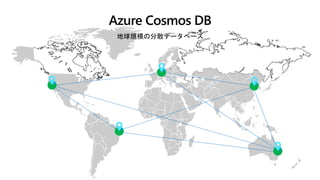
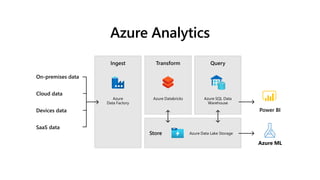
Azure Synapse Analytics
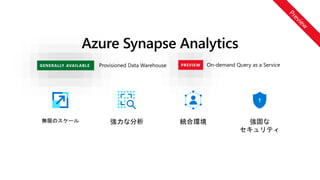
無限のスケール強力な分析 統合環境 強固な
セキュリティ
Provisioned Data WarehouseGENERALLY AVAILABLE On-demand Query as a ServicePREVIEW
34.
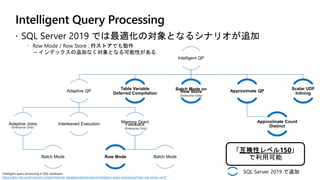
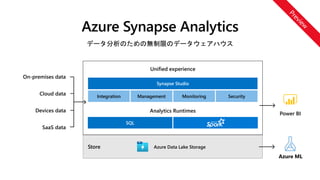
データ分析のための無制限のデータウェアハウス
Store Azure DataLake Storage
SQL
Analytics Runtimes
Synapse Studio
Unified experience
Integration Management Monitoring Security
Cloud data
SaaS data
On-premises data
Devices data
Power BI
Azure Synapse Analytics
サポートされている集計関数:
MAX、MIN、AVG、COUNT、
COUNT_BIG、SUM、VAR、STDEV
CREATE MATERIALIZEDVIEW Sales.vw_Orders
WITH
(
DISTRIBUTION = ROUND_ROBIN |
HASH(ProductID)
)
AS
SELECT SUM(UnitPrice*OrderQty) AS Revenue,
OrderDate,
ProductID,
COUNT_BIG(*) AS OrderCount
FROM Sales.SalesOrderDetail
GROUP BY OrderDate, ProductID;
GO
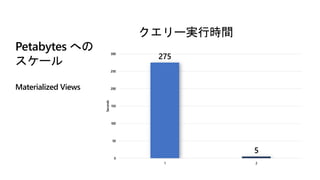
Petabytes への
スケール
Materialized Views
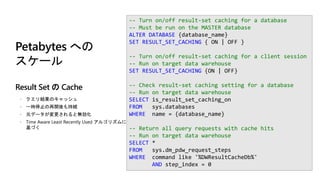
-- Turn on/offresult-set caching for a database
-- Must be run on the MASTER database
ALTER DATABASE {database_name}
SET RESULT_SET_CACHING { ON | OFF }
-- Turn on/off result-set caching for a client session
-- Run on target data warehouse
SET RESULT_SET_CACHING {ON | OFF}
-- Check result-set caching setting for a database
-- Run on target data warehouse
SELECT is_result_set_caching_on
FROM sys.databases
WHERE name = {database_name}
-- Return all query requests with cache hits
-- Run on target data warehouse
SELECT *
FROM sys.dm_pdw_request_steps
WHERE command like '%DWResultCacheDb%'
AND step_index = 0
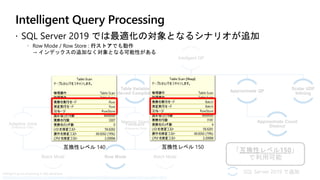
Petabytes への
スケール
Result Set の Cache
41.
オンデマンド での DataLake参照
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://<storage>/path/to/files/*.parquet’,
FORMAT = 'Parquet’
) AS [r]
Data Lake SQL on-demand Client
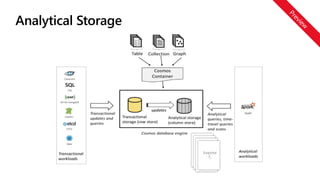
Analytical Storage
Select *
fromBlock
N where
column1 >
column2
Select *
from Block
N where
column1 >
column2
Select *
from Block
N where
column1 >
column2
Snapshot
Tn
Management
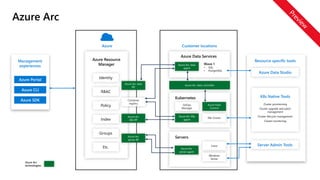
experiences
Azure Portal
Azure CLI
AzureSDK
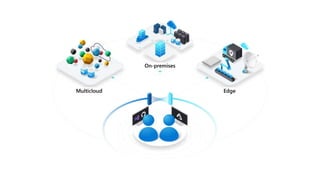
Azure Arc
technologies:
Azure Arc
Azure
Identity
RBAC
Policy
Index
Groups
Etc.
Azure Resource
Manager
Azure Arc data
RP
Container
registry
Azure Arc
K8s RP
Azure Arc
server RP
Azure Data Services
Wave 1
• SQL
• PostgreSQL
Azure Arc data controller
Kubernetes
Azure PaaS
Control
K8s Cluster
Azure Arc data
agent
GitOps
Manager
Azure Arc K8s
agent
Servers
Linux
Windows
Server
Azure Arc
server agent
Resource specific tools
Azure Data Studio
Cluster provisioning
Cluster upgrade and patch
management
Cluster lifecycle management
Cluster monitoring
K8s Native Tools
Server Admin Tools
Customer locations












![オンデマンド での DataLake 参照
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://<storage>/path/to/files/*.parquet’,
FORMAT = 'Parquet’
) AS [r]
Data Lake SQL on-demand Client](https://image.slidesharecdn.com/20191119datatechmicrosoftdahatake-191119003900/85/SQL-Server-2019-Microsoft-Data-Platform-41-320.jpg)




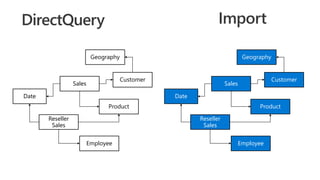
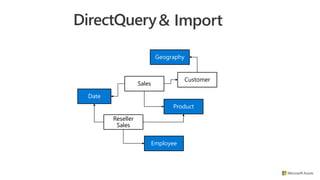
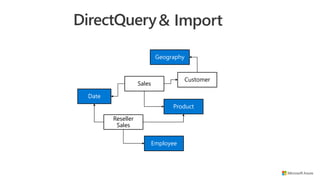
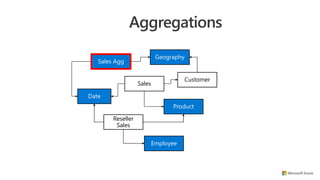
![Sales
Product
Sales Agg
Customer
Geography
Date
Employee
Reseller
Sales
Aggregations
Date
Employee
Reseller
Sales
Customer
Geography
Product
SummarizeColumns(
Date[Year],
Geography[City],
"Sales", Sum(Sales[Amount])
)](https://image.slidesharecdn.com/20191119datatechmicrosoftdahatake-191119003900/85/SQL-Server-2019-Microsoft-Data-Platform-59-320.jpg)
![Sales
Product
Sales Agg
Customer
Geography
Date
Employee
Reseller
Sales
Aggregations
Date
Employee
Reseller
Sales
Customer
Geography
SELECT [Year],
[Name],
SUM([Amount]) AS [Amount]
FROM [Sales]
INNER JOIN [Date] ON ...
INNER JOIN [Customer] ON ...
GROUP BY [Year],
[Name]
Product
SummarizeColumns(
Date[Year],
Customer[Name],
"Sales", Sum(Sales[Amount])
)](https://image.slidesharecdn.com/20191119datatechmicrosoftdahatake-191119003900/85/SQL-Server-2019-Microsoft-Data-Platform-60-320.jpg)













![【ウェブ セミナー】AI 時代のクラウド データ ウェアハウス Azure SQL Data Warehouse [実践編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinarsqldw20170726-180220004900-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DI12] あらゆるデータをビジネスに活用! Azure Data Lake を中心としたビックデータ処理基盤のアーキテクチャと実装](https://cdn.slidesharecdn.com/ss_thumbnails/di12-170616053736-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DI09] ここまで進化した! マイクロソフトの 「BI 」](https://cdn.slidesharecdn.com/ss_thumbnails/di09-170616014918-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DI07] あらゆるデータに価値がある! アンチ断捨離ストのための Azure Data Lake](https://cdn.slidesharecdn.com/ss_thumbnails/di07-170605024557-thumbnail.jpg?width=640&height=640&fit=bounds)

![【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [実践編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinaradl20180308-180308093647-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DI03] DWH スペシャリストが語る! Azure SQL Data Warehouse チューニングの勘所](https://cdn.slidesharecdn.com/ss_thumbnails/di03-170605023803-thumbnail.jpg?width=640&height=640&fit=bounds)




![【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [概要編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinaradl20180215-180219043331-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2017] AzureでOSS DB/データ処理基盤のPaaSサービスを使ってみよう (Azure Dat...](https://cdn.slidesharecdn.com/ss_thumbnails/20170907dbtechshowcaseazureossdb-170907082746-thumbnail.jpg?width=640&height=640&fit=bounds)
![M20_Azure SQL Database 最新アップデートをまとめてキャッチアップ [Microsoft Japan Digital Days]](https://cdn.slidesharecdn.com/ss_thumbnails/m20azuresqldatabase-211027133338-thumbnail.jpg?width=640&height=640&fit=bounds)






































