gender. Test whether the survival outcome depends on gender or not
using both the Pearson and likelihood-ratio tests.
Gender Survival Outcome
Active Dead Transferred Loss-to-follow Total
Female 741 25 63 101 930
Male 392 20 52 70 534
Total 1133 45 115 171 1464](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-36-320.jpg)
![Solution: First let’s find the expected cell counts,
𝑛𝑖.𝑛.𝑗
𝑛
Gender Survival Outcome
Active Dead Transferred Loss-to-follow Total
Female 741 (719.7) 25 (28.6) 63 (73.1) 101 (108.6) 930
Male 392 (413.3) 20 (16.4) 52 (41.9) 70 (62.4) 534
Total 1133 45 115 171 1464
Thus, the Pearson chi-squared statistics is
𝑋2 = 𝑖=1
𝑟
𝑗=1
𝑐 (𝑛𝑖𝑗−µ𝑖𝑗)2
µ𝑖𝑗
=
(741−719.7)2
719.7
+
(25−28.6)2
28.6
+…+
(70−62.4)2
62.4
= = 8.2172
Since both statistics have larger values than 𝑋2 [(2-1) (4-1)] = 𝑋2
𝛼=0.05 (3), it can
be concluded that the survival outcome of patients depends on the gender.](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-37-320.jpg)




![The sample relative risk (rr) =
𝜋1/1
𝜋1/1
estimates the population relative risk (RR).
If the probability of successes are equal in the two groups being compared, then r = 1
or log(r) = 0 indicating no association between the variables. Thus, under H0: log(r)
= 0, for large values of n the test statistic:
Z=
log 𝑟 −log(𝑅𝑅)
𝑺𝑬[𝐥𝐨𝐠(𝐫)]
~N (0, 1)
Thus, the 100 (1-α) % confidence interval for log(r) is given by
[log (r)] ± 𝑧𝛼/2𝑆𝐸[log(r)].
Were, 𝑆𝐸[log(rr)]=
1
𝑛11
+
1
𝑛11
+
1
𝑛1.
+
1
𝑛2.
Taking the exponentials of the end points this confidence interval provides the
confidence interval for RR: exp{log (r) ± 𝑧𝛼/2𝑆𝐸[log(r)}.](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-43-320.jpg)
![Example 2.5: Consider the following table categorizing students by their academic
performance on a statistics course examination (pass or fail) to two different
teaching methods (teaching using slides or lecturing on the board). Find
a. The relative risk for the data and test its significance.
b. The 100 (1-α) % confidence interval
Teaching Methods Examination Result
Pass Fail Total
Slide 45 20 65
Lecturing 32 3 35
Total 77 23 100
The estimate of the relative risk is (rr) =
𝜋1/1
𝜋1/1
=
45∗35
32∗65
=
0.692
0.914
= 0.757,
Which implies log(r) = log(0.757) = -0.2784 and
𝑆𝐸[log(r)]=
1
45
+
1
32
+
1
65
+
1
35
= 0.0095 = 0.0975](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-44-320.jpg)
![Thus, the 100 (1-α) % confidence interval for log(r) is given by
[log (r)] ± 𝑧𝛼/2𝑆𝐸[log(r)].
(-0.2784 ± 1.96*0.0975) = (-0.2784 ± 0.1911)
= (-0.4695, -0.0873)
The value of confidence interval doesn’t include 1. Therefore, the relative risk is
significantly different from 1.
Thus, it can be concluded that the proportion of passing in the slide group is 0.757
times that of the lecturing group.
Or by inverting, the probability of passing in the lecturing group is 𝑒0.32
= 1.377
times that of the slide teaching method group.](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-45-320.jpg)





![ For the population, a 95% confidence interval for log θ equals
0.605 ± 1.96(0.123), or (0.365, 0.846).
The corresponding confidence interval for θ is [exp(0.365),
exp(0.846)] = (e0.365, e0.846) = (1.44, 2.33).
Since the confidence interval (1.44, 2.33) for θ does not contain
1.0, the true odds of MI seem different for the two groups.
We estimate that the odds of MI are at least 44% higher for
subjects taking placebo than for subjects taking aspirin.](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-51-320.jpg)








![Therefore, we apply the logit transformation where the transformed quantity lies in
the interval from minus infinity to positive infinity and it is modeled as
The logit (πi) = log (
𝛑𝐢
𝟏−𝛑𝐢
) = 𝐳 = 𝛂 + 𝛃𝟏𝐱𝟏 + 𝛃𝟐𝐱𝟐 + ⋯ . +𝛃𝐤𝐱𝐤.................. 3.3
The Logit Transformation
The logit of the probability of success is given by the natural logarithm of the odds
of successes.
Therefore, the logit of the probability of success is a linear function of the
explanatory variable.
Thus, the simple logistic model is logit (π(𝑋𝑖)) = Log [
π(𝑋𝑖)
1−π(𝑋𝑖)
] = α + βxi
The probit model or the complementary log-log model might be appropriate when
the logit model does not fit the data well.](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-60-320.jpg)
![The link function
Function form Typical application
Logit Log [
π(𝑋𝑖)
1−π(𝑋𝑖)
] Evenly distributed categories
Complementary log-log Log [-Log (1-
π(𝑋𝑖))]
Higher categories are more
probable
Negative log-log -Log π(𝑋𝑖) Lower categories are more
probable
Probit 𝜙−1
[π(𝑋𝑖)] Normally distributed latent
variable](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-61-320.jpg)
![Interpretation of the Parameters
The logit model is monotone depending on the sign of β.
Its sign determines whether the probability of success is increasing or decreasing as
the value of the explanatory variable increases.
Thus, the sign of β indicates whether the curve is increasing or decreasing. When β
is zero, Y is independent of X.
Then, π(xi) =
exp(α)
1+exp(α)
, is identical for all xi, so the curve becomes a straight line.
The parameters of the logit model can be interpreted in terms of odds ratios.
From logit [π(xi)] = α + βxi, an odds is an exponential function of xi. This provides a
basic interpretation for the magnitude of β.](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-62-320.jpg)
![ If odds = 1, then a success is as likely as a failure at the particular value 𝒙𝒊 of the
explanatory variable.
If odds > 1) log [odds] > 0, a success is more likely to occur than a failure.
On the other hand, if odds < 1, log [odds] < 0, a success is less likely than a
failure.
Thus, the odds ratio is
𝑜𝑑𝑑𝑠(xi+1)
𝑜𝑑𝑑𝑠(xi)
= exp(β) This value is the multiplicative effect of
the odds of successes due to a unit change in the explanatory variable.
The intercept α is, not usually of particular interest, used to obtain the odds at xi= 0.](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-63-320.jpg)

![The analysis also done using R statistical software, the following parameter estimates were
obtained.
Coefficients:
Estimate Std. Error z value exp(β) Pr(>|z|)
(Intercept) -3.44413 0.64171 -5.367 0.03193 8.0e-08 ***
Age 0.05692 0.01253 4.541 1.0568 5.6e-06 ***
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1
Let Y = TB and X= age. Then 𝜋(xi)= 𝑝 (Y = 1/xi) is the estimated probability of
having TB, Y = 1, given the age xi of an individual i.
a. π(xi) =
𝑒(−3.44413 +0.05692 age)
1+𝑒(−3.44413 +0.05692) Also, the estimated logit model is written as
Logit [𝜋(xi)]= log[
𝜋(xi)
1−𝜋(xi)
] = −3.44413 + 0.05692 age
b. The probability of having pneumonia at the age of 35 years is
𝜋 (35)=
𝑒(−3.44413 +0.05692(35))
1+𝑒(−3.44413 +0.05692(35)) =
0.0338
1.0338
= 0.0327 and its odds =
𝑒(−2.844+0.05692 age)= 0.0338](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-65-320.jpg)
![c. The odds (risk) of having TB is exp(𝛽) = exp(0.05692) = 1.0568 times larger
for every year older an individual. In other words, as the age of an individual
increases by one year, the odds (risk) of developing TB increases by a factor of
1.0568. Or it can be said the odds (risk) of having pneumonia increases by [exp
(0.05692) - 1] × 100% = 5.6%.
d. The median effective level, the age at which an individual has a 50% chance of
having pneumonia, is EL50 =
−𝛼
𝛽
=
−(−3.44413)
0.05692
= 60.508 years.
e. The probability of having TB at the mean age of 35 years that the mean given
as βπ(xi)[1- π(xi)] = 0.0327(1-0.0327) 0.05692 = 0.0018](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-66-320.jpg)



![Multiple Logistic Regressions
Suppose there are k explanatory variables (categorical, continuous or both) to be
considered simultaneously.
𝐳𝐢= 𝛃𝟎 + 𝛃𝟏𝐱𝐢𝟏 + 𝛃𝟐𝐱𝐢𝟐 + …+ 𝛃𝐩𝐱𝐢𝐤.
Consequently, the logistic probability of success for subject i given the values of the
explanatory variables
𝐱𝐢 = (𝐱𝐢𝟏, 𝐱𝐢𝟐, …, 𝐱𝐢𝐤) is π (𝐱𝐢) =
𝟏
𝟏+𝐞𝐱𝐩[−(𝛃𝟎 + 𝛃𝟏𝐱𝐢𝟏 + 𝛃𝟐𝐱𝐢𝟐 + …+ 𝛃𝐩𝐱𝐢𝐤 )]
, where
π (𝒙𝒊) =p (𝒀𝒊=1/𝒙𝒊𝟏, 𝒙𝒊𝟐, …, 𝒙𝒊𝒌)= logit [π (𝒙𝒊)] = log (
𝛑 (𝒙𝒊)
𝟏− 𝛑 (𝒙𝒊)
) = 𝜷𝟎 + 𝜷𝟏𝒙𝒊𝟏 +
𝜷𝟐𝒙𝒊𝟐 + …+ 𝜷𝒑𝒙𝒊𝒌
Similar to the simple logistic regression, exp(𝛽𝑖) represents the odds ratio associated
with an exposure if 𝑥𝑗 is binary (exposed 𝑥𝑖𝑗 = 1 versus unexposed 𝑥𝑖𝑗 = 0); or it is the
odds ratio due to a unit increase if 𝑥𝑗 is continuous (𝑥𝑖𝑗 = 𝑥𝑖𝑗 + 1 versus 𝑥𝑖𝑗 = 𝑥𝑖𝑗).](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-70-320.jpg)

![Inference for Logistic Regression
Parameter Estimation
The goal of logistic regression model is to estimate the k + 1 unknown parameters
of the model. This is done with maximum likelihood estimation which entails
finding the set of parameters for which the probability of the observed data is
largest.
Then each binary response Yi, i = 1, 2, …, m has an independent Binomial
distribution with parameter ni and π(xi), that is,
P (𝐘𝐢 =𝐘𝐢) =
𝐧𝐢!
(𝐧𝐢−𝐲𝐢)! 𝐲𝐢!
[𝛑(𝐱𝐢)]𝐲𝐢 [𝟏 − 𝛑(𝐱𝐢)]𝐧𝐢−𝐲𝐢, 𝐲𝐢 = 1,2,…, 𝐧𝐢 …..3.6
Where, 𝑥𝑖 = (𝑥𝑖1, 𝑥𝑖2, …, 𝑥𝑖𝑘) for population i
Then, the joint probability mass function of the vector of m Binomial random
variables, 𝑌𝑖 = (𝑌1, 𝑌2, …, 𝑌𝑚), is the product of the m Binomial distributions:](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-72-320.jpg)
![P (y/β) = 𝑖=1
𝑚 𝑛𝑖!
(𝑛𝑖−𝑦𝑖)! 𝑦𝑖!
[π(xi)]𝑦𝑖 [1 − π(xi)]𝑛𝑖−𝑦𝑖 ……..3.7
The likelihood function has the same form as the probability mass function, except
that it expresses the values of β in terms of known, fixed values for y. Thus,
ʟ (β/y) = 𝑖=1
𝑚 𝑛𝑖!
(𝑛𝑖−𝑦𝑖)! 𝑦𝑖!
[π(xi)]𝑦𝑖 [1 − π(xi)]𝑛𝑖−𝑦𝑖 …….3.8
maximizing the equation without the factorial terms will come to the same result as
if they were included. Therefore, equation (3.7) can be written as:
ʟ (β/y) = 𝑖=1
𝑚
[π(xi)]𝑦𝑖 [1 − π(xi)]𝑛𝑖−𝑦𝑖 , and it can be re-arranged as:
ʟ (β/y) = 𝒊=𝟏
𝒎
[
𝛑(𝐱𝐢)
𝟏−𝛑(𝐱𝐢)
]𝒚𝒊 [𝟏 − 𝛑(𝐱𝐢)]𝒏𝒊 …………….............. 3.8
By substituting the odds of successes and probability of failure in equation (3.8),
the likelihood function becomes
ʟ (β/y) = 𝒊=𝟏
𝒎
[𝐞𝐱𝐩(𝒚𝒊 𝒋=𝟏
𝒌
𝛃𝒋 𝒙𝒊𝒋)] [𝟏 + 𝐞𝐱𝐩( 𝒋=𝟏
𝒌
𝛃𝒋 𝒙𝒊𝒋)]−𝒏𝒊 ............ 3.9](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-73-320.jpg)
![Thus, taking the natural logarithm of equation (3.9) gives the log-likelihood
function:
ʟ (β/y) = 𝐢=𝟏
𝐦
𝒚𝒊 𝒋=𝟏
𝒌
𝜷𝒋 𝒙𝒊𝒋 −𝒏𝒊 𝐥𝐨𝐠[𝟏 + 𝐞𝐱𝐩 𝒋=𝟏
𝒌
𝛃𝒋 𝒙𝒊𝒋 ]..... 3.10
To find the critical points of the log-likelihood function, first, equation (3.9) should
be partially differentiated with respect to each 𝛽𝑗, j = 0, 1, … k
Əʟ (β/y)
Ə𝜷𝒋
= 𝒊=𝟏
𝒎
[𝒚𝒋 𝒙𝒊𝒋 - 𝒏𝒊𝝅𝒊(𝒙𝒊) 𝒙𝒊𝒋]= 𝒊=𝟏
𝒎
[𝒚𝒋- 𝒏𝒊𝝅𝒊(𝒙𝒊) ]𝒙𝒊𝒋 , j= 0, 1, 2, …, k…...3.11
Since the second partial derivatives of the log-likelihood function:
Ə2ʟ (β/y)
Ə𝜷𝒋Ə𝜷𝒉
= - 𝒊=𝟏
𝒎
𝒏𝒊𝝅𝒊(𝒙𝒊) [1- 𝝅𝒊(𝒙𝒊)] 𝒙𝒊𝒋𝒙𝒊𝒉 , j,h= 0,1,2,…, k…………….3.22](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-74-320.jpg)





![Confidence Intervals
Confidence intervals are more informative than tests. A confidence interval for 𝛽𝑗
results from inverting a test of H0: 𝛽𝑗 = 𝛽𝑗0.
The interval is the set of 𝛽𝑗0's for which the z test statistic is not greater than 𝛽Ə/2.
For the Wald approach, this means
𝛽𝑗−𝛽𝑗0
𝑆𝐸(𝛽𝑗)
≤ 𝑧Ə/2
This yields the confidence interval 𝛽𝑗 ± 𝑧Ə/2SE(𝛽𝑗) 𝛽𝑗, j= 1, 2, . . ., k. As the
point estimate of the odds ratio associated to 𝑋𝑗 is exp (𝛽𝑗) and its confidence
interval is exp[𝛽𝑗 ± 𝑧Ə/2SE(𝛽𝑗)].](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-80-320.jpg)




![The McFadden 𝑹𝟐
Since the saturated model has a parameter for each subject, the log𝐿𝑠 approaches to
zero. Thus, log𝐿𝑠 = 0 simplifies
𝑅2
McFadden=
𝐿𝑜𝑔𝐿𝑚−Log𝐿0
−Log𝐿0
= 1- [
𝐿𝑜𝑔𝐿𝑚
Log𝐿0
]
The Cox & Snell 𝑹𝟐
The Cox & Snell modified 𝑅2 is:
𝑅2
Cox−Snell = 1-
𝐿0
𝐿𝑚
2/𝑛
= 1- exp(Log𝐿0 − 𝐿𝑜𝑔𝐿𝑚) 2/𝑛
The Nagelkerke 𝑹𝟐
Because the 𝑅2
Cox−Snell value cannot reach 1, Nagelkerke modified
it. The correction increases the Cox & Snell version to make 1 a
possible value for 𝑅2
.
𝑅2
Nagelkerke =
1−
𝐿0
𝐿𝑚
2/𝑛
1−(𝐿0)2/𝑛 =
1−(exp(Log𝐿0−𝐿𝑜𝑔𝐿𝑚))2/𝑛
1−[exp(𝐿0)]2/𝑛](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-85-320.jpg)

![• Pearson Chi-squared Statistic
Suppose the observed responses are grouped into m covariate patterns
(populations). Then, the raw residual is the difference between the observed
number of successes 𝑦𝑖 and expected number of successes 𝑛𝑖π (𝑥𝑖) for each value
of the covariate 𝑥𝑖. The Pearson residual is the standardized difference. That is,
𝑟𝑖 =
𝑦𝑖−𝑛𝑖 𝜋 (𝑥𝑖)
𝑛𝑖 𝜋 𝑥𝑖 [1−𝜋 (𝑥𝑖)]
~ 𝑥2
(m-k)
• When this statistic is close to zero, it indicates a good model fit to the data.
When it is large, it is an indication of lack of fit. Often the Pearson residuals 𝑟𝑖
are used to determine exactly where the lack of fit occurs.](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-87-320.jpg)
![The Deviance Function
The deviance, like the Pearson chi-squared, is used to test the adequacy of the
logistic model. As shown before, the maximum likelihood estimates of the
parameters of the logistic regression are estimated iteratively by maximizing the
Binomial likelihood function.
The deviance is given by:
D = 2 𝑖=1
𝑚
𝑦𝑖 log
𝑦𝑖
𝑛𝑖π 𝑥𝑖
+ (𝑛𝑖 − 𝑦𝑖)𝑙𝑜𝑔
𝑛𝑖−𝑦𝑖
𝑛𝑖−𝑛𝑖π 𝑥𝑖
~ 𝑥2(m-k)
Where the fitted probabilities π 𝑥𝑖 satisfy logit [π 𝑥𝑖 ] = 𝑖
𝑘
𝛽𝑗 𝑥𝑖𝑗 and 𝑥𝑖0=1.
The deviance is small when the model fits the data, that is, when the observed
and fitted proportions are close together. Large values of D (small p-values)
indicate that the observed and fitted proportions are far apart, which suggests
that the model is not good.](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-88-320.jpg)










![Cumulative Logit Models
With the above categorization of 𝑌𝑖, P(𝑌𝑖 ≤ j) is the cumulative probability that Yi
falls at or below category j. That is, for outcome j, the cumulative probability is:
P(𝑌𝑖 ≤ j/𝑥𝑖 ) = 𝜋1(𝑥𝑖) + 𝜋2(𝑥𝑖), . . . , 𝜋𝑗(𝑥𝑖) , j = 1, 2, . . . ,J
Thus, the cumulative logit of P(𝑌𝑖 ≤ j) (log odds of outcomes ≤ J) is:
Logit P(𝑌𝑖 ≤ j) = log
P(𝑌𝑖 ≤ j)
1−P(𝑌𝑖 ≤ j)
= log
P(𝑌𝑖 ≤ j)
1−P(𝑌𝑖> j)
= log
𝜋1(𝑥𝑖) + 𝜋2(𝑥𝑖),...,𝜋𝑗(𝑥𝑖)
𝜋𝑗+1(𝑥𝑖) + 𝜋𝑗+2(𝑥𝑖),...,𝜋𝐽(𝑥𝑖)
, j = 1, 2, . . . , J-1
Each cumulative logit model uses all the J response categories. A model for logit
[P(𝑌𝑖 ≤ j/𝑥𝑖)] alone is an ordinary logit model for a binary response in which
categories from 1 to j form one outcome and categories from j + 1 to J form the
second.](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-99-320.jpg)
![Proportional Odds Model
A model that simultaneously uses all cumulative logits is
logit [P(𝑌𝑖 ≤ j/𝑥𝑖)] = 𝛽𝑗0 + 𝛽𝑗1 𝑥𝑖1 + 𝛽𝑗2 𝑥𝑖2 + . . . + 𝛽𝑗𝑘 𝑥𝑖𝑘 , j = 1, 2, . . . , J-1
Each cumulative logit has its own intercept but the same effect (its associated
odds ratio called cumulative odds ratio) associated with the explanatory variables.
Each intercept increases in j
since logit [P(𝑌𝑖 ≤ j/𝑥𝑖)] increases in j for a fixed 𝑥𝑖, and the logit is an increasing
function of this probability.](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-100-320.jpg)
![An ordinal logit model has a proportionality assumption which means the distance
between each category is equivalent (proportional odds).
That is, the cumulative logit model satisfies
logit [P(𝑌𝑖 ≤ j/𝑥𝑖𝑝1)] - logit [P(𝑌𝑖 ≤ j/𝑥𝑖𝑝2)] = 𝛽𝑝 (𝑥𝑝1-𝑥𝑝2)
The odds of making response ≤ j at 𝑋𝑝 = 𝑥𝑝1 are exp [𝛽𝑝 (𝑥𝑖𝑝1-𝑥𝑖𝑝2) times the odds at
𝑋𝑝 = 𝑥𝑝2.
The log odds ratio is proportional to the distance between 𝑥𝑝1 and 𝑥𝑝2 with a single
predictor, the cumulative odds ratio equals exp (𝛽) whenever 𝑥1 - 𝑥2 = 1.](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-101-320.jpg)
![Cumulative Response Probabilities
The cumulative response probabilities of an ordinal logit model, is determined
similar to the multinomial response probabilities.
[P(𝑌𝑖 ≤ j/𝑥𝑖𝑝1)] =
exp(𝛽𝑗0 + 𝛽𝑗1 𝑥𝑖1 + 𝛽𝑗2 𝑥𝑖2 + ...+ 𝛽𝑗𝑘 𝑥𝑖𝑘)
1+ exp(𝛽𝑗0 + 𝛽𝑗1 𝑥𝑖1 + 𝛽𝑗2 𝑥𝑖2 + ...+ 𝛽𝑗𝑘 𝑥𝑖𝑘)
, j = 1, 2, . . . ,J-1
Hence, an ordinal logit model estimates the cumulative probability of being in one
category versus all lower or higher categories.
Example 5.3: To determine the effect of Age and residence (0= urban, 1=rural) on
the NYHA class of heart failure patients (0= class I, 1= class II, 2= class III and 4=
class IV), the following parameter estimates of ordinal logistic regression are
obtained. Obtain the cumulative logit model and interpret. Also find the estimated
probabilities of each clinical stage for a female patient at the mean age 40 years.](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-102-320.jpg)

![The cumulative ordinal logit model can be written as
logit [P(𝑌𝑖 ≤ j/𝑥𝑖)] = 𝛽𝑗0 + 𝛽𝑗1 𝑥𝑖1 + 𝛽𝑗2 𝑥𝑖2 + . . . + 𝛽𝑗𝑘 𝑥𝑖𝑘 , j = 1, 2, 3
logit [P(𝑌𝑖 ≤ j/𝑥𝑖)] = logit [
𝜋1
𝜋2+𝜋3+𝜋4
] = 0.419 - 0.747 Urban + 0.0343 Age
logit [P(𝑌𝑖 ≤ j/𝑥𝑖)] = logit [
𝜋1
𝜋2+𝜋3+𝜋4
] = 2.264 - 0.747 Urban + 0.0343 Age
logit [P(𝑌𝑖 ≤ j/𝑥𝑖)] = logit [
𝜋1
𝜋2+𝜋3+𝜋4
] = 3.279 - 0.747 Urban + 0.0343 Age
The value of 0.419, labeled Intercept for NYHA class, is the estimated log odds of
falling into category 1 (class I) versus all other categories when all predictors are
zero.
Thus, the estimated log odds of NYHA class I, when age of patient at base line and
all predictors at the reference level is exp (0.419) = 1.520.](https://image.slidesharecdn.com/cdappt-240312112152-4564d140/85/Categorical-data-analysis-full-lecture-note-PPT-pptx-104-320.jpg)



































































































