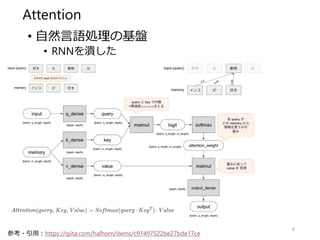
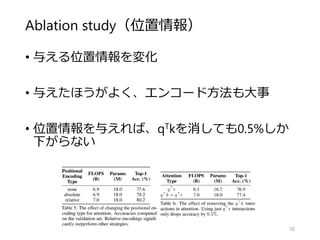
Stand-Alone Self-Attention inVision
2019/10/03
神戸瑞樹
Prajit Ramachandran∗ Niki Parmar∗ Ashish Vaswani∗
Irwan Bello Anselm Levskaya† Jonathon Shlens
Google Research, Brain Team
{prajit, nikip, avaswani}@google.com
https://arxiv.org/pdf/1906.05909.pdf
∗Denotes equal contribution. Ordering determined by random shuffle.
†Work done as a member of the Google AI Residency Program

















![[DeepLearning論文読み会] Dataset Distillation](https://cdn.slidesharecdn.com/ss_thumbnails/datasetdistillation-181114165952-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]DropBlock: A regularization method for convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/dlyokota20190222-190222002832-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Attention Is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks170714-170714005330-thumbnail.jpg?width=640&height=640&fit=bounds)
























