Downloaded 57 times


























![© 2017 IBM Corporation47
SPARK Tuning
Spark Setting Default 10TB 100TB
spark.rpc.askTimeout (s) 120 1200 36000
spark.kryoserializer.buffer.max (mb) 64 768 768
spark.yarn.executor.memoryOverhead (mb) 384 1384 8192
spark.driver.maxResultSize 1G 8G 40G
spark.local.dir /tmp /data[1-10]/tmp /data[1-10]/tmp
spark.network.timeout 120 1200 36000
spark.sql.broadcastTimeout 120 1600 36000
spark.buffer.pageSize computed computed 64m
spark.shuffle.file.buffer computed computed 512k
spark.memory.fraction 0.6 0.8 0.8
spark.scheduler.listenerbus.eventqueue.size 10K 120K 600K](https://image.slidesharecdn.com/simonharrisbreachingthe100tbmarkwithsqloverhadoop-170925185445/75/Breaching-the-100TB-Mark-with-SQL-Over-Hadoop-47-2048.jpg)

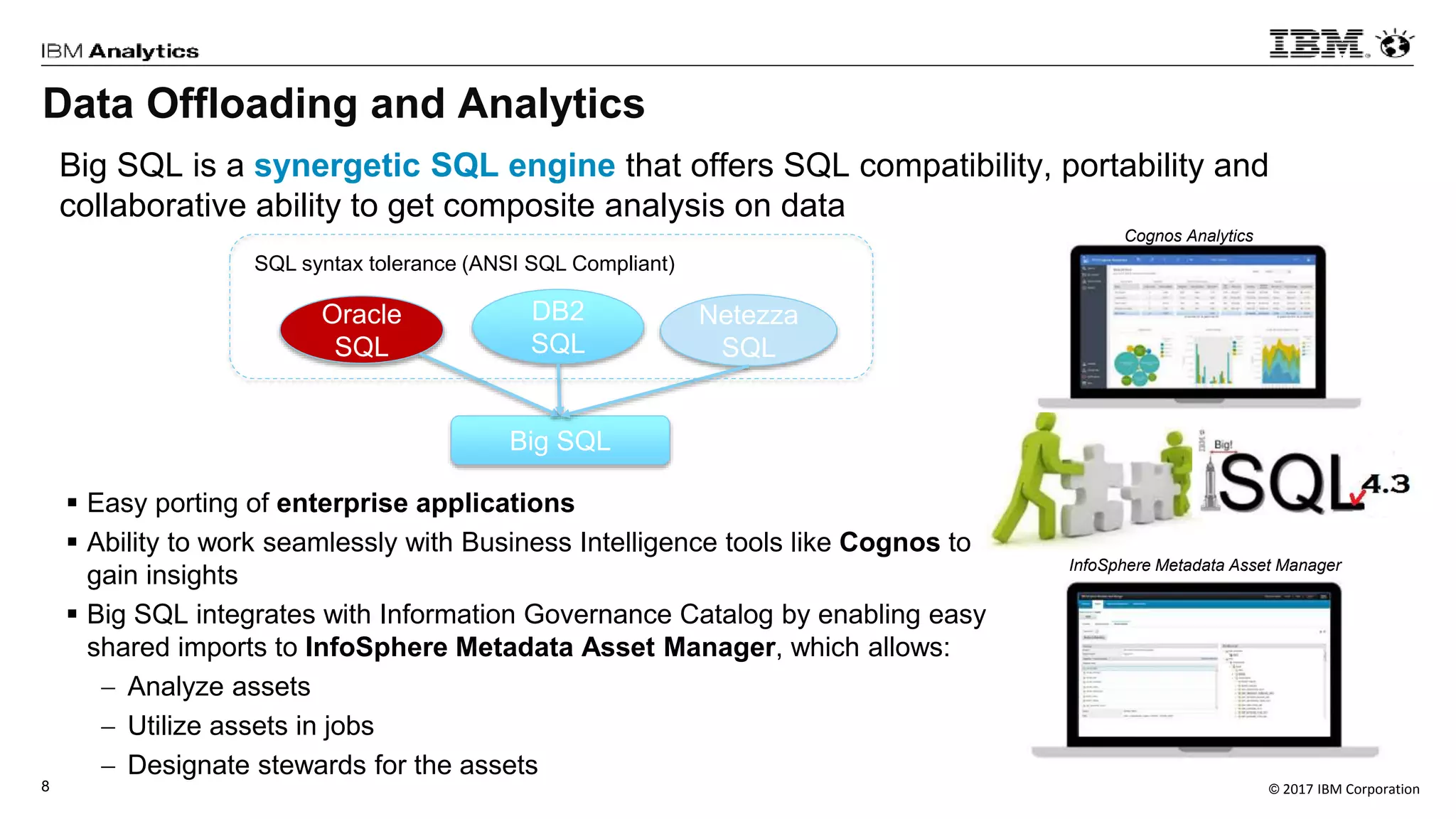
IBM's Big SQL is a SQL-on-Hadoop solution designed to optimize enterprise data warehouse workloads by supporting SQL syntax from various vendors like Oracle and DB2, enabling seamless querying and integration across multiple data sources. It is capable of efficiently handling complex queries, providing high performance and security features such as role-based access control. The performance benchmarks highlight Big SQL's superiority, demonstrating significant efficiency gains compared to other SQL solutions, especially in high-concurrency scenarios.






















































































