【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [実践編]
2018/3/8【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [実践編]
https://info.microsoft.com/JA-AABD-WBNR-FY18-03Mar-08-BigdatainfrastructuresupportingAI-MCW0002861_01Registration-ForminBody.html?ls=Website&lsd=AzureWebsite
Azure Data Lakeとは
HDInsight
Spark, Hive,
Storm, Kafka
Data Lake
Analytics
Data Lake Store
WebHDFS
YARN
Azure
Databricks
ストレージ
Azure Data Lake Store (ADLS)
• どんなフォーマットのデータでも無制限に格納
できるストレージ
• 分散型で分析処理パフォーマンスが高い
• OSS との親和性
分析ツール
Azure Data Lake Analytics (ADLA)
• サーバレスの分析エンジン
• 親しみのある SQL に近い U-SQL 言語
• 柔軟なスケールで大量データ処理が得意
• ジョブ単位の課金
7.
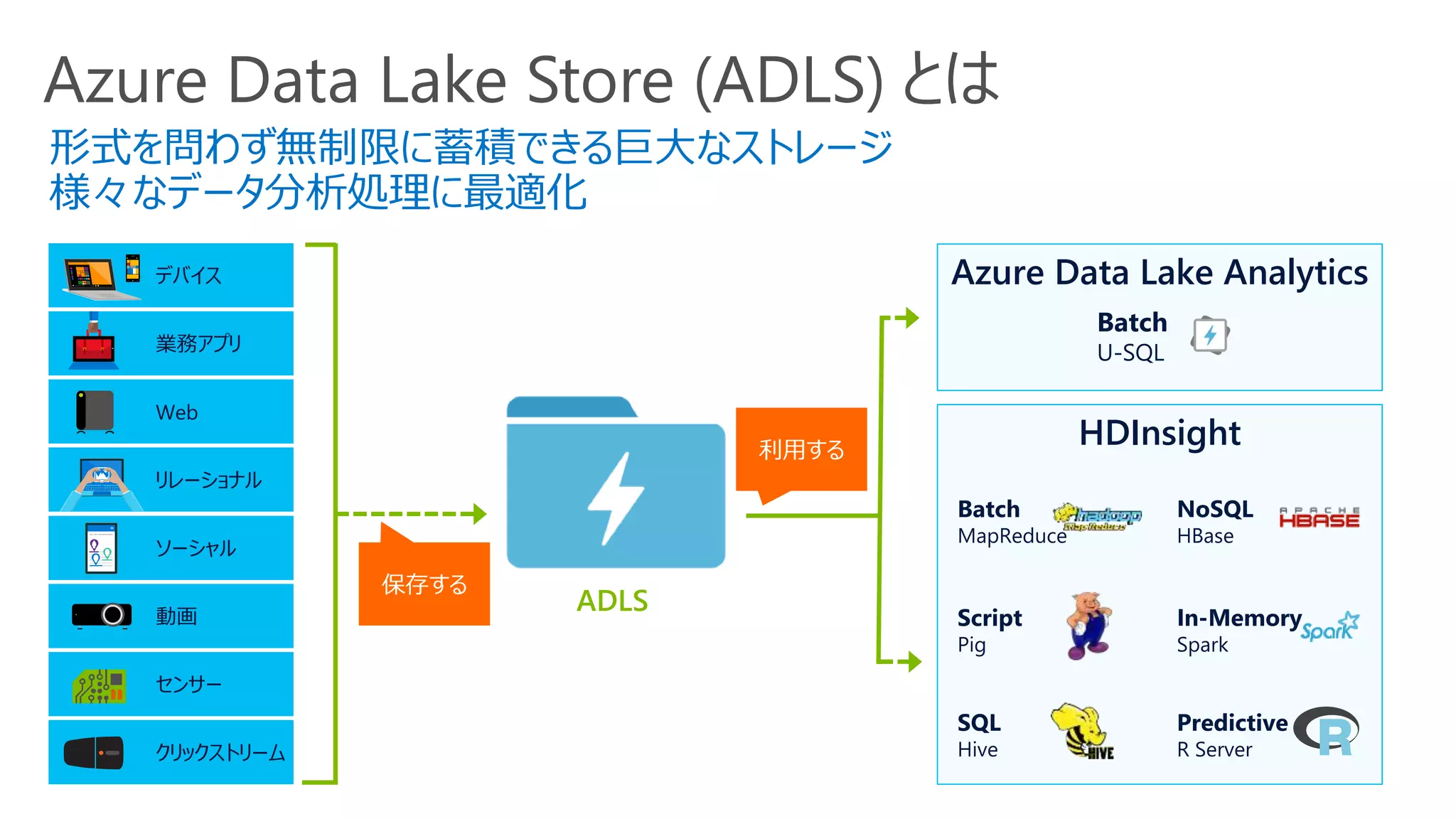
Azure Data LakeStore (ADLS) とは
HDInsight
Azure Data Lake Analytics
形式を問わず無制限に蓄積できる巨大なストレージ
様々なデータ分析処理に最適化
ADLS
業務アプリ
ソーシャル
デバイス
クリックストリーム
センサー
動画
Web
リレーショナル
Batch
MapReduce
Script
Pig
SQL
Hive
NoSQL
HBase
In-Memory
Spark
Predictive
R Server
Batch
U-SQL
利用する
保存する
8.
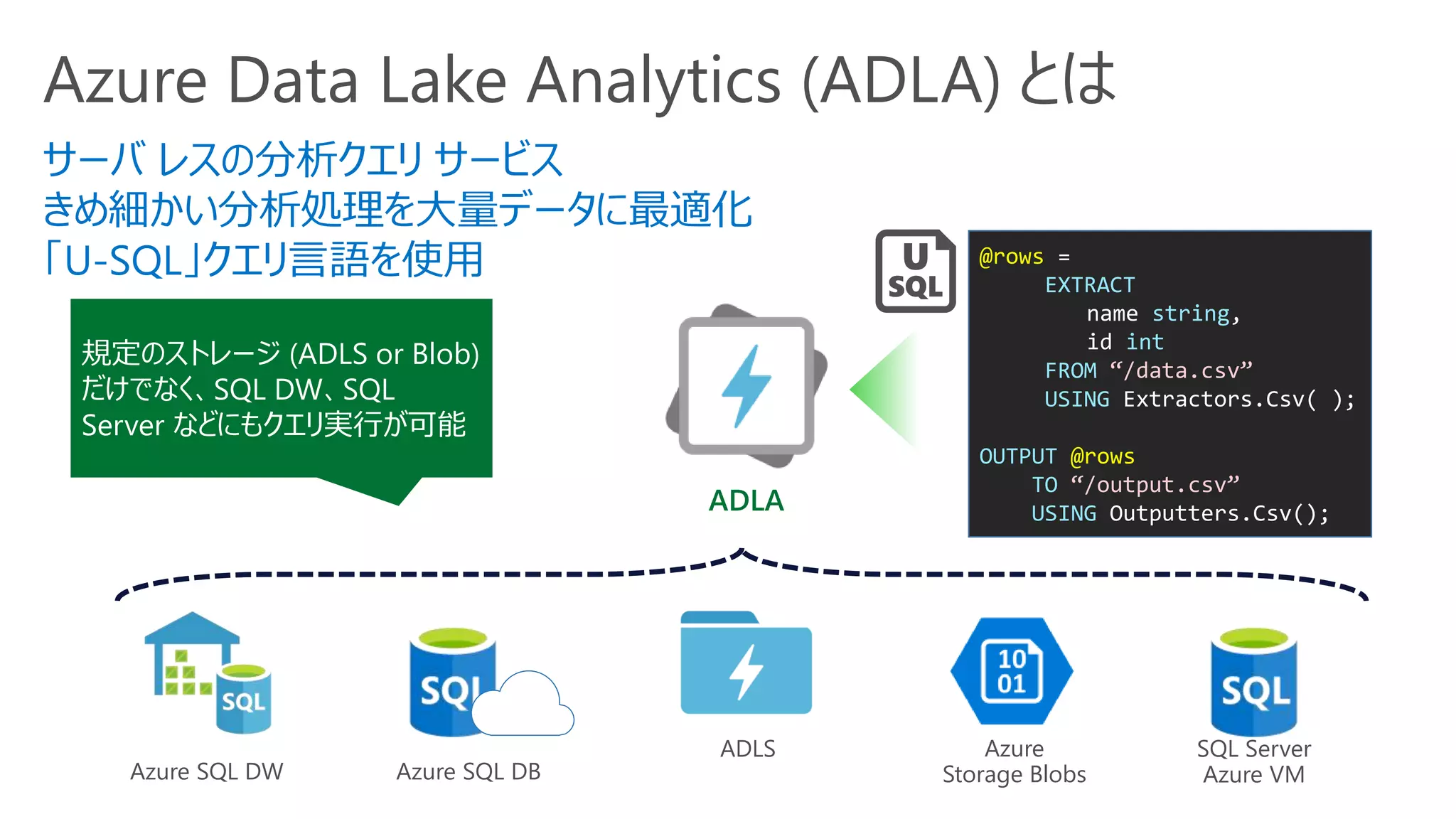
Azure Data LakeAnalytics (ADLA) とは
ADLA
Azure SQL DW Azure SQL DB
Azure
Storage Blobs
ADLS SQL Server
Azure VM
サーバ レスの分析クエリ サービス
きめ細かい分析処理を大量データに最適化
「U-SQL」クエリ言語を使用 @rows =
EXTRACT
name string,
id int
FROM “/data.csv”
USING Extractors.Csv( );
OUTPUT @rows
TO “/output.csv”
USING Outputters.Csv();
規定のストレージ (ADLS or Blob)
だけでなく、SQL DW、SQL
Server などにもクエリ実行が可能
9.
料金の考え方
Azure Data LakeAnalytics
(ADLA)
Azure Data Lake Store
(ADLS)
なし
¥ 224 / 時間
1 AU あたり
定常的にかかる費用 処理量に応じてかかる費用
¥ 4.37 / 1GB / 月
データ容量
書き込み: ¥ 5.60
読み取り: ¥ 0.45
10万トランザクションあたり
例:米国東部 2 リージョン (2018/03/08 時点)
ADLA: https://azure.microsoft.com/ja-jp/pricing/details/data-lake-analytics/
ADLS: https://azure.microsoft.com/ja-jp/pricing/details/data-lake-store/
10.
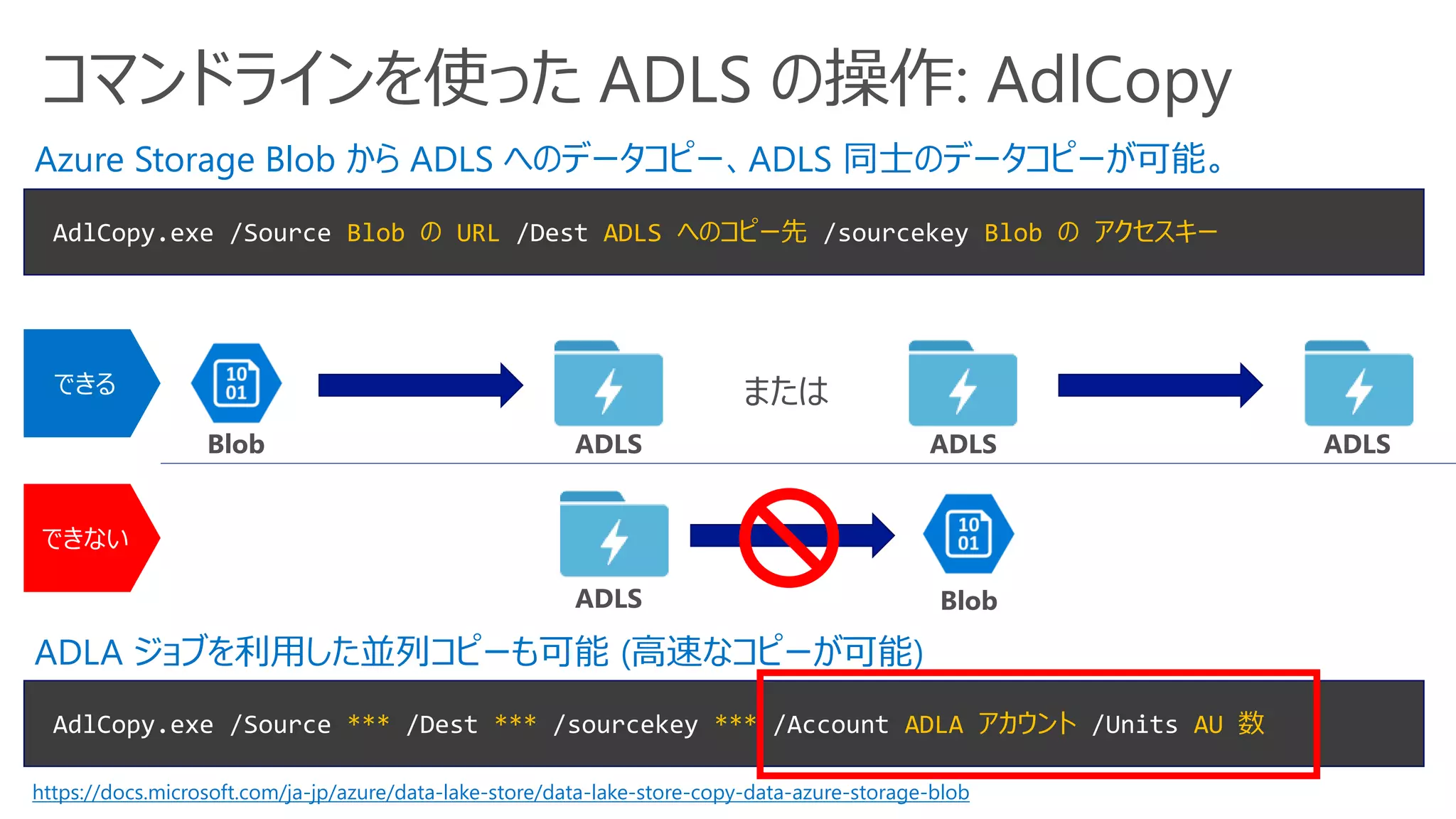
Azure Data Lakeの作成
[+New] -> [Data + Analytics] -> [Data Lake Analytics] から ADLS も同時に作成可能
ADLA 名
リソースグループ
リージョン
接続する ADLS
従量課金
or
コミットメント
ADLS 名
暗号化有無
従量課金
or
コミットメント
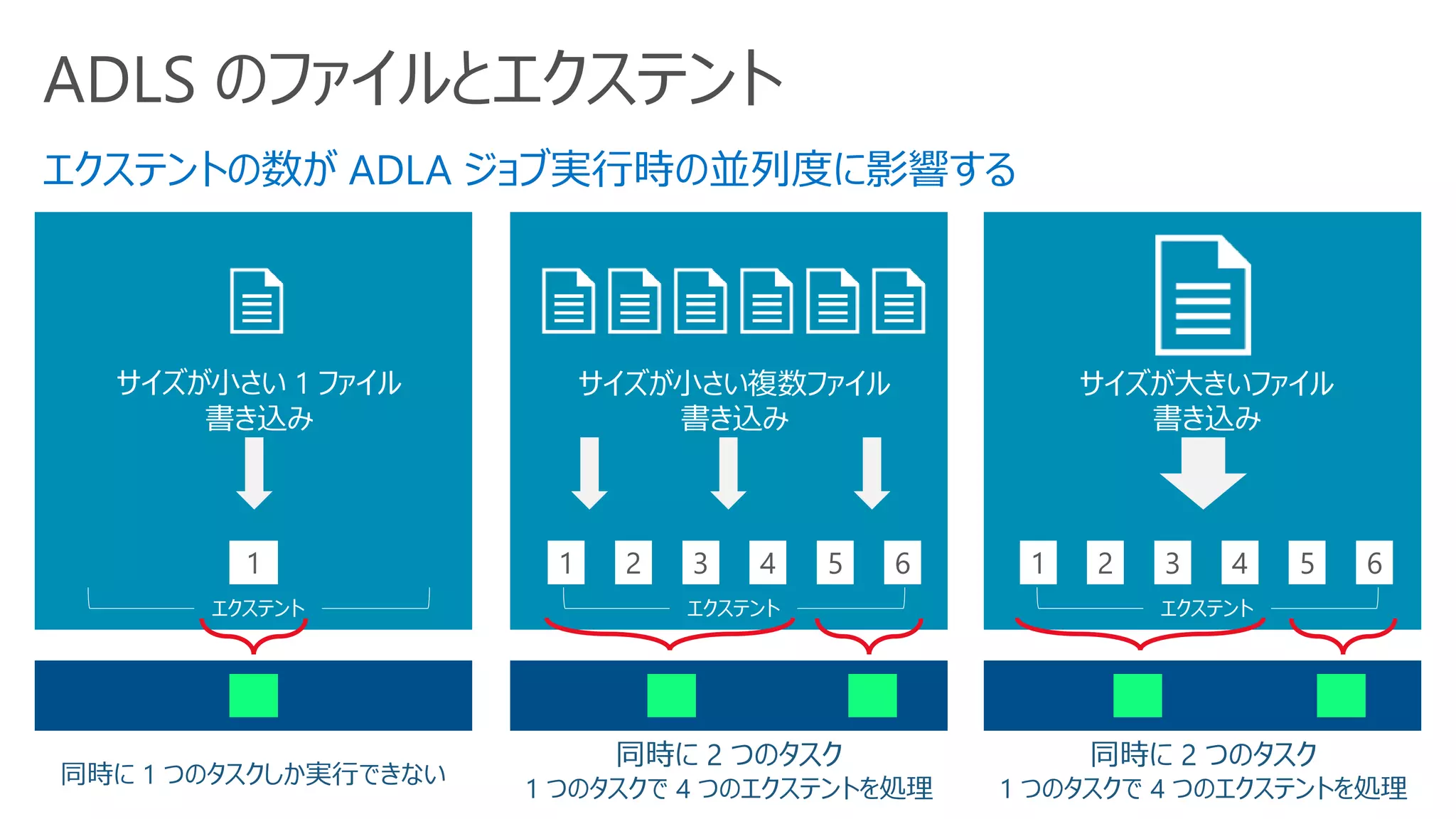
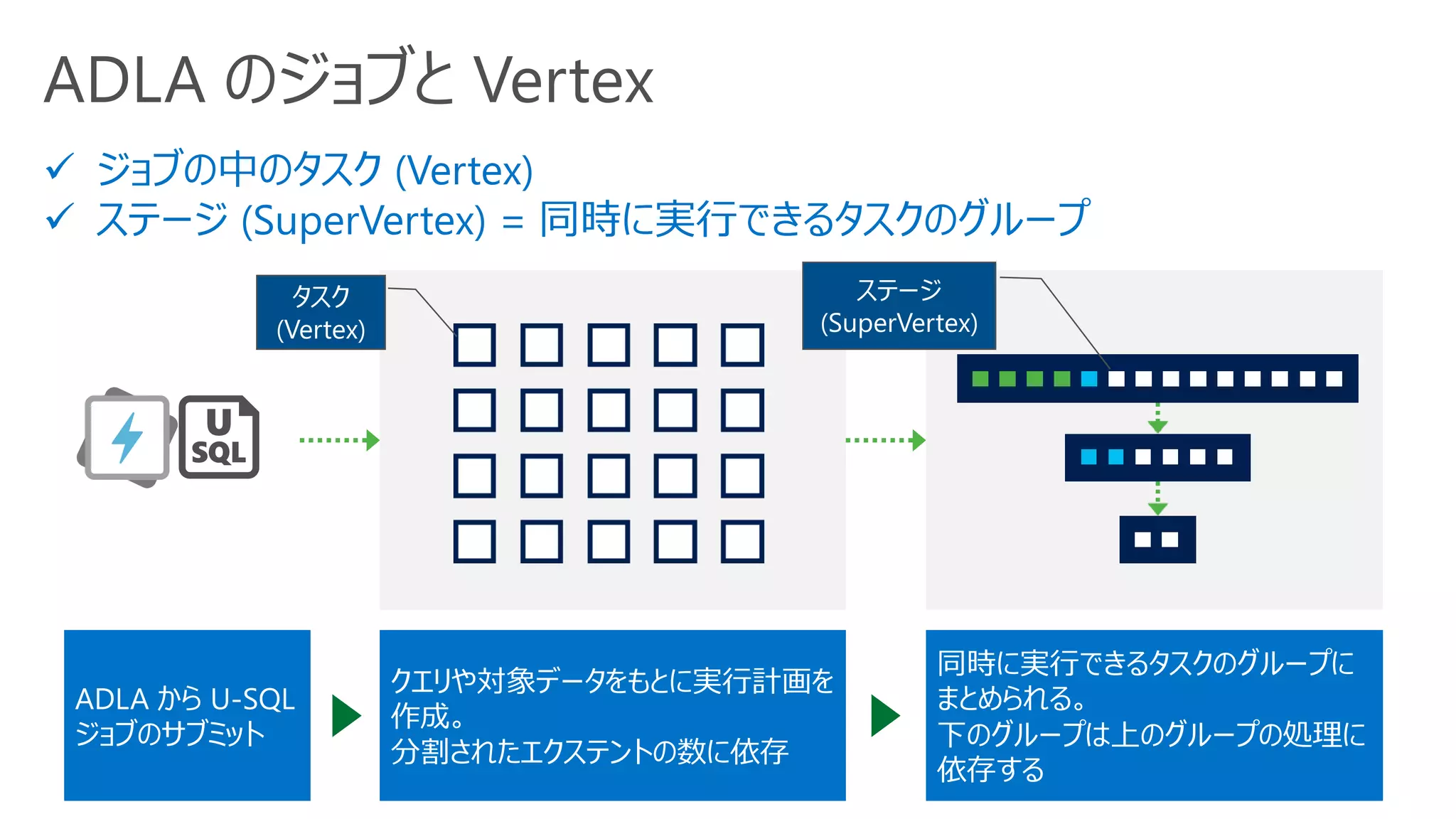
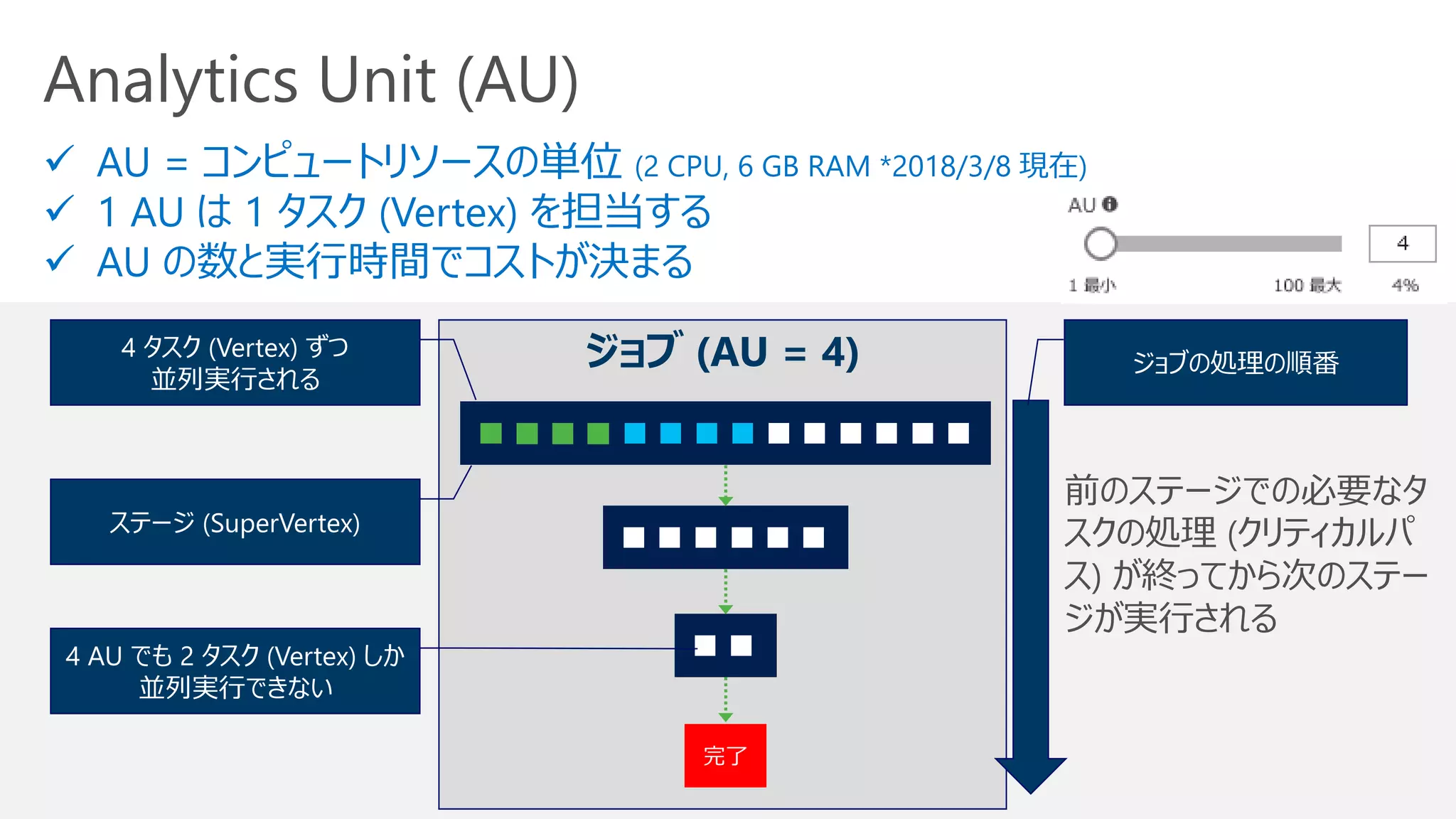
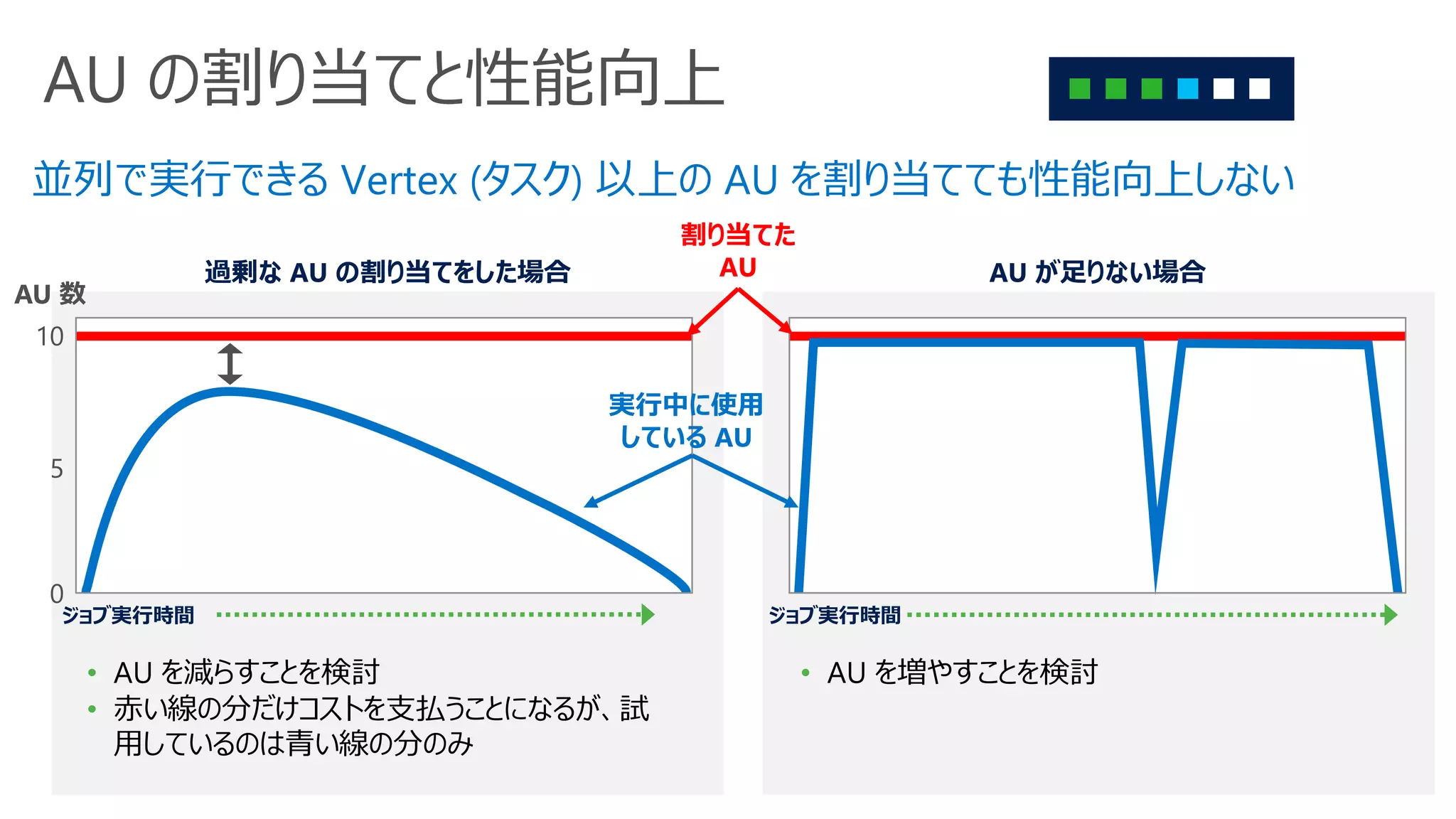
AU の割り当てと性能向上
並列で実行できる Vertex(タスク) 以上の AU を割り当てても性能向上しない
過剰な AU の割り当てをした場合
• AU を減らすことを検討
• 赤い線の分だけコストを支払うことになるが、試
用しているのは青い線の分のみ
AU が足りない場合
• AU を増やすことを検討
ジョブ実行時間ジョブ実行時間
割り当てた
AU
実行中に使用
している AU
10
0
5
AU 数
17.
AU と時間とコスト
割り当てた AUジョブにかかった時間 AU 時間
a-1 10 3 時間 30 AU 時間
a-2 20 1.5 時間 30 AU 時間
a. AU を増やしたほうが良いケース
割り当てた AU ジョブにかかった時間 AU 時間
b-1 10 5 時間 50 AU 時間
b-2 20 4 時間 80 AU 時間
b. AU を増やすか検討が必要なケース
同じ金額でジョブの時間
を半分に短縮できる
→増やす!
60 % のコスト増で 1 時
間のジョブ時間短縮
→増やす?
ADLA の料金 = [割り当てた AU の数] x [時間] (x [単価])
18.
実行計画や必要な AU の確認
Azure管理ポータルや Visual Studio で実行計画、状況、診断結果を確認可能
実行しているジョブが何個の Vertex で実
行されているかを確認することが可能
AU 検討材料
✓ いくつのジョブステージがあるか
✓ ジョブステージ内にいくつのタスクがあるか
✓ ジョブ実行時間
✓ 診断結果の警告
✓ etc
AU が過剰に割り当てられていることを
警告
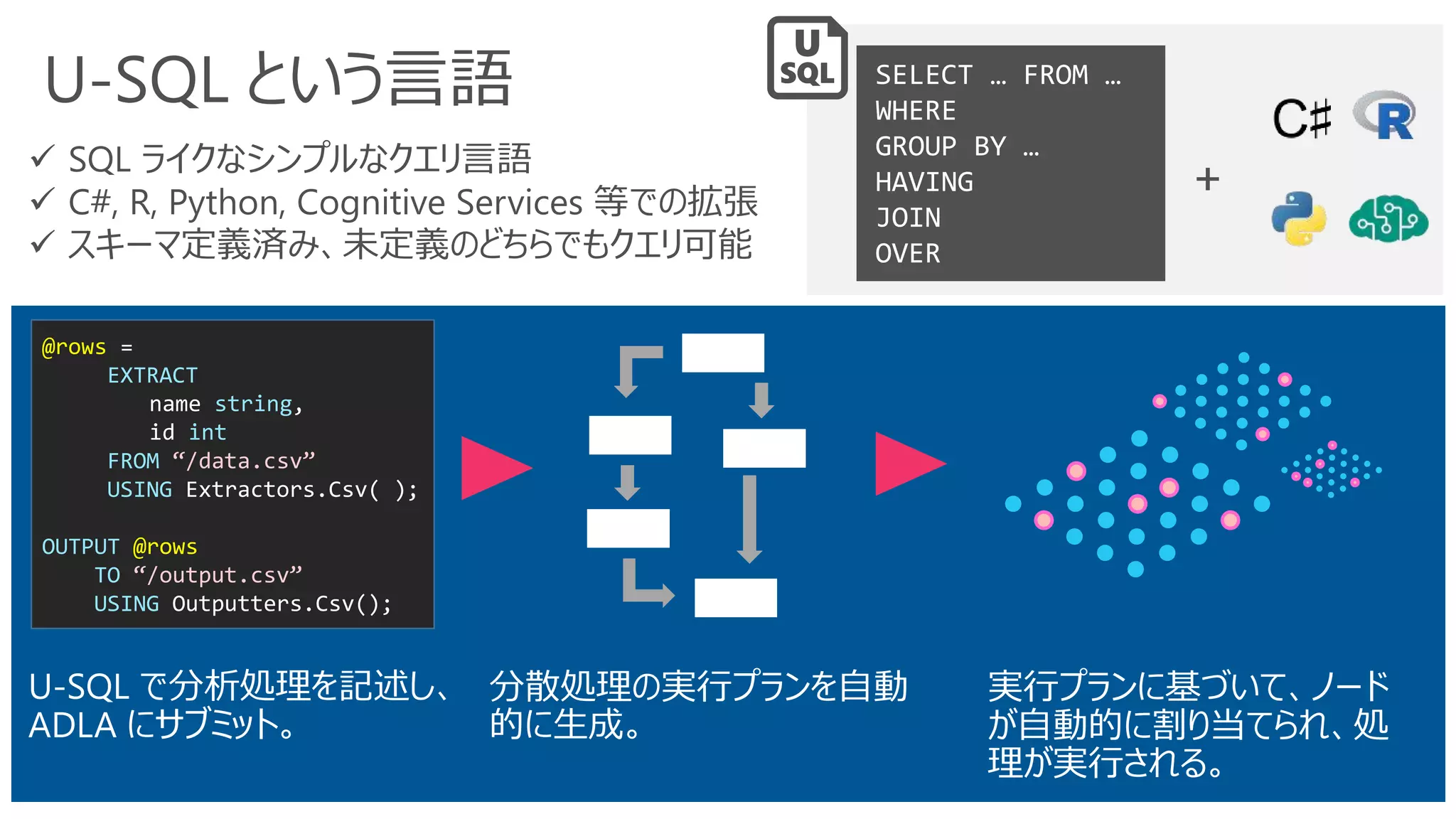
U-SQL という言語
U-SQL で分析処理を記述し、
ADLAにサブミット。
分散処理の実行プランを自動
的に生成。
実行プランに基づいて、ノード
が自動的に割り当てられ、処
理が実行される。
@rows =
EXTRACT
name string,
id int
FROM “/data.csv”
USING Extractors.Csv( );
OUTPUT @rows
TO “/output.csv”
USING Outputters.Csv();
✓ SQL ライクなシンプルなクエリ言語
✓ C#, R, Python, Cognitive Services 等での拡張
✓ スキーマ定義済み、未定義のどちらでもクエリ可能
SELECT … FROM …
WHERE
GROUP BY …
HAVING
JOIN
OVER
+
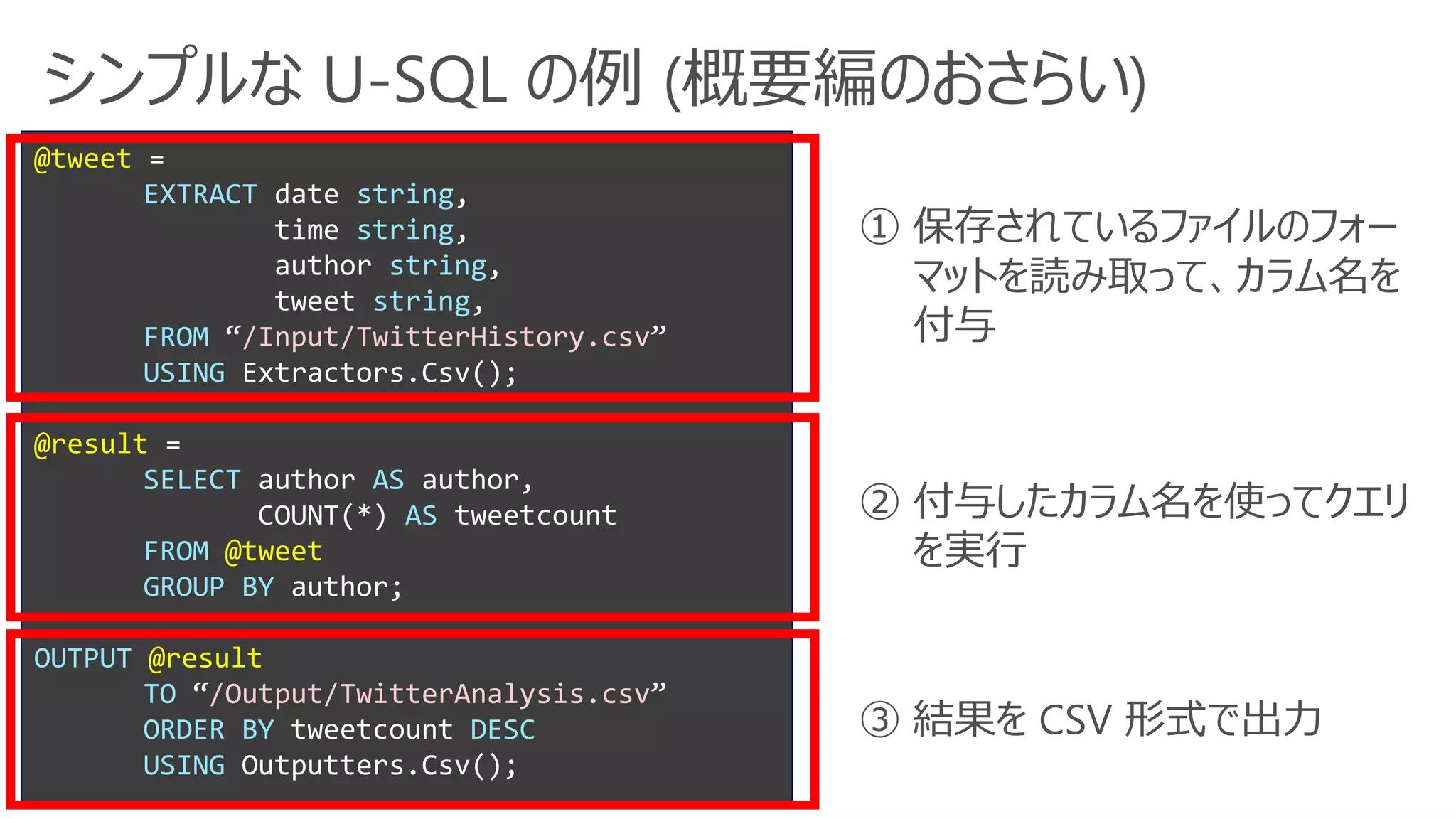
シンプルな U-SQL の例(概要編のおさらい)
@tweet =
EXTRACT date string,
time string,
author string,
tweet string,
FROM “/Input/TwitterHistory.csv”
USING Extractors.Csv();
@result =
SELECT author AS author,
COUNT(*) AS tweetcount
FROM @tweet
GROUP BY author;
OUTPUT @result
TO “/Output/TwitterAnalysis.csv”
ORDER BY tweetcount DESC
USING Outputters.Csv();
① 保存されているファイルのフォー
マットを読み取って、カラム名を
付与
② 付与したカラム名を使ってクエリ
を実行
③ 結果を CSV 形式で出力
23.
C# 関数を利用した U-SQL(概要編のおさらい)
@attribute =
SELECT new SQL.ARRAY<string>(col1.Split(',')) AS y
FROM @csv;
@country =
SELECT new SQL.ARRAY<string>(y[3].Split('=')) AS z
FROM @attribute;
@output =
SELECT
Region.ToUpper() AS NewRegion
FROM @searchlog;
文字列を大文字に変換
[col1] の中をカンマで分割
U-SQL 内で C# 関数を使用することで柔軟な処理を実行することが可能
col1 col2
name=hideo,age=50,div=tech,country=jp Microsoft
name=toshio,age=60,div=sales,country=us Microsoft
こういう CSV ファイルがあったとして
“jp”や”us”を取り出したい
4番目の要素を = で分割
→”jp” や “us” が取り出せる
24.
[ご参考] U-SQL のデータ型・集約関数・結合
ビルトインの集約関数
•AVG
• ARRAY_AGG
• COUNT
• FIRST
• LAST
• MAP_AGG
• MAX
• MIN
• STDEV
• SUM
• VAR
データ型
Numeric
byte, byte?
sbyte, sbyte?
int, int?
uint, unint?
long, long?
decimal, decimal?
short, short?
ushort, ushort?
ulong, unlong?
float, float?
double, double?
Text
char, char?
string
Complex
MAP<K>
ARRAY<K,T>
Temporal DateTime, DateTime?
Other
bool, bool?
Guid, Guid?
Byte[]
http://usql.io/
結合
• INNER JOIN
• LEFT or RIGHT or FULL OUTER JOIN
• CROSS JOIN
• SEMIJOIN
• Equivalent to IN subquery
• ANTISEMIJOIN
その他、パラメータの利用やウィンドウ関数等詳細情報やチュートリアルは左記 URL を参照
25.
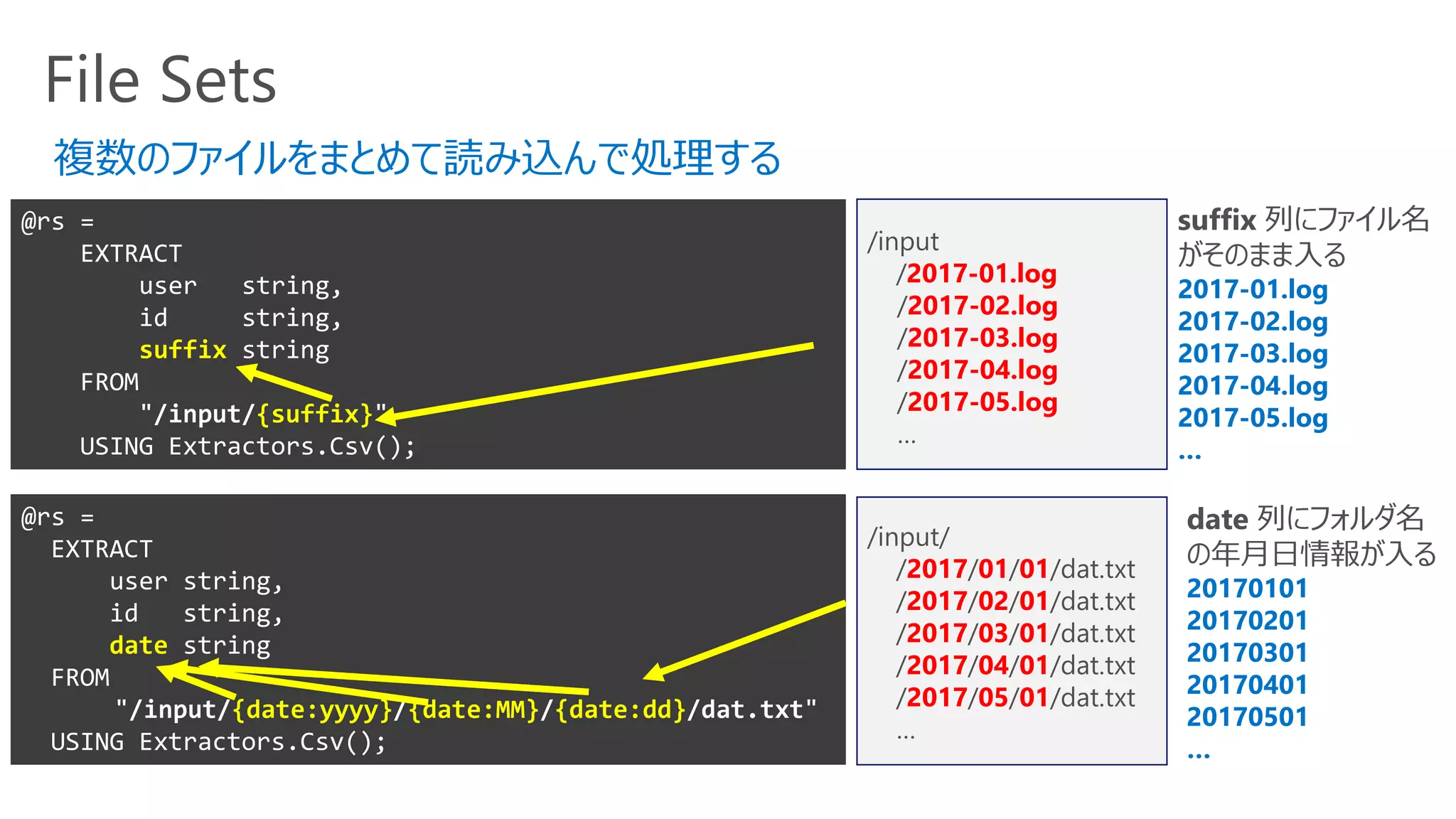
File Sets
@rs =
EXTRACT
userstring,
id string,
suffix string
FROM
"/input/{suffix}"
USING Extractors.Csv();
/input
/2017-01.log
/2017-02.log
/2017-03.log
/2017-04.log
/2017-05.log
…
@rs =
EXTRACT
user string,
id string,
date string
FROM
"/input/{date:yyyy}/{date:MM}/{date:dd}/dat.txt"
USING Extractors.Csv();
複数のファイルをまとめて読み込んで処理する
/input/
/2017/01/01/dat.txt
/2017/02/01/dat.txt
/2017/03/01/dat.txt
/2017/04/01/dat.txt
/2017/05/01/dat.txt
…
suffix 列にファイル名
がそのまま入る
2017-01.log
2017-02.log
2017-03.log
2017-04.log
2017-05.log
…
date 列にフォルダ名
の年月日情報が入る
20170101
20170201
20170301
20170401
20170501
…
26.
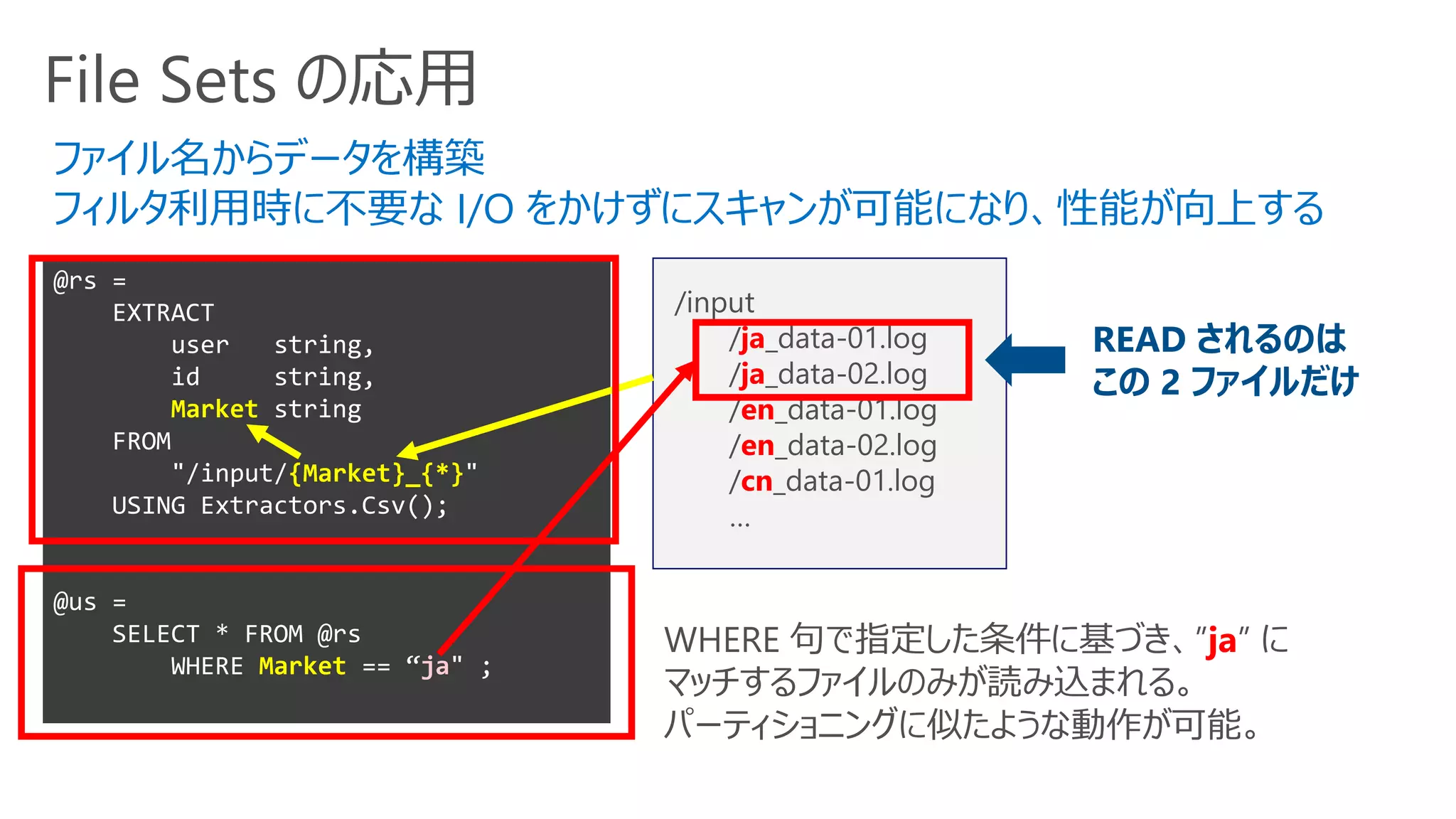
File Sets の応用
@rs=
EXTRACT
user string,
id string,
Market string
FROM
"/input/{Market}_{*}"
USING Extractors.Csv();
@us =
SELECT * FROM @rs
WHERE Market == “ja" ;
/input
/ja_data-01.log
/ja_data-02.log
/en_data-01.log
/en_data-02.log
/cn_data-01.log
…
ファイル名からデータを構築
フィルタ利用時に不要な I/O をかけずにスキャンが可能になり、性能が向上する
WHERE 句で指定した条件に基づき、”ja” に
マッチするファイルのみが読み込まれる。
パーティショニングに似たような動作が可能。
READ されるのは
この 2 ファイルだけ
27.
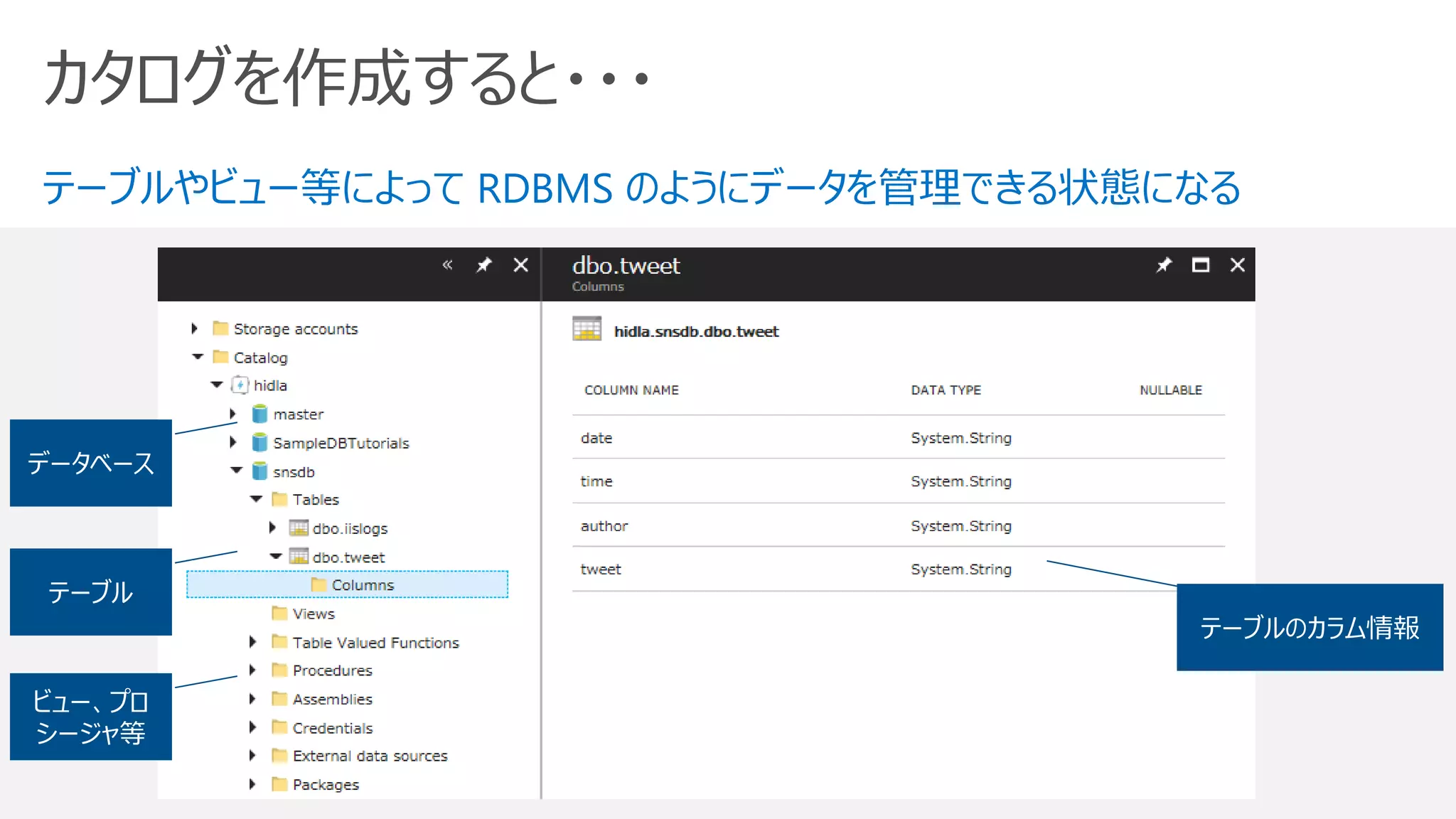
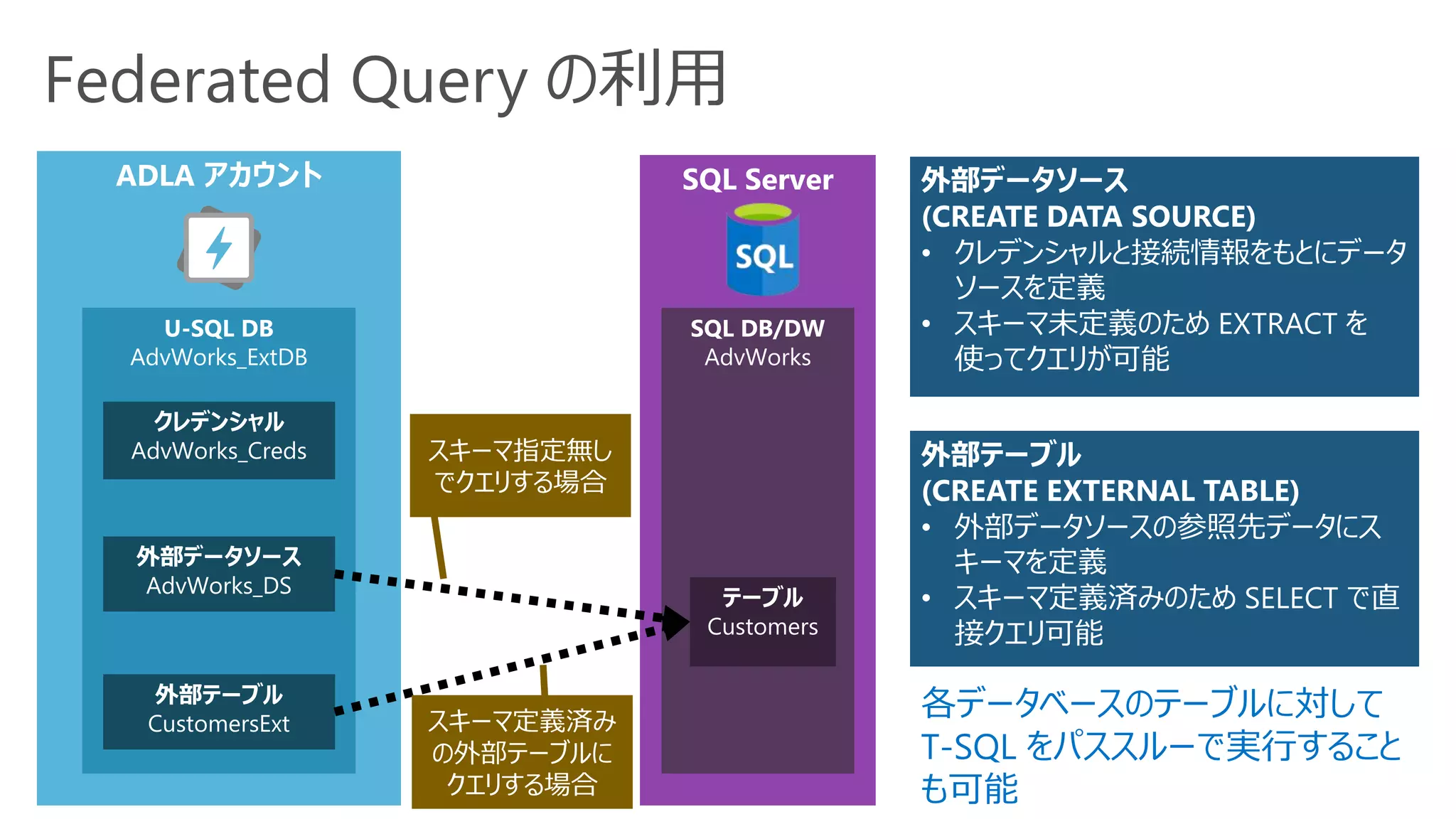
U-SQL カタログ
➢ テーブル
データを構造化し、分散配置
をコントロールすることができる
RDBMSと同様のビュー機能
テーブルデータ型の値を返す
関数
CREATE VIEW V AS EXTRACT…
CREATE VIEW V AS SELECT …
CREATE TABLE T ( … )
INDEX I CLUSTERED ( … )
DISTRIBUTED BY …;
CREATE FUNCTION F (@arg string = “default”)
RETURNS @res [TABLE ( … )]
AS BEGIN … @res … EN;
➢ ビュー
➢ テーブル値関数 (TVFs)
スキーマを定義して、データの形式を分かるようにする
例:OCR (文字認識)
REFERENCE ASSEMBLYImageCommon;
REFERENCE ASSEMBLY FaceSdk;
REFERENCE ASSEMBLY ImageEmotion;
REFERENCE ASSEMBLY ImageTagging;
REFERENCE ASSEMBLY ImageOcr;
@imgs =
EXTRACT
FileName string,
ImgData byte[]
FROM @"/images/ocr/{FileName}"
USING new Cognition.Vision.ImageExtractor();
@ocrs =
PROCESS @imgs
PRODUCE FileName,
Text string
READONLY FileName
USING new Cognition.Vision.OcrExtractor();
OUTPUT @ocrs
TO "/images/output/ocr_result.csv"
ORDER BY FileName
USING Outputters.Csv(outputHeader:true);
対象の画像ファイル
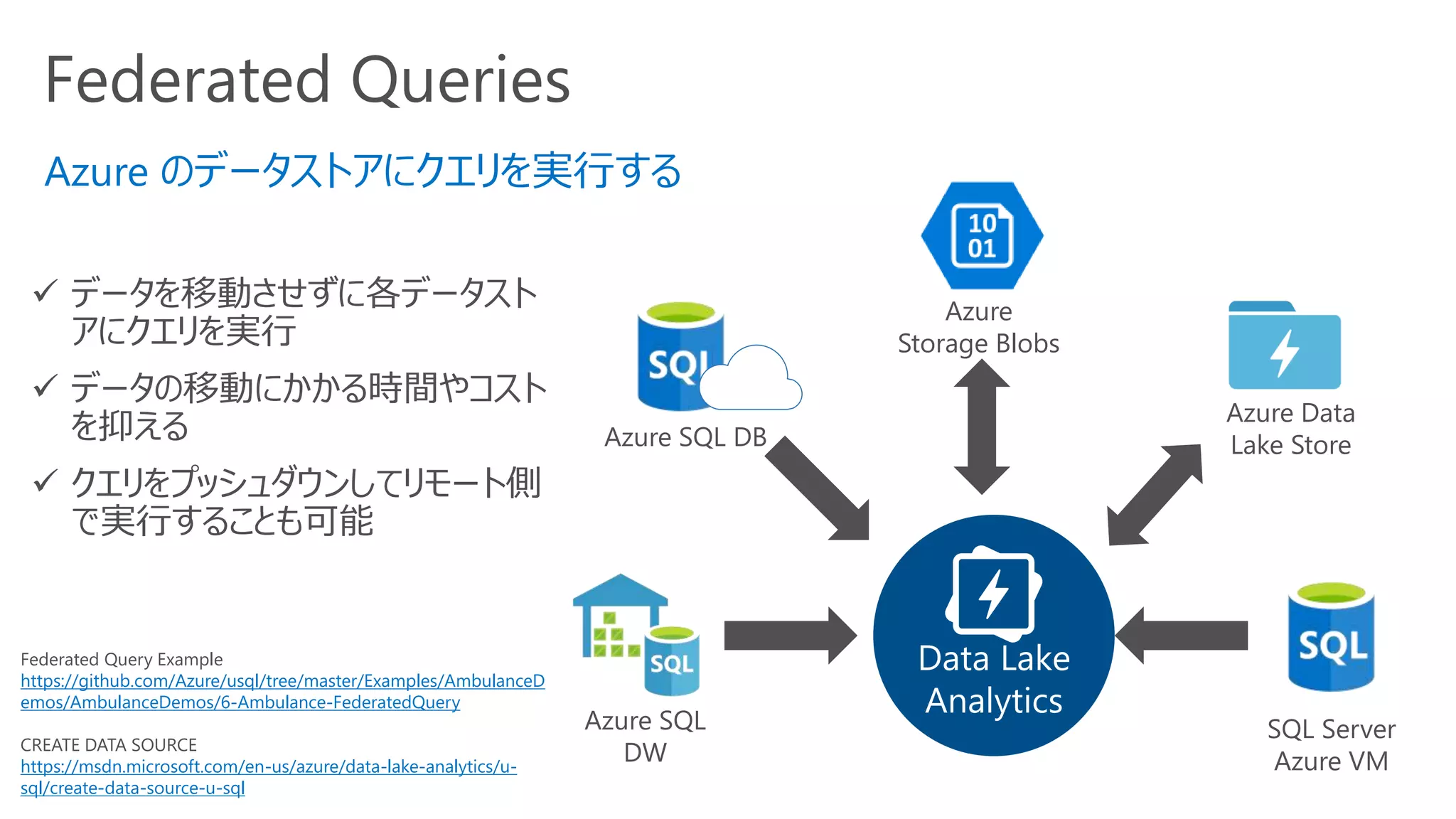
Federated Queries
Data Lake
Analytics
Azureのデータストアにクエリを実行する
✓ データを移動させずに各データスト
アにクエリを実行
✓ データの移動にかかる時間やコスト
を抑える
✓ クエリをプッシュダウンしてリモート側
で実行することも可能
Azure SQL
DW
Azure SQL DB
SQL Server
Azure VM
Azure Data
Lake Store
Azure
Storage Blobs
Federated Query Example
https://github.com/Azure/usql/tree/master/Examples/AmbulanceD
emos/AmbulanceDemos/6-Ambulance-FederatedQuery
CREATE DATA SOURCE
https://msdn.microsoft.com/en-us/azure/data-lake-analytics/u-
sql/create-data-source-u-sql
コマンドラインを使ったADLA の操作: AzureCLI
az dla job submit --account アカウント名 --job-name ジョブ名 --script U-SQL スクリプトファイル
ジョブのサブミット
az dla job show --account アカウント名 --job-identity ジョブ ID
ジョブの詳細表示
シンプルなコマンドで ADLA の操作が可能。Windows, macOS, Linux で利用可能。
az dla job list --account アカウント名
ジョブの一覧表示
https://docs.microsoft.com/ja-jp/azure/data-lake-analytics/data-lake-analytics-get-started-cli2
42.
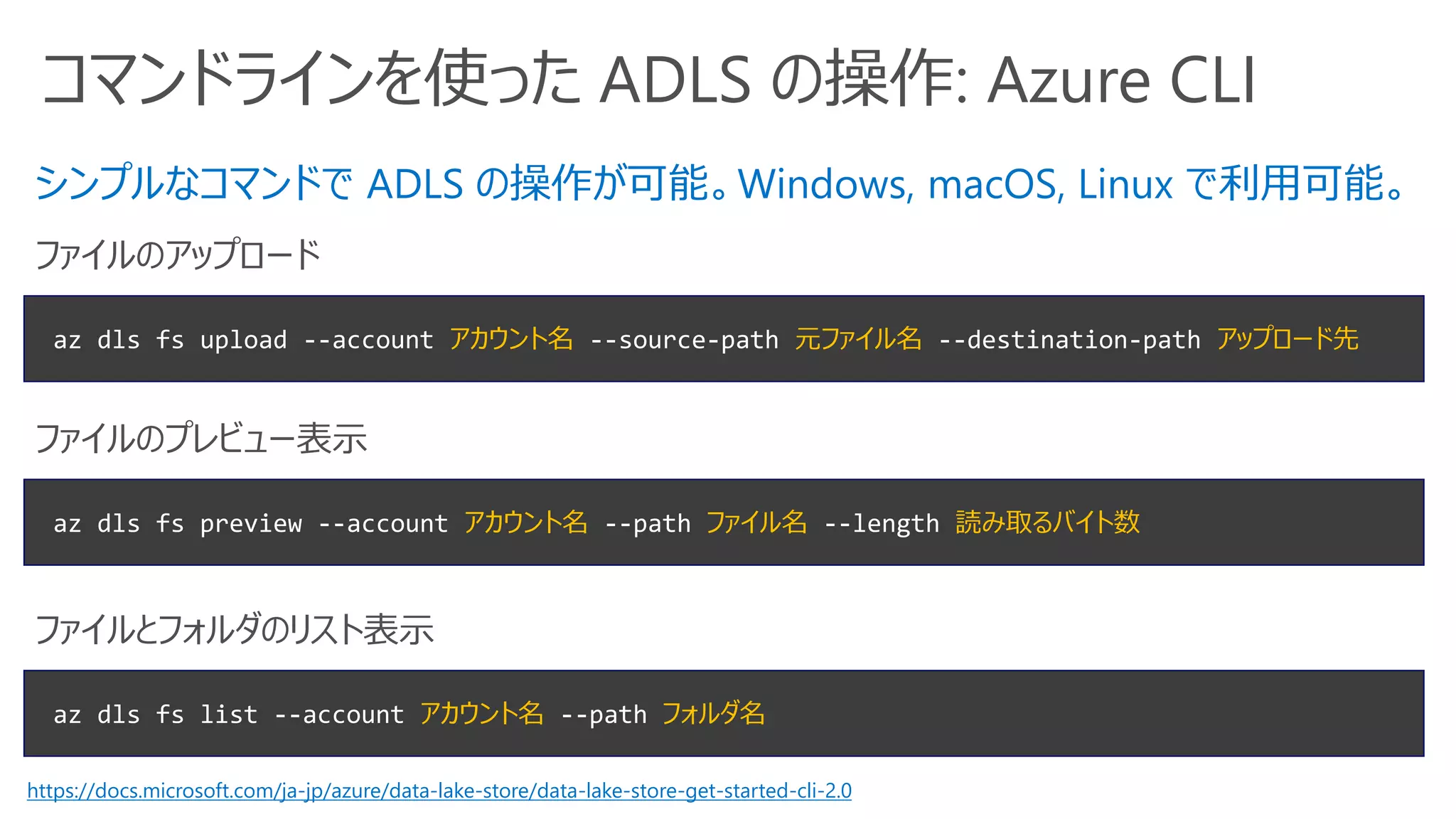
コマンドラインを使った ADLS の操作:Azure CLI
az dls fs upload --account アカウント名 --source-path 元ファイル名 --destination-path アップロード先
ファイルのアップロード
az dls fs list --account アカウント名 --path フォルダ名
ファイルとフォルダのリスト表示
シンプルなコマンドで ADLS の操作が可能。Windows, macOS, Linux で利用可能。
az dls fs preview --account アカウント名 --path ファイル名 --length 読み取るバイト数
ファイルのプレビュー表示
https://docs.microsoft.com/ja-jp/azure/data-lake-store/data-lake-store-get-started-cli-2.0
まとめ
• Azure DataLake Store / Analytics のアーキテクチャを理解する
✓ ADLS にデータを書き込むとデータが分割され、分散配置される
✓ AU の数でジョブの並列度を設定できる
✓ AU とジョブにかかった時間でコストが決まる
• U-SQL の基本を理解する
✓ U-SQL は SQL に似ているが拡張機能がある
✓ カタログ (テーブル、ビュー、テーブル値関数) で管理しやすくできる
✓ Cognitive 機能を使って画像やテキストの分析ができる
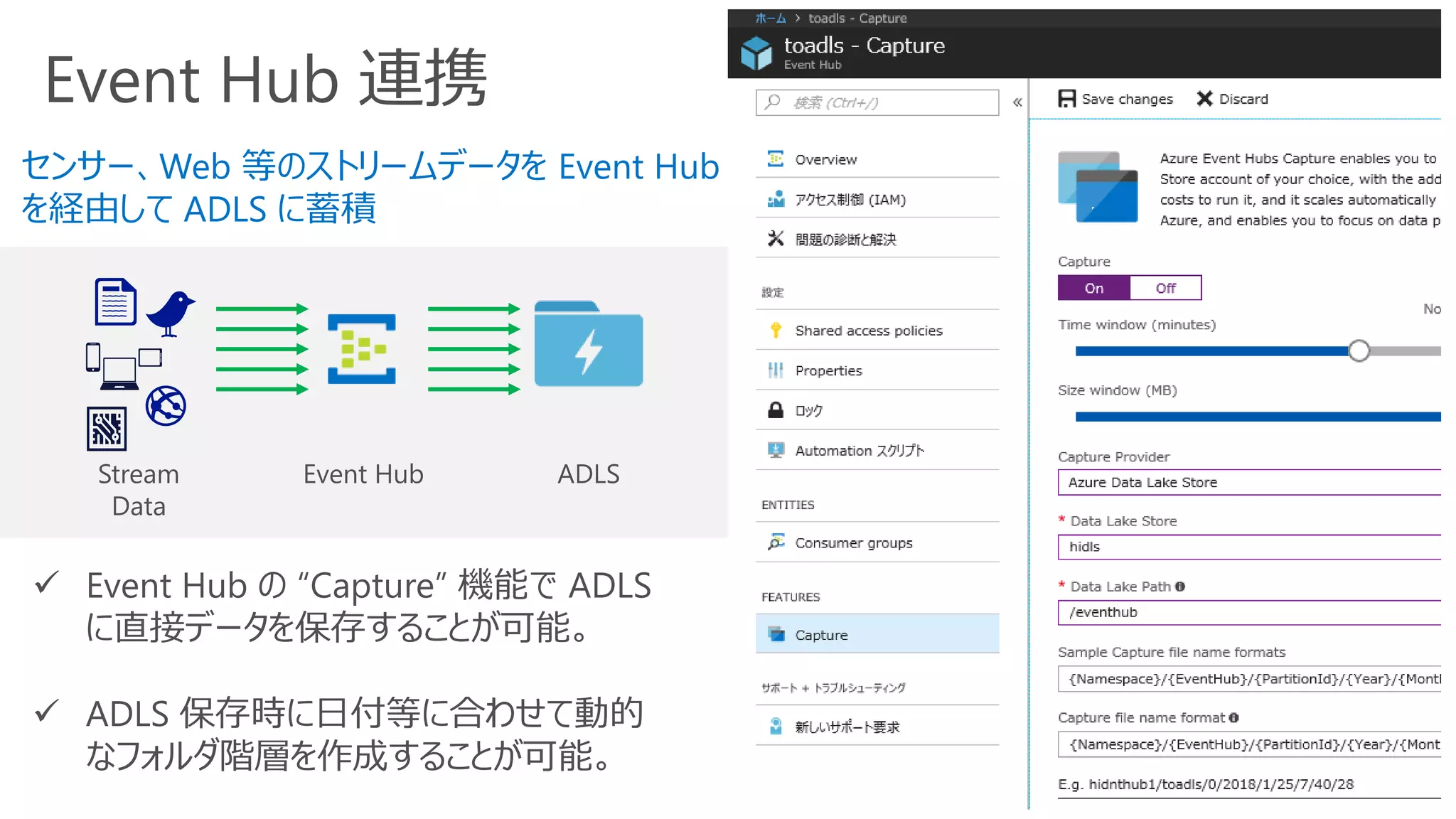
• Azure Data Lake と他のサービスとの連携方法について理解する
✓ Federated Query は Data Factory など豊富な連携方法がある
45.
参考情報
ドキュメント・ブログ
• Azure DataLake
https://azure.microsoft.com/ja-jp/solutions/data-lake/
• Azure Data Lake Blog
https://blogs.msdn.microsoft.com/azuredatalake/
• U-SQL
http://usql.io/
• Github
https://github.com/Azure/USQL
イベント セッション動画
• いざ無制限のデータの彼方へ! ~ Azure Data Lake 開発の知識とベスト プラクティス ~
https://channel9.msdn.com/Events/de-code/2016/DBP-020
• あらゆるデータをビジネスに活用! Azure Data Lake を中心としたビック データ処理基盤のアーキテクチャと実装
https://channel9.msdn.com/Events/de-code/2017/DI12
• あらゆるデータに価値がある!アンチ断捨離ストのための Azure Data Lake
https://channel9.msdn.com/Events/de-code/2017/DI07
• AI 時代を生き抜くためのビッグデータ基盤 ~リコーの実案件で見えたAzure Data Lakeの勘所~
https://youtu.be/zfD7d0Kqk_s






![Azure Data Lake の作成
[+New] -> [Data + Analytics] -> [Data Lake Analytics] から ADLS も同時に作成可能
ADLA 名
リソースグループ
リージョン
接続する ADLS
従量課金
or
コミットメント
ADLS 名
暗号化有無
従量課金
or
コミットメント](https://image.slidesharecdn.com/webinaradl20180308-180308093647/75/AI-Azure-Data-Lake-10-2048.jpg)


![AU と時間とコスト
割り当てた AU ジョブにかかった時間 AU 時間
a-1 10 3 時間 30 AU 時間
a-2 20 1.5 時間 30 AU 時間
a. AU を増やしたほうが良いケース
割り当てた AU ジョブにかかった時間 AU 時間
b-1 10 5 時間 50 AU 時間
b-2 20 4 時間 80 AU 時間
b. AU を増やすか検討が必要なケース
同じ金額でジョブの時間
を半分に短縮できる
→増やす!
60 % のコスト増で 1 時
間のジョブ時間短縮
→増やす?
ADLA の料金 = [割り当てた AU の数] x [時間] (x [単価])](https://image.slidesharecdn.com/webinaradl20180308-180308093647/75/AI-Azure-Data-Lake-17-2048.jpg)


![スキーマ オン リード
abe, 95, 46, 85, 85
itoh, 89, 72, 46, 76, 34
ueda, 95, 13, 57, 63, 87
emoto, 50, 68, 38, 85, 98
otsuka, 13, 16, 67, 100, 7
katase, 42, 61, 90, 11, 33
{"name" : "cat", "count" : 105}
{"name" : "dog", "count" : 81}
{"name" : "rabbit", "count" : 2030}
{"name" : "turtle", "count" : 1550}
{"name" : "tiger", "count" : 300}
{"name" : "lion", "count" : 533}
{"name" : "whale", "count" : 2934}
xxx.xxx.xxx.xxx - -
[27/Jan/2018:14:20:17 +0000]
"GET /item/giftcards/3720
HTTP/1.1" 200 70 "-" "Mozilla/5.0
(Windows NT 6.1; WOW64;
rv:10.0.1) Gecko/20100101
Firefox/10.0.1"
フォーマットを気にせ
ずデータをためていく
使うときにはじめて
データ構造を意識
@rows = EXTRACT ~~~ FROM ~~~ USING ~~~;
@rows = SELECT ~~~ FROM ~~~ WHERE ~~~;
データを集めてためておく
使うときにデータ構造を定義して処理する](https://image.slidesharecdn.com/webinaradl20180308-180308093647/75/AI-Azure-Data-Lake-21-2048.jpg)
![C# 関数を利用した U-SQL (概要編のおさらい)
@attribute =
SELECT new SQL.ARRAY<string>(col1.Split(',')) AS y
FROM @csv;
@country =
SELECT new SQL.ARRAY<string>(y[3].Split('=')) AS z
FROM @attribute;
@output =
SELECT
Region.ToUpper() AS NewRegion
FROM @searchlog;
文字列を大文字に変換
[col1] の中をカンマで分割
U-SQL 内で C# 関数を使用することで柔軟な処理を実行することが可能
col1 col2
name=hideo,age=50,div=tech,country=jp Microsoft
name=toshio,age=60,div=sales,country=us Microsoft
こういう CSV ファイルがあったとして
“jp”や”us”を取り出したい
4番目の要素を = で分割
→”jp” や “us” が取り出せる](https://image.slidesharecdn.com/webinaradl20180308-180308093647/75/AI-Azure-Data-Lake-23-2048.jpg)
![[ご参考] U-SQL のデータ型・集約関数・結合
ビルトインの集約関数
• AVG
• ARRAY_AGG
• COUNT
• FIRST
• LAST
• MAP_AGG
• MAX
• MIN
• STDEV
• SUM
• VAR
データ型
Numeric
byte, byte?
sbyte, sbyte?
int, int?
uint, unint?
long, long?
decimal, decimal?
short, short?
ushort, ushort?
ulong, unlong?
float, float?
double, double?
Text
char, char?
string
Complex
MAP<K>
ARRAY<K,T>
Temporal DateTime, DateTime?
Other
bool, bool?
Guid, Guid?
Byte[]
http://usql.io/
結合
• INNER JOIN
• LEFT or RIGHT or FULL OUTER JOIN
• CROSS JOIN
• SEMIJOIN
• Equivalent to IN subquery
• ANTISEMIJOIN
その他、パラメータの利用やウィンドウ関数等詳細情報やチュートリアルは左記 URL を参照](https://image.slidesharecdn.com/webinaradl20180308-180308093647/75/AI-Azure-Data-Lake-24-2048.jpg)
![U-SQL カタログ
➢ テーブル
データを構造化し、分散配置
をコントロールすることができる
RDBMS と同様のビュー機能
テーブルデータ型の値を返す
関数
CREATE VIEW V AS EXTRACT…
CREATE VIEW V AS SELECT …
CREATE TABLE T ( … )
INDEX I CLUSTERED ( … )
DISTRIBUTED BY …;
CREATE FUNCTION F (@arg string = “default”)
RETURNS @res [TABLE ( … )]
AS BEGIN … @res … EN;
➢ ビュー
➢ テーブル値関数 (TVFs)
スキーマを定義して、データの形式を分かるようにする](https://image.slidesharecdn.com/webinaradl20180308-180308093647/75/AI-Azure-Data-Lake-27-2048.jpg)

![例:画像の内容を読み取ってタグ付けする
REFERENCE ASSEMBLY ImageCommon;
REFERENCE ASSEMBLY FaceSdk;
REFERENCE ASSEMBLY ImageEmotion;
REFERENCE ASSEMBLY ImageTagging;
REFERENCE ASSEMBLY ImageOcr;
@imgs =
EXTRACT
FileName string,
ImgData byte[]
FROM @"/images/{FileName}.png"
USING new Cognition.Vision.ImageExtractor();
@tags =
PROCESS @imgs
PRODUCE FileName,
NumObjects int,
Tags SQL.MAP<string, float?>
READONLY FileName
USING new Cognition.Vision.ImageTagger();
@tags_serialized =
SELECT FileName,
NumObjects,
String.Join(";", Tags.Select(x => String.Format("{0}:{1}", x.Key,
x.Value))) AS TagsString
FROM @tags;
OUTPUT @tags_serialized
TO "/images/output/tags.csv"
USING Outputters.Csv(outputHeader:true);
対象の画像ファイル](https://image.slidesharecdn.com/webinaradl20180308-180308093647/75/AI-Azure-Data-Lake-30-2048.jpg)
![例:画像の内容を読み取ってタグ付けする [結果]](https://image.slidesharecdn.com/webinaradl20180308-180308093647/75/AI-Azure-Data-Lake-31-2048.jpg)
![例:OCR (文字認識)
REFERENCE ASSEMBLY ImageCommon;
REFERENCE ASSEMBLY FaceSdk;
REFERENCE ASSEMBLY ImageEmotion;
REFERENCE ASSEMBLY ImageTagging;
REFERENCE ASSEMBLY ImageOcr;
@imgs =
EXTRACT
FileName string,
ImgData byte[]
FROM @"/images/ocr/{FileName}"
USING new Cognition.Vision.ImageExtractor();
@ocrs =
PROCESS @imgs
PRODUCE FileName,
Text string
READONLY FileName
USING new Cognition.Vision.OcrExtractor();
OUTPUT @ocrs
TO "/images/output/ocr_result.csv"
ORDER BY FileName
USING Outputters.Csv(outputHeader:true);
対象の画像ファイル](https://image.slidesharecdn.com/webinaradl20180308-180308093647/75/AI-Azure-Data-Lake-32-2048.jpg)
![例:OCR (文字認識) [結果]](https://image.slidesharecdn.com/webinaradl20180308-180308093647/75/AI-Azure-Data-Lake-33-2048.jpg)






![【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [実践編]](https://image.slidesharecdn.com/webinaradl20180308-180308093647/75/AI-Azure-Data-Lake-47-2048.jpg)

![【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [概要編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinaradl20180215-180219043331-thumbnail.jpg?width=640&height=640&fit=bounds)

![【ウェブ セミナー】AI 時代のクラウド データ ウェアハウス Azure SQL Data Warehouse [実践編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinarsqldw20170726-180220004900-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DI07] あらゆるデータに価値がある! アンチ断捨離ストのための Azure Data Lake](https://cdn.slidesharecdn.com/ss_thumbnails/di07-170605024557-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DI03] DWH スペシャリストが語る! Azure SQL Data Warehouse チューニングの勘所](https://cdn.slidesharecdn.com/ss_thumbnails/di03-170605023803-thumbnail.jpg?width=640&height=640&fit=bounds)










![[db tech showcase Tokyo 2017] AzureでOSS DB/データ処理基盤のPaaSサービスを使ってみよう (Azure Dat...](https://cdn.slidesharecdn.com/ss_thumbnails/20170907dbtechshowcaseazureossdb-170907082746-thumbnail.jpg?width=640&height=640&fit=bounds)


![[db tech showcase Tokyo 2017] E23: クラウド異種データベース(AWS)へのデータベース移行時の注意点 ~レプリケーション...](https://cdn.slidesharecdn.com/ss_thumbnails/e23-170912023826-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DI08] その情報うまく取り出せていますか? ~ 意外と簡単、Azure Search で短時間で検索精度と利便性を向上させるための方法](https://cdn.slidesharecdn.com/ss_thumbnails/di08-170605024559-thumbnail.jpg?width=640&height=640&fit=bounds)






















