More Related Content

PDF

DOC

PDF
การประเมินการอ่าน คิดวิเคราะห์ และเขียน 
PPT

PDF

PDF
การเปลี่ยนแปลงพลังงานและการเกิดปฏิกิริยาเคมี 
PDF

PDF
สมบัติบางประการของสารละลาย What's hot

PDF

PDF
ใบงานที่ 8-1 คุณธรรม จริยธรรมในการใช้เทคโนโลยีสารสนเทศ 
PDF
หน่วยการเรียนรู้ที่ 4 เรื่อง วิวัฒนาการ 
PDF
แรงและการเปลี่ยนแปลงโมเมนตัม 
DOC

PDF

PDF
ใบกิจกรรมที่ 2 เรื่อง กล้องจุลทรรศน์ 
PDF
วิจัยในชั้นเรียนวิจัยในชั้นเรียนชั้นม.2 
PDF

PDF
Going shopping presentation aj.rey 
PDF
อ่านบทความวิจัยไม่ยากอย่างที่คิด 3 
PDF

PDF

PDF

PDF

PDF
6แบบทดสอบการลำเลียงสารผ่านเซลล์ 
PDF

PDF

PPTX

PDF
Viewers also liked

PDF

PDF

PDF
เครื่องมือที่ใช้ในการวิจัย 
PPT

PDF

PPTX

PDF
12. บทที่ 4 ผลการวิเคราะห์ข้อมูล ![[สรุปสูตร] สรุปสูตรคณิตศาสตร์พื้นฐาน ม456 1](https://cdn.slidesharecdn.com/ss_thumbnails/456-1-130802015611-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[สรุปสูตร] สรุปสูตรคณิตศาสตร์พื้นฐาน ม456 1 Similar to สูตรสถิติ

PPT

DOC

DOCX

PPT
สื่อการสอนวิชาคณิตศาสตร์ลองทำ 
PPT
การวิเคราะห์ข้อมูลเชิงปริมาณ 
PDF
การวิเคราะห์ข้อมูลเบื้องต้นคืออะไร 
PPT

PDF

PPT

PDF
Open คณิตศาสตร์ (พื้นฐาน) ม.6 หน่วย3_การวิเคราะห์ข้อมูลเบื้องต้น(2).pdf 
PPT
สถิติพรรณนาในการวิจัยเชิงปริมาณ ปรับSlide-เพิ่มslideงานมอบหมาย 
PPTX
Spc basic for training in thai 
PPT

PDF
การวิเคราะห์ข้อมูลเบื้องต้นคืออะไร 
PDF

PDF
การวิเคราะห์ข้อมูลเบื้องต้นคืออะไร 
PDF

PPTX
17 การวัดการกระจายของข้อมูล 
PPTX
17 การวัดการกระจายของข้อมูล 
PDF
สูตรสถิติ
- 1.
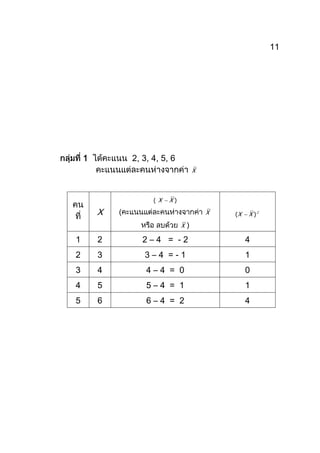
หน่วยการเรียนรู้ที่ 7.9 เรื่อง การวิเคราะห์ข้อมูล<br />การวิจัยในชั้นเรียน ไม่จำเป็นต้องใช้สถิติขั้นสูงที่ซับซ้อนมากนัก บทบาทของสถิติสำหรับการวิจัยในชั้นเรียน คือการช่วยสรุปและให้ความหมายต่อข้อมูลเพื่อประโยชน์ในการนำไปใช้พัฒนาการเรียนการสอนของครูโดยตรง ซึ่งความหมายคำว่า “สถิติ”(Statistices) มีความหมาย 2 ประการ ประการแรก หมายถึง ข้อความจริงหรือตัวเลขที่ได้จากการรวบรวมไว้เพื่อหาความหมายที่แน่นอน (อันธิกา สุปริยศิลป์, 2541:1) ประการที่สอง หมายถึง วิธีการอันเป็นหลักที่จะตัดสินลงสรุปข้อมูลชุดใดๆที่ไม่มีค่าแน่นอนให้ได้ใกล้ความจริงอย่าง ชาญฉลาด (ล้วน สายยศ และอังคณา สายยศ, 2536:54) ดังนั้น การวิจัยในชั้นเรียนจึง ไม่จำเป็นต้องใช้สถิติขั้นสูงที่ซับซ้อน เพื่อเป็นเครื่องมืออ้างอิงผลการวิจัย อย่างไรก็ตามในบางกรณีอาจใช้สถิติทดสอบ เช่น ใช้สถิติ t-test เพื่อนำผลการทดสอบไปใช้เป็นข้อมูลช่วยในการตัดสินใจด้านประสิทธิภาพวิธีการที่ครูทดลองใช้ในการวิจัยเชิงทดลองรายกลุ่ม<br />สถิติพื้นฐานสำหรับการวิจัยในชั้นเรียนการนำเสนอผลการวิเคราะห์ ควรใช้วิธีที่สื่อความหมายให้เข้าใจง่ายและน่าสนใจเพิ่มเติมจากตารางหรือใช้แทนตาราง เช่นแผนภาพหรือกราฟ ทั้งในการบรรยายข้อมูลและการเปรียบเทียบเชื่อมโยงข้อมูล และควรมีการนำเสนอข้อมูลเชิงคุณภาพผลการแก้ปัญหาหรือพัฒนาผู้เรียนได้อย่างชัดเจนและมีข้อมูลเชิงประจักษ์ที่สะท้อนผลการแก้ปัญหาหรือพัฒนา จะทำให้งานวิจัยในชั้นเรียนมีคุณค่าและน่าเชื่อถือมากยิ่งขึ้น<br /> <br />ค่าร้อยละ ( Percentage ; %) <br />เป็นคำที่แสดงการเปรียบเทียบต่อร้อยในการวิเคราะห์ข้อมูลระดับนามบัญญัติ (Norminal Scales) ซึ่งเป็นข้อมูลเชิง คุณภาพ คือ ข้อมูลที่ไม่สามารถวัดออกมาเป็นค่าของ ตัวเลขได้โดยตรง แต่จะเป็นข้อมูลที่บรรยายคุณสมบัติหรือลักษณะของสิ่งที่กำลังสนใจ เช่น จำนวนนักเรียนชาย/หญิงที่สอบผ่าน/ไม่ผ่าน จำนวนนักเรียนที่ได้ระดับคะแนนในระดับต่างๆ เป็นต้น ซึ่งบางครั้งในการสรุป อภิปราย เปรียบเทียบข้อมูล ตั้งแต่ 2 กลุ่ม ขึ้นไป เมื่อจำนวนข้อมูลไม่เท่ากันทำให้การเปรียบเทียบทำได้ยาก ไม่สะดวกในการสรุปผล จึง จำเป็นต้องปรับจำนวนโดยใช้ฐานให้เท่ากัน ฐานจำนวนที่นิยมใช้กัน คือ ฐานจำนวน 100 หรือเป็นอัตราส่วน ที่มีส่วนเป็น 100 นั่นเอง ดังนั้นค่าที่ได้จึงเป็นค่าที่เรียกว่า ร้อยละหรือ เปอร์เซนต์ (Percentge ; %) เช่น = , = 70%<br /> <br />สูตร การหาร้อยละ = <br />n หมายถึง จำนวนที่สนใจ , N หมายถึง จำนวนทั้งหมด<br />ผลการสรุปข้อมูลที่เป็นร้อยละ ต้องแสดงจำนวนข้อมูลทั้งหมด ให้ทราบด้วย เนื่องจากบางครั้งข้อมูลในแต่ละชุด มีจำนวนข้อมูลทั้งหมดแตกต่างกันมาก<br />ค่าเฉลี่ยเลขคณิต (Arithmetic Mean)<br />เป็นการวิเคราะห์ข้อมูลในระดับอัตรภาค (Interval Scales) หรือระดับอัตราส่วน (Ratio Scales) ซึ่งข้อมูลเป็นเชิงปริมาณ คือ ข้อมูลใช้แทนขนาด หรือปริมาณ ซึ่งวัดออกมาเป็นค่าของตัวเลขโดยตรง เช่น อายุ ส่วนสูง น้ำหนัก คะแนน เป็นต้น การหาตัวแทน ข้อมูล ที่เป็น “หนึ่งค่า” จะใช้อะไร หรือทำอย่างไร ที่จะได้ตัวแทนข้อมูล ดังนั้นการวัดเพื่อหาแนวโน้มสู่ส่วนกลางของข้อมูล ค่าเฉลี่ยเลขคณิต เป็นค่า “หนึ่งค่า” ที่ใช้เป็นตัวแทนของข้อมูลกลุ่ม หรือเป็นค่าเฉลี่ย (Average) ที่ใช้แทนกลุ่มทั้งหมด <br />ค่าเฉลี่ยเลขคณิต หมายถึง ค่าที่หาได้จากผลรวมของข้อมูลทั้งหมดหารด้วยจำนวนข้อมูลทั้งหมดของข้อมูลชุดนั้น<br />สัญลักษณ์ที่ใช้ ถ้าเป็น ค่าเฉลี่ยของกลุ่มตัวอย่างใช้ และค่าเฉลี่ยของกลุ่ม ประชากรใช้ สูตรในการคำนวณ <br />สูตร = หรือ สูตร = <br /> หมายถึง ผลรวมของคะแนนคนที่ 1 ถึงคนที่ N <br /> หมายถึง ผลรวมของคะแนนนักเรียนทุกคน<br /> N หมายถึง จำนวนนักเรียนทั้งหมด<br />ส่วนเบี่ยงเบนมาตรฐาน (Standard Deviation)<br />ในการวัดเพื่อหาแนวโน้มสู่ส่วนกลาง ทำให้เราทราบคุณลักษณะของข้อมูลที่เป็น ตัวแทนกลุ่มเพียงค่าเดียวเท่านั้น แต่เนื่องจากค่าที่เป็นตัวแทนกลุ่ม “หนึ่งค่า” นั้น จะทำให้ทราบลักษณะของข้อมูลไม่เพียงพอ เช่น ลักษณะข้อมูลในกลุ่มมีความแตกต่างหรือใกล้เคียงกันมากเพียงใด ดังนั้น ค่าส่วนเบี่ยงเบนมาตรฐาน เป็นค่าสถิติตัวหนึ่งที่สามารถนำมาวัดการกระจายของข้อมูลได้ โดยใช้อธิบายคู่กับ ค่าเฉลี่ยเลขคณิต จะช่วยให้อธิบายข้อมูลได้อย่างถูกต้องสมบูรณ์ยิ่งขึ้นดังจะแสดงในตัวอย่างต่อไป ข้อมูลที่ใช้หาค่าส่วนเบี่ยงเบนมาตรฐาน เป็นข้อมูลที่มีลักษณะเช่นเดียวกับการหาค่าเฉลี่ยเลขคณิต <br />ส่วนเบี่ยงเบนมาตรฐาน เป็นการวัดการกระจายวิธีหนึ่งซึ่งนักสถิตินิยมใช้กันมาก เมื่อเปรียบเทียบกับการกระจายแบบอื่น ทั้งนี้เนื่องจาก<br />เป็นวิธีการวัดการกระจายของข้อมูลซึ่งใช้ค่าในข้อมูลทุกค่ามาคำนวณ<br />มีความละเอียดถูกต้อง น่าเชื่อถือได้ดีที่สุด และสามารถนำไปใช้ในทางสถิติขั้นสูงต่อไปได้<br />ขจัดปัญหาเรื่อง การใช้ค่าสัมบูรณ์<br />มีวิธีลัดในการคำนวณ ทำให้การคำนวณทำได้สะดวกและรวดเร็ว<br />ส่วนเบี่ยงเบนมาตรฐาน คือ รากที่สองที่ไม่เป็นจำนวนลบ ของค่าเฉลี่ยของกำลังสองของผลต่างระหว่างค่าในข้อมูลกับค่าเฉลี่ยเลขคณิตของข้อมูลนั้น หรือ ถ้าให้ความหมายที่ง่ายต่อการเข้าใจ ส่วนเบี่ยงเบนมาตรฐานหมายถึง ผลรวมของทุกค่าที่ห่างจากค่ากลางของข้อมูล (X -) ที่ยกกำลังสอง หารด้วยจำนวนข้อมูล แล้วนำค่าที่ได้มาหาค่ารากที่สอง ()<br /> <br />2520315304165สัญลักษณ์ที่ใช้แทน ส่วนเบี่ยงเบนมาตรฐาน คือ S หรือ S.D. กรณีเป็นกลุ่มตัวอย่างและ (ซิกมา (Sigma)) ในกรณีที่เป็นประชากร<br />สูตรการคำนวณมีดังนี้<br /> ก. ส่วนเบี่ยงเบนมาตรฐานของประชากร ()<br />สูตร = หรือ สูตร = <br />เขียนอย่างง่าย = เขียนอย่างง่าย = <br />ส่วนเบี่ยงเบนมาตรฐานของกลุ่มตัวอย่าง (S หรือ S.D.)<br /> สูตร S.D. = หรือ สูตร S.D. = <br />การวัดการกระจายสัมพัทธ์ (Relative dispersion) <br />มีประโยชน์ในการเปรียบเทียบการกระจายของข้อมูลสองชุดว่าข้อมูลใด มีการกระจายมากกว่ากัน ตัวเลขที่เรานำมาเปรียบเทียบนั้นเรียกว่า สัมประสิทธิ์ มีวิธีวัดการกระจายข้อมูลหลายวิธี ซึ่งในที่นี้ขอเสนอใช้ สัมประสิทธิ์แห่งความแปรผัน (Coefficient of Variation ; C.V.)<br /> สูตร C.V. = <br />ค่าสัมประสิทธิ์ เป็นอัตราส่วนจึงไม่มีหน่วย เพราะค่า S.D. และ เป็นค่าที่มีหน่วยเหมือนกัน <br />ตัวอย่างการหาค่าเฉลี่ย () S.D. และ C.V.<br />ตัวอย่าง จากผลการวัดทักษะกระบวนการทางวิทยาศาสตร์ของนักเรียนก่อนเรียน จากคะแนนเต็ม 40 คะแนน นักเรียนทั้งหมด 30 คน ได้คะแนนดังนี้<br />นักเรียนคนที่คะแนนก่อนเรียน(pre-test) =Xi(Xi)21204002235293245764183245152256172897121448101009141961012144111728912162561323529142144115204001611121171214418131691918324201936121183242286423101002411121251214426141962720400282248429183243012144รวม= 480= 8,262<br /> การหาค่า เฉลี่ย ()<br /> จากสูตร ค่าเฉลี่ย ( ) = <br />แทนค่าได้ ; = <br /> = 16<br /> การหาค่า S.D.<br />จากสูตร S.D.= <br />แทนค่าได้ ; S.D.= <br /> S.D. = <br /> S.D. = <br /> S.D. = 4.47<br />เกณฑ์การพิจารณาค่า C.V.C.V. 10 หมายถึง ดีเยี่ยม10 C.V.15 หมายถึง ดีC.V. 15 หมายถึง ปรับปรุง<br /> การหาค่า C.V.<br /> จากสูตร C.V.= <br /> แทนค่าได้; C.V. = <br /> C.V= 27.94<br />ตัวอย่างข้อสังเกตการหาและใช้ ค่าเฉลี่ยกับค่าส่วนเบี่ยงเบนมาตรฐาน<br />ตัวอย่าง ผลการสอบวิชาหนึ่งซึ่งมีคะแนนเต็ม 6 คะแนน กับนักเรียนผลปรากฏดังนี้<br />กลุ่มที่ 1 ได้คะแนน 2, 3, 4, 5, 6<br /> ดังนั้น คะแนนเฉลี่ย () = ………….. ( ให้ลองคิดคำนวณดูก่อน)<br />กลุ่มที่ 2 ได้คะแนน 4, 4, 4, 4, 4 <br />ดังนั้น คะแนนเฉลี่ย () = ………….. ( ให้ลองคิดคำนวณดูก่อน)<br />…เฉลย คะแนนเฉลี่ย () ของ นักเรียนกลุ่มที่ 1 และกลุ่มที่ 2 มีค่าเท่ากับ 4 จากค่าเฉลี่ยของนักเรียนทั้งสองกลุ่ม ถ้านำเพียงค่าเฉลี่ยมาสรุปจะได้ว่า นักเรียนทั้งสองกลุ่มมีผลการทดสอบได้คะแนนเฉลี่ยเท่ากัน ซึ่งผู้ที่อ่านค่าเฉลี่ยแล้วอาจคิดต่อไปว่า นักเรียนทั้งสองห้องมีความเก่งเท่ากัน หรือ ความรู้ความสามารถเหมือนกัน ฯลฯ ได้ และถ้าท่านเป็นอาจารย์ ผู้สอนนักเรียนทั้งสองกลุ่มนี้ ท่านจะเข้าใจดีถึงคุณลักษณะของนักเรียนเป็นอย่างดีและท่านต้องการได้นักเรียนแบบกลุ่มใด การเปรียบเทียบโดยนำเพียงคะแนนเฉลี่ยมาเปรียบเทียบกันคงไม่เพียงพอ และถ้าจะตอบว่านักเรียนทั้งสองกลุ่มมีความสามารถไม่เท่าเทียมกัน หรือยังมีอะไรอีกที่นักเรียนทั้งสองกลุ่มแตกต่างกัน นั่นแสดงได้ว่า เพียงค่าเฉลี่ยเท่านั้นยังไม่เพียงพอที่สามารถอธิบายลักษณะข้อมูลได้ละเอียดมากพอ ยังต้องมีค่าสถิติอะไรอีกที่ต้องมาอธิบายการกระจายของข้อมูล สองกลุ่มนี้อีก ดังนั้น ลองมาพิจารณาต่อว่า ถ้านำค่า ส่วนเบี่ยงเบนมาตรฐาน มาคำนวณเปรียบเทียบคะแนนของนักเรียนทั้งสองกลุ่มนี้<br />กลุ่มที่ 1 ได้คะแนน 2, 3, 4, 5, 6 <br /> คะแนนแต่ละคนห่างจากค่า <br />คนที่X(คะแนนแต่ละคนห่างจากค่า หรือ ลบด้วย )122 – 4 = - 2 4233 – 4 = - 1 1344 – 4 = 0 0455 – 4 = 1156 6 – 4 = 2 4 = 20= 0(สังเกตได้ว่าไม่ว่าข้อมูลจะมีจำนวนและค่าเท่าไรก็ตาม ถ้าผลรวมของค่าที่เกิดจากการลบในแต่ละค่ากับค่าเฉลี่ยจะเป็นศูนย์เสมอ ดังนั้นเพื่อแก้ปัญหาในทางคณิตศาสตร์ จึงเกิดตารางช่อง ถัดไป)= 10(เหตุผลก็เพราะต้องการได้ค่าที่เป็นบวกโดยการยกกำลังสอง)<br />เนื่องจากข้อมูลเป็นกลุ่มตัวอย่างใช้สูตร<br />S.D. = <br />แทนค่า ; S.D. = <br />S.D. = <br /> S.D. 1.58<br />แสดงได้ว่า นักเรียนกลุ่มที่ 1 มีการกระจายของข้อมูล และเมื่อนำมาอธิบายร่วมกับค่าเฉลี่ยได้ว่า นักเรียนกลุ่มที่ 1 มีคะแนนสอบเฉลี่ย ได้ 4 คะแนน แต่ผลคะแนนสอบห้องนี้ นักเรียนอาจได้คะแนนไม่เท่ากันทุกคน โดยคะแนนมีการกระจายกันอยู่ โดยมีคะแนนอยู่ในช่วงคะแนนประมาณ 4 1.58 คะแนน<br />กลุ่มที่ 2 ได้คะแนน 4, 4, 4, 4, 4<br /> คะแนนแต่ละคนมีค่าเท่ากับค่าเฉลี่ย () คือ 4 ทุกค่า ดังนั้น เมื่อเอาค่าแต่ละค่าลบค่าเฉลี่ยจะมีค่าเท่ากับ ศูนย์ (0) ดังนั้น ค่า S.D.ของนักเรียนกลุ่มที่ 2 จึงมีค่าเท่ากับศูนย์ (0) แสดงได้ว่า นักเรียนกลุ่มที่ 2 มีคะแนนสอบอยู่ในช่วงประมาณ 4 0 คือ 4 แสดงได้ว่านักเรียนทุกคนสอบได้คะแนนเท่ากันหมดทุกคน คือ 4 คะแนน <br />จากการหาค่าส่วนเบี่ยงเบนมาตรฐาน (S.D.) เมื่อนำมาอภิปรายข้อมูลคู่กับค่าเฉลี่ยแล้วจะเห็นภาพผลการสอบและความสามารถของนักเรียนทั้งสองกลุ่มดีขึ้น ดังนั้นการนำค่าส่วนเบี่ยงเบนมาตรฐาน (S.D.) ซึ่งเป็นการวัดการกระจายข้อมูลมาใช้ จะช่วยให้การอภิปรายข้อมูลได้สมบูรณ์มากยิ่งขึ้น<br />จึงสรุปได้ว่า ค่าของส่วนเบี่ยงเบนมาตรฐาน จะเป็นค่าที่สามารถบอกลักษณะของ ข้อมูลต่อผู้วิจัยได้ (รวีวรรณ ชินะตระกูล อ้างใน ยุทธพงษ์ กัยวรรณ์, 2543 : 158) ดังนี้<br />ค่าส่วนเบี่ยงเบนมาตรฐาน มีค่าเท่ากับ ศูนย์ (0) หมายความว่า ข้อมูลชุดนั้นไม่มีการกระจาย ถ้าเป็นความคิดเห็นของผู้ให้ข้อมูล แสดงว่าความคิดเห็นของทุกคนมีความคิดเห็นต่อสิ่งนั้นเหมือนกัน<br />ค่าส่วนเบี่ยงเบนมาตรฐาน เท่ากับ หนึ่ง (1)หมายความว่า การแจกแจงของข้อมูลมีลักษณะเป็นโค้งปกติ (Symmetry) (ประคอง กรรณสูตร อ้างใน ยุทธพงษ์ กัยวรรณ์, 2543 : 158) ได้เสนอว่า การนำค่าเฉลี่ย ( ) เสนอข้อมูลในงานวิจัยที่ค่าความเบี่ยงเบนมาตรฐานเท่ากับ 1 นั้นถือว่าเป็นการนำเสนอตัวแทนที่ดีที่สุด<br />ค่าส่วนเบี่ยงเบนมาตรฐานมีค่ามากกว่าค่าเฉลี่ย (S.D. > ) ผู้วิจัยไม่ควรเสนอ ข้อมูลด้วย แต่ขอเสนอให้ใช้ ค่ามัธยฐาน (Mdn) หรือค่าฐานนิยม (Mo) แทนตามความเหมาะสม<br />ค่ามัธยฐาน หมายถึง ค่าของข้อมูลที่อยู่ตำแหน่งกลางของข้อมูลชุดนั้น เมื่อนำข้อมูลมาเรียงลำดับแล้วจากน้อยไปหามาก หรือจากมากไปหาน้อย หรือ ค่ามัธยฐาน คือ ข้อมูลตัวที่ 50% จากการเรียงลำดับแล้ว<br />ค่าฐานนิยม หมายถึง ข้อมูลที่มีความถี่มากที่สุดในข้อมูลชุดหนึ่ง<br />เมื่อค่าส่วนเบี่ยงเบนมาตรฐาน ใกล้ ศูนย์ (0) แสดงว่า ข้อมูลมีการกระจายน้อย ถ้าเป็นความคิดเห็นของผู้ให้ข้อมูลต่อสิ่งใดสิ่งหนึ่ง แสดงว่ามีความคิดเห็นใกล้เคียงกัน<br />เมื่อค่าส่วนเบี่ยงเบนมาตรฐาน ใกล้ หนึ่ง (1) แสดงว่าการกระจายของข้อมูลชุดนั้นใกล้เคียงกับโค้งปกติ<br />การทดสอบค่าเฉลี่ยประชากรกลุ่มเดียว<br />กรณี 1 ไม่ทราบความแปรปรวนของประชากรและกลุ่มตัวอย่างมีขนาดใหญ่ (n > 30)<br /> ในกรณีที่ไม่ทราบค่าความแปรปรวนของประชากร สามารถประมาณค่าได้ด้วยความแปรปรวนของตัวอย่าง (S2) ดังนี้<br /> = หรือ = <br /> S = หรือ S = <br /> สถิติทดสอบ คือ Z = <br /> Z คือ ตัวสถิติที่ใช้ทดสอบ คือ คะแนนเฉลี่ยของกลุ่มตัวอย่าง คือ คะแนนเฉลี่ยที่กำหนดหรือของประชากร S คือ ส่วนเบี่ยงเบนมาตรฐานของกลุ่มตัวอย่าง n คือ จำนวนของกลุ่มตัวอย่าง<br />ตัวอย่างที่ 1 ครูผู้สอนวิชาวิทยาศาสตร์ชั้นมัธยมศึกษาปีที่ 1 ผู้หนึ่งได้จัดทำชุดฝึกทักษะการสังเกตขึ้น และเชื่อมั่นว่าชุดฝึกฯ ที่เขาได้จัดทำนี้ เมื่อนำไปใช้กับนักเรียนแล้วผลลัพธ์ทางการเรียนด้านการสังเกตของนักเรียนสูงกว่าเกณฑ์มาตรฐานที่กำหนดไว้ โดยกำหนดเกณฑ์มาตรฐาน คือ 75 คะแนน จากคะแนนเต็ม 100 คะแนน โดยชุดฝึกทักษะการสังเกตได้นำไปทดลองใช้กับนักเรียน 36 คน หลังการใช้ชุดฝึกฯ ได้ทำการทดสอบกับนักเรียนปรากฏได้คะแนนดังนี้ <br />คนที่123456789101112คะแนน757868788285787686828074<br />คนที่131415161718192021222324คะแนน768273867876847579808274<br />คนที่252627282930313233343536คะแนน868280767579757072857972<br />การวิเคราะห์ข้อมูล<br />นักเรียนคนที่คะแนน (X)X21755,6252786,0843684,6244786,0845826,7246857,2257786,0848765,7769867,39610826,72411806,40012745,47613765,77614826,72415735,32916867,39617786,08418765,77619847,05620755,62521796,24122806,40023826,72424745,47625867,39626826,72427806,40028765,77629755,62530796,24131755,62532704,90033725,18434857,22535796,24136 725,184รวม<br /> <br /> = แทนค่า; S = <br /> แทนค่า; = S = <br /> <br /> = 78.28 S 4.67<br /> <br />จากโจทย์ สมมติฐานการวิจัย คะแนนเฉลี่ยหลังการใช้ชุดฝึกทักษะการสังเกต สูงกว่าเกณฑ์มาตรฐานที่กำหนด<br /> การทดสอบ<br /> H0 : = 75 H1 : > 75 <br /> ค่าสถิติที่ใช้ในการทดสอบคือ Z – test ( n> 30)<br /> จาก Z = <br />แทนค่า ; Z = <br />Z = <br />Z = <br />Z = 4.21<br /> ที่ระดับนัยสำคัญ .05 ค่า Z = 1.645 (ค่า Z ใช้วิธีการเปิดตาราง หน้า 178)<br /> ค่า Z ที่คำนวณ มากกว่า ค่า Z ที่ได้จากการเปิดตาราง (4.21 > 1.645) หมายความว่า เราจะปฏิเสธ H0 หรือยอมรับ H1 <br />แสดงว่า นักเรียนที่เรียนโดยใช้ชุดฝึกทักษะการสังเกตที่ครูได้พัฒนาขึ้นมามีผลสัมฤทธิ์ทางการเรียนด้านการสังเกตสูงกว่าคะแนนเกณฑ์มาตรฐานที่กำหนด ด้วยความ เชื่อมั่น 95%<br /> กรณีที่ 2 ไม่ทราบค่าความแปรปรวนของประชากรและตัวอย่างมีขนาดเล็ก ( n 30 )<br /> สถิติทดสอบคือ t = , df = n-1<br /> t คือ ตัวสถิติที่ใช้ทดสอบ คือ คะแนนเฉลี่ยของกลุ่มตัวอย่าง คือ คะแนนเฉลี่ยที่กำหนดหรือของประชากร S คือ ส่วนเบี่ยงเบนมาตรฐานของกลุ่มตัวอย่าง n คือ จำนวนของกลุ่มตัวอย่าง<br /> <br /> <br /> <br />สำหรับค่า S หาเช่นเดียวกับ กรณีที่ 1<br />ตัวอย่างที่ 2 ครูผู้สอนวิชาวิทยาศาสตร์ชั้นมัธยมศึกษาปีที่ 3 ผู้หนึ่งได้จัดทำแบบฝึกทักษะการแก้โจทย์ปัญหาเรื่องโมเมนต์ และเชื่อมั่นว่าแบบฝึกฯ ที่เขาได้จัดทำนี้ เมื่อนำไปใช้กับ นักเรียนแล้ว มีทักษะการแก้โจทย์ปัญหาเกี่ยวเรื่อง โมเมนต์ สูงกว่าเกณฑ์มาตรฐานที่กำหนดไว้ โดยกำหนดเกณฑ์มาตรฐานที่กำหนดไว้ 80 คะแนน ที่ระดับความเชื่อมั่น 95% โดยแบบฝึกทักษะการแก้โจทย์ปัญหา เรื่องโมเมนต์ ได้นำไปทดลองใช้กับนักเรียน 25 คน หลังใช้แบบฝึกฯ ได้ทำการทดสอบกับนักเรียน ปรากฏได้คะแนน ดังนี้<br />คนที่12345678910111213คะแนน85887882848582868682807876<br />คนที่141516171819202122232425คะแนน828286788684897980828480<br />การวิเคราะห์ข้อมูล <br />นักเรียนคนที่คะแนน (X)X21857,2252887,7443786,0844826,7245847,0566857,2257826,7248867,3969867,39610826,72411806,40012786,08413765,77614826,72415826,72416867,39617786,08418867,39619847,05620897,92121796,24122806,40023826,72424847,05625806,400รวม <br /> = แทนค่า; S = <br /> แทนค่า; = S = <br /> <br /> = 82.56 S 3.39<br />จากโจทย์ สมมติฐานการวิจัย คะแนนเฉลี่ยหลังการใช้แบบฝึกทักษะการแก้โจทย์ปัญหา เรื่องโมเมนต์ สูงกว่าเกณฑ์มาตรฐานที่กำหนด<br /> การทดสอบ<br /> H0 : = 80 H1 : > 80 <br /> ค่าสถิติที่ใช้ในการทดสอบคือ t – test <br /> จาก t = <br />แทนค่า; t = <br /> t = <br /> t = <br /> t = 3.78<br /> ค่า df = n – 1<br /> แทนค่า; df = 25 – 1 , df = 24<br /> ที่ระดับนัยสำคัญ .05 และ df = 24 ค่า t.05,24 = 1.711 (ค่า t จากการเปิดตาราง)<br />ค่า t ที่คำนวณ มากกว่า ค่า t ที่ได้จากการเปิดตาราง (3.78 > 1.711) หมายความว่า เราจะปฏิเสธ H0 หรือ ยอมรับ H1 <br />แสดงว่า นักเรียนที่เรียนโดยใช้แบบฝึกทักษะการแก้โจทย์ปัญหา เรื่อง โมเมนต์ ที่ครูได้พัฒนาขึ้นมามีทักษะการแก้โจทย์ปัญหา เรื่อง โมเมนต์ สูงกว่าคะแนนเกณฑ์มาตรฐานที่กำหนดด้วยความเชื่อมั่น 95%<br />กรณีการทดสอบค่าสัดส่วนของประชากรกลุ่มเดียว<br />กรณี 3 การทดสอบค่าสัดส่วนของประชากรกลุ่มเดียว<br />จากตัวอย่างที่ 1 และ 2 จะเห็นได้ว่าเป็นการทดสอบคะแนนเฉลี่ยของนักเรียนในกลุ่มทดลองกับเกณฑ์มาตรฐานที่กำหนดไว้ แต่ถ้าต้องการทดสอบว่าจำนวนนักเรียนที่ผ่านเกณฑ์มาตรฐานมีจำนวนตามที่กำหนดหรือไม่ จะใช้การทดสอบ แบบกรณีที่ 1 และ 2 ไม่ได้ จึงต้องใช้ในกรณีที่ 3 ในการทดสอบ คือ<br /> คือ ค่าสัดส่วนที่ได้จากกลุ่มตัวอย่าง P คือ ค่าสัดส่วนที่กำหนด n คือ ขนาดตัวอย่าง<br />สถิติทดสอบคือ Z = <br /> <br />การใช้สูตรดังกล่าวควรใช้กับกลุ่มตัวอย่างที่มีขนาดใหญ่ เพราะการแจกแจงค่า สัดส่วนของกลุ่มตัวอย่างจะเข้าใกล้การแจกแจงแบบปกติได้ดียิ่งขึ้น<br /> ตัวอย่างที่ 3 ครูบัญชาสอนวิชาเคมีชั้นมัธยมศึกษาปีที่ 4 ได้จัดทำชุดสื่อประสมเรื่อง โครงสร้างอะตอม ได้กำหนดเกณฑ์การผ่านไว้ 70 คะแนนจากคะแนนเต็ม 100 คะแนน และครูบัญชาเชื่อว่านักเรียนที่เรียนโดยใช้ชุดสื่อประสมฯ นี้ จะมีผลสัมฤทธิ์เรื่องโครงสร้างอะตอม ผ่านเกณฑ์ที่กำหนดมีจำนวนมากกว่า 75% ของนักเรียนทั้งหมด เมื่อครูบัญชาได้นำชุดสื่อประสมดังกล่าวไปใช้กับนักเรียน 3 ห้อง จำนวน 120 คน มีจำนวนนักเรียนที่สอบผ่านเกณฑ์ 102 คน<br />2917190628015ครูบัญชาต้องการทดสอบสมมติฐานว่า นักเรียนที่เรียนโดยใช้ชุดสื่อประสมเรื่อง โครงสร้างอะตอม มีผลสัมฤทธิ์เรื่องโครงสร้างอะตอม ผ่านเกณฑ์ที่กำหนดมีจำนวนมากกว่า 75% ของนักเรียนทั้งหมด<br />การวิเคราะห์ข้อมูล<br />สมมติฐานทางสถิติ คือ <br />H0 : P = 0.75 <br />H1 : P > 0.75<br />ค่าสถิติที่ใช้ในการทดสอบ คือ Z-test<br />Z = <br />แทนค่าของ n = 120, = หรือ = 0.85 ,P = 75% หรือ P = 0.75, <br /> 1-P = 1-0.75 , 1 – P = 0.25<br />แทนค่า; Z = <br /> <br /> Z = , Z = 2.532<br /> ที่ระดับนัยสำคัญ .05 ค่า Z = 1.645 (ค่า Z ใช้วิธีการเปิดตาราง หน้า 178)<br /> ค่า Z ที่คำนวณ มากกว่า ค่า Z ที่ได้จากการเปิดตาราง (2.532 > 1.645) หมายความว่า เราจะปฏิเสธ H0 หรือยอมรับ H1 <br />สรุปได้ว่า นักเรียนที่เรียนโดยใช้ชุดสื่อประสมเรื่องโครงสร้างอะตอม มีผลสัมฤทธิ์เรื่องโครงสร้างอะตอม ผ่านเกณฑ์ที่กำหนดมีจำนวนมากกว่า 75% ของนักเรียนทั้งหมด ด้วยความเชื่อมั่น 95%<br />1. ตัวอย่างของการคำนวณทั้ง 3 แบบนี้เป็นการคำนวณค่า Z หรือ ค่า t ตามสูตร แล้วเปรียบเทียบค่า Z หรือ ค่า t จากตาราง ตามระดับนัยสำคัญที่กำหนด และถ้าเป็นค่า t ใช้ ค่า df ตามที่คำนวณ<br />2. ถ้าเป็นการวิเคราะห์ข้อมูลโดยใช้โปรแกรม SPSS for Windows แล้วไม่จำเป็นต้องเปิดตารางค่าของ Z หรือ ค่า t เนื่องจาก ค่าที่คำนวณโดยโปรแกรมวิเคราะห์จะคำนวณมาเป็นค่าของ P-value หรือ ค่า Sig t แล้วจึงสามารถนำไปเปรียบเทียบกับค่าระดับนัยสำคัญที่กำหนดไว้ได้ ถ้ายังไม่ทราบขั้นตอน โปรดศึกษาเพิ่มเติมได้ หรือปรึกษาผู้รู้ต่อไป<br />การทดสอบค่าเฉลี่ยสำหรับสองกลุ่มตัวอย่าง ( Testing Two Sample Mean )<br /> ในกรณีที่มีการตั้งสมมติฐาน ต้องมีการทดสอบสมมติฐานที่ตั้งไว้ การทดสอบค่าเฉลี่ยสำหรับการทดสอบกลุ่มตัวอย่างนั้น จะเป็นการทดสอบความแตกต่างของค่าเฉลี่ยระหว่าง 2 กลุ่ม ซึ่งขึ้นอยู่กับกลุ่มตัวอย่างที่ผู้วิจัยทำการทดสอบว่าเป็น กลุ่มตัวอย่างที่มีความสัมพันธ์กันหรือไม่ ดังนั้น จึงมีวิธีการทดสอบผลต่างของค่าเฉลี่ยสำหรับสองกลุ่ม ตัวอย่าง 2 กรณี ดังนี้คือ<br />กรณีกลุ่มตัวอย่างเป็นอิสระต่อกัน (Independent Sample)<br />กรณีกลุ่มตัวอย่างมีความสัมพันธ์กัน (Dependent Sample)<br />ในที่นี้ขอเสนอ กรณีกลุ่มตัวอย่างมีความสัมพันธ์กัน ( Dependent Sample) เท่านั้น ส่วนกรณีกลุ่มตัวอย่างเป็นอิสระต่อกัน (Independent Sample) จะไม่นิยมใช้ในการทำวิจัยในชั้นเรียนที่มีเป้าหมายเพื่อแก้ปัญหาหรือพัฒนาการเรียนรู้ของนักเรียนเป็นสำคัญ เพราะครูผู้สอนมีหน้าที่ต้องพัฒนาการเรียนรู้ของนักเรียนทุกคนอยู่แล้วจึงไม่จำเป็นต้องมีกลุ่มควบคุม จะมีก็เพียงกลุ่มทดลองเท่านั้นซึ่งหมายถึงกรณีที่ 1 นั่นเอง อย่างไรก็ตามหากสนใจกรณีที่ 2 ขอให้ไปศึกษาเพิ่มเติมได้ในตำราสถิติเบื้องต้นทั่วไป<br />กลุ่มตัวอย่างมีความสัมพันธ์กัน ( Dependent Sample)<br />เป็นการทดสอบความแตกต่างของค่าเฉลี่ยระหว่างกลุ่มสองกลุ่มตัวอย่างเมื่อข้อมูลตัวอย่างที่จะใช้ทดสอบมีความสัมพันธ์กัน เช่นการเปรียบเทียบการสอนสองวิธี เราต้องใช้กลุ่มตัวอย่าง คือ นักเรียนทั้งสองกลุ่มมีสมบัติไม่แตกต่างกัน เช่น อายุ ความรู้พื้นฐาน แต่การหากลุ่มตัวอย่างที่มีสมบัติใกล้เคียงกัน หรือมีความสัมพันธ์กันอาจจะทำได้ยาก ดังนั้นจึงมักจะใช้กลุ่มตัวอย่างเดียวกันทำการทดสอบสองครั้ง เช่น การทดสอบคะแนนก่อนเรียนและหลังเรียน (Pretest and Posttest) เป็นการทดสอบที่ใช้กลุ่มตัวอย่างเดียวกันทำการทดสอบสองครั้ง ซึ่งการทดสอบแบบนี้ จะมีการทดสอบความแตกต่างเป็นคู่ๆ โดยแต่ละคู่มีความสัมพันธ์กัน จึงเรียกการทดสอบแบบนี้ว่า เป็นการทดสอบความแตกต่างแบบจับคู่ (Paired Difference Tests)<br /> สูตร t = หรือใช้สูตรที่คำนวณง่าย สูตร t = <br /> = = สัญลักษณ์ที่ใช้ มีความหมายดังนี้ t คือ ค่าสถิติ t ที่ใช้ในการทดสอบ d คือ ค่าผลต่างของคะแนน ก่อนและหลังการทดสอบคือ ค่าเฉลี่ยของผลต่างของคะแนน ก่อนและหลังการทดสอบคือ ค่าเบี่ยงเบนมาตรฐานผลต่างของคะแนน ก่อนและหลังการทดสอบ n คือ จำนวนนักเรียนที่ทำการทดสอบ df = n - 1สัญลักษณ์ที่ใช้ มีความหมายดังนี้ t คือ ค่าสถิติ t ที่ใช้ในการทดสอบ d คือ ค่าผลต่างของคะแนน ก่อนและหลังการทดสอบ คือ การนำเอาผลต่างของคะแนนก่อนและหลังการทดสอบของนักเรียนแต่ละคนมาบวกกันคือ การนำเอาผลต่างของคะแนนก่อนและหลังการทดสอบของนักเรียนแต่ละคนยกกำลังสองแล้วนำมาบวกกันคือ การนำเอาผลต่างของคะแนนก่อนและหลังการทดสอบของนักเรียนแต่ละคนมาบวกกันแล้วจึงยกกำลังสอง n คือ จำนวนนักเรียนที่ทำการทดสอบ df = n - 1 <br />ตัวอย่างที่ 1 การทดสอบสมมติฐาน<br />ถ้าเรามีเพียงค่า เฉลี่ยของคะแนน () และค่าส่วนเบี่ยงเบนมาตรฐาน (S.D.) ของคะแนนผลการทดสอบก่อนหลัง<br />เช่น จากคะแนนสอบวัดผลสัมฤทธิ์ ซึ่งมีคะแนนเต็ม 10 คะแนน ก่อนและหลังการใช้นวัตกรรม จากนักเรียน 30 คน ได้คะแนนดังนี้ <br />คนที่123456789101112131415คะแนนก่อนฯ536542132545524คะแนนหลังฯ647854253123551<br />คนที่161718192021222324252627282930คะแนนก่อนฯ875841364254448คะแนนหลังฯ5581056677256854<br /> คะแนนสอบก่อนใช้นวัตกรรมได้คะแนนเฉลี่ย (ก่อน) = 4.30 คะแนน<br /> S.D. = 1.91 คะแนน<br />คะแนนสอบหลังใช้นวัตกรรมได้คะแนนเฉลี่ย (หลัง) = 5.00 คะแนน<br /> S.D. = 2.18 คะแนน<br />ถ้าท่านพิจารณาโดยใช้ คะแนนเฉลี่ย ทั้งก่อนและหลังจะเห็นได้ว่า หลังการใช้นวัตกรรม คะแนนเฉลี่ยสูงกว่าก่อนการใช้นวัตกรรม แต่ถ้าท่านทดสอบทางสถิติโดยใช้ที่ระดับนัยสำคัญที่ .05 ท่านเชื่อหรือไม่ว่า คะแนนเฉลี่ยหลังการใช้นวัตกรรมมีคะแนนสูงกว่าก่อนการใช้จริง ? <br /> การวิเคราะห์ข้อมูล<br />สมมติฐานทางการวิจัย นักเรียนมีผลสัมฤทธิ์สูงขึ้นหลังการใช้นวัตกรรม<br />คนที่คะแนนก่อนใช้ฯ(Pretest) Xก่อนคะแนนหลังใช้ฯ(Posttest) X หลังd = X หลัง - Xก่อนd21561123411367114583954511624247121183524923111051-4161142-241253-241355001425391541-391685-391775-241858391981024204511211652522363923671124473925220026550027462428484162945113084-416รวม129150= 21 = 173 = 4.30 = 5.00= 441S.D. = 1.91S.D. = 2.18<br />ทดสอบโดยใช้ t-test เป็นการทดสอบความแตกต่างแบบจับคู่ (Paired Difference Tests)<br />สมมติฐานทางสถิติ<br />H0: หลังเรียน= ก่อนเรียน (คะแนนเฉลี่ยหลังการใช้นวัตกรรมเท่ากับก่อนใช้นวัตกรรม)<br />H1: หลังเรียน> ก่อนเรียน<br />คำนวณหาค่า t จากข้อมูล <br />สูตร t = <br />แทนค่า; t = <br />t = <br />t = <br />t = 1.641<br /> ค่า df = n – 1<br />แทนค่า; df = 30 – 1 , df = 29<br /> ที่ระดับนัยสำคัญ .05 และ df = 29 ค่า t.05,29= 1.699 (ค่า t จากการเปิดตาราง)<br /> ค่า t ที่คำนวณ น้อยกว่า ค่า t ที่ได้จากการเปิดตาราง (1.641 < 1.699 ) หมายความว่า เราจะยอมรับ H0<br />3206115356235แสดงว่า ที่ระดับความเชื่อมั่น 95% นักเรียนที่เรียนโดยใช้นวัตกรรมดังกล่าว ยังเชื่อไม่ได้ว่ามีผลสัมฤทธิ์สูงขึ้นหลังการใช้นวัตกรรมจริง <br />ตัวอย่างที่ 2 การทดสอบสมมติฐาน <br />สมมติฐาน : นักเรียนมีทักษะกระบวนการทางวิทยาศาสตร์สูงขึ้น หลังการใช้ชุดฝึกเสริมทักษะกระบวนการทางวิทยาศาสตร์<br />นักเรียนคนที่คะแนนก่อนเรียน(Pretest) =Xiคะแนนหลังเรียน(Posttest) =Yid = Yi - Xid212030101002233512144324328644182810100515301522561728111217122513169810251522591430162561012281625611173215225121630141961323329811421351419615202998116113019361171232204001813301728919183214196201934152252118341625622828204002310291936124113221441251230183242614311728927203616256282236141962918341625630123321441รวม= 450=7,130<br />ทดสอบโดยใช้ t-test เป็นการทดสอบความแตกต่างแบบจับคู่ (Paired Difference Tests)<br /> 1. คำนวณหาค่า t จากข้อมูล<br /> สูตร t = <br />แทนค่าได้ ; t = <br />t = <br />t = 22.697<br />2. ค่าวิกฤติ t ที่ระดับนัยสำคัญ , df = n-1 (ค่าวิกฤติ t ใช้วิธีการเปิดตารางหน้า 177)<br /> แทนค่าได้ ; df = 30-1 <br /> df = 29<br /> กำหนดระดับนัยสำคัญที่ .05 ดังนั้น เปิดตาราง t แบบหางเดียว ที่ = .05 , df = 29<br />ได้ค่า t.05,29 = 1.699<br /> เปรียบเทียบค่าของ t ; t.05,29 < t คำนวณ <br />สรุปได้ว่า นักเรียนมีทักษะกระบวนการทางวิทยาศาสตร์สูงขึ้นหลังการใช้ชุดฝึกเสริมทักษะกระบวนการทางวิทยาศาสตร์ อย่างมีนัยสำคัญทางสถิติที่ระดับ .05<br />ใบกิจกรรม 7.9 การใช้สถิติพื้นฐานสำหรับการวิเคราะห์ข้อมูล <br />กิจกรรมที่ปฏิบัติ ให้แต่ละท่านดำเนินการดังนี้<br />1. ศึกษารายละเอียดในใบความรู้ เรื่อง สถิติพื้นฐานสำหรับการวิเคราะห์ข้อมูล โดยการอ่านอย่างละเอียด<br /> 2. ฝึกการวิเคราะห์และนำเสนอข้อมูลจากตัวอย่างข้อมูลที่กำหนดดังนี้<br /> จากตารางข้างล่าง เป็นคะแนนการประเมินผลในวิชา วิทยาศาสตร์ เรื่อง พลังงาน จำนวน 12 ครั้ง แต่ละครั้งจะประเมินให้ได้คะแนน 4, 3, 2 หรือ 1 ตามเกณฑ์ การประเมิน <br />จากคะแนนที่นักเรียนแต่ละคนได้รับ ให้ท่านวิเคราะห์แล้วนำเสนอข้อมูลตามที่ท่านพิจารณาเห็นว่าเหมาะสมที่สุด<br />นักเรียนหน่วย 1หน่วย 2หน่วย 3หน่วย 41 2 3 45 6 78 9 1011 121234567891011121314152233323323231233112322332233233433442233223332343234333434343332331232331232333343433343342343342433442331232233243332333332333332343332343342343343334443344443444424<br />จากตาราง ให้ท่านฝึกวิเคราะห์<br />1) สถิติที่ใช้ควรใช้สถิติอะไรในการวิเคราะห์ เพราะอะไร ?<br />2) ถ้าสรุปโดยใช้ค่าเฉลี่ยเลขคณิต ผลการวิเคราะห์จะเป็นอย่างไร ต้องสร้างระดับเกณฑ์การประเมินสรุปผลเป็นอย่างไร ?<br />3) ถ้านำเสนอข้อมูลที่วิเคราะห์ในแนว สดมภ์ (Column) ทำให้ทราบผลสรุปเป็นอย่างไร ? <br />4) ถ้านำเสนอข้อมูลที่วิเคราะห์ในแนวนอน (Row) ทำให้ทราบผลสรุปเป็นอย่างไร ?<br />5) ควรนำเสนอภาพรวมโดยสรุปโดยใช้แผนภูมิอะไร ถึงจะเหมาะสมที่สุด ?<br /> <br />เอกสารอ้างอิง<br />ชุดฝึกปฏิบัติการวิจัยในชั้นเรียนสำหรับครูวิทยาศาสตร์. ( 8 เมษายน 2550). http://www.nitesonline.net/<br />