Downloaded 20 times


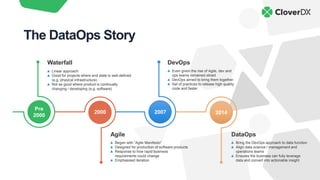
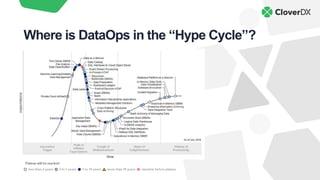
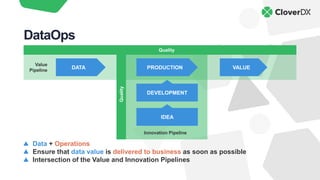

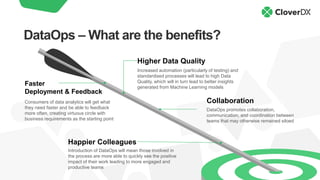


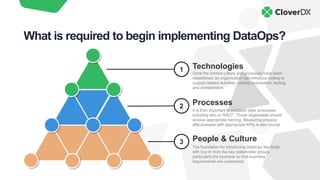

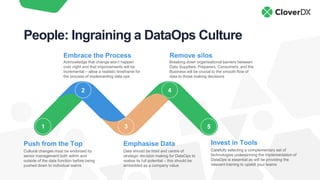
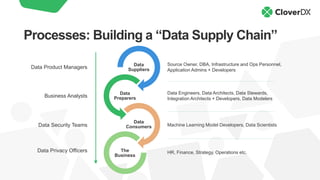



The document discusses DataOps as an evolution of Agile and DevOps, aimed at improving collaboration between data teams and the broader business to enhance data utilization for actionable insights. It outlines the benefits and principles of DataOps, emphasizing the importance of processes, people, culture, and technology in its implementation. Additionally, it provides a case study of Facebook's DataOps journey and highlights essential techniques for successful DataOps delivery.






































![[DSC Europe 24] Josip Saban - Buidling cloud data platforms in enterprises](https://cdn.slidesharecdn.com/ss_thumbnails/josipsaban-buidlingclouddataplatformsinenterprises-250217194546-5568421d-thumbnail.jpg?width=640&height=640&fit=bounds)










































