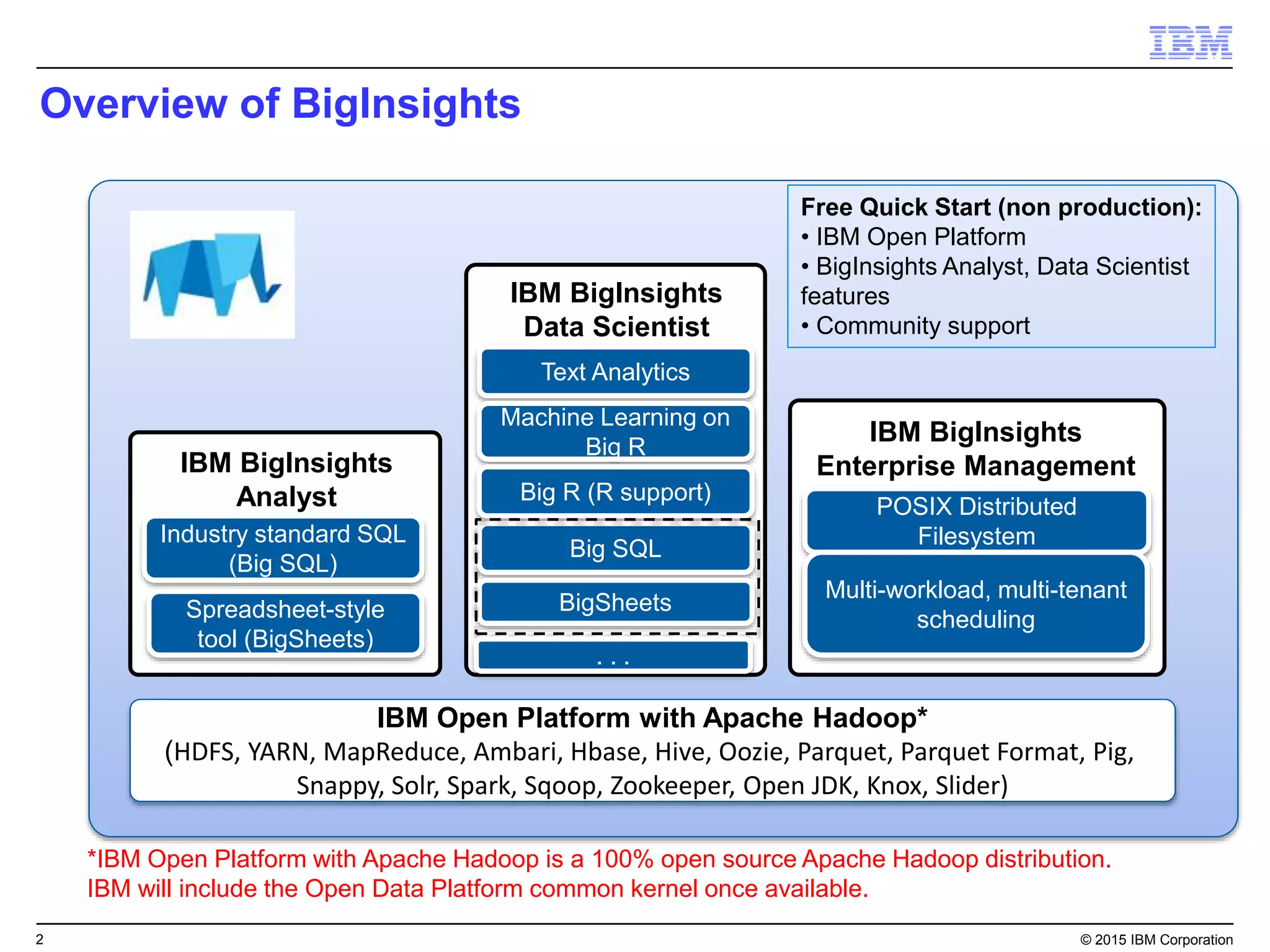
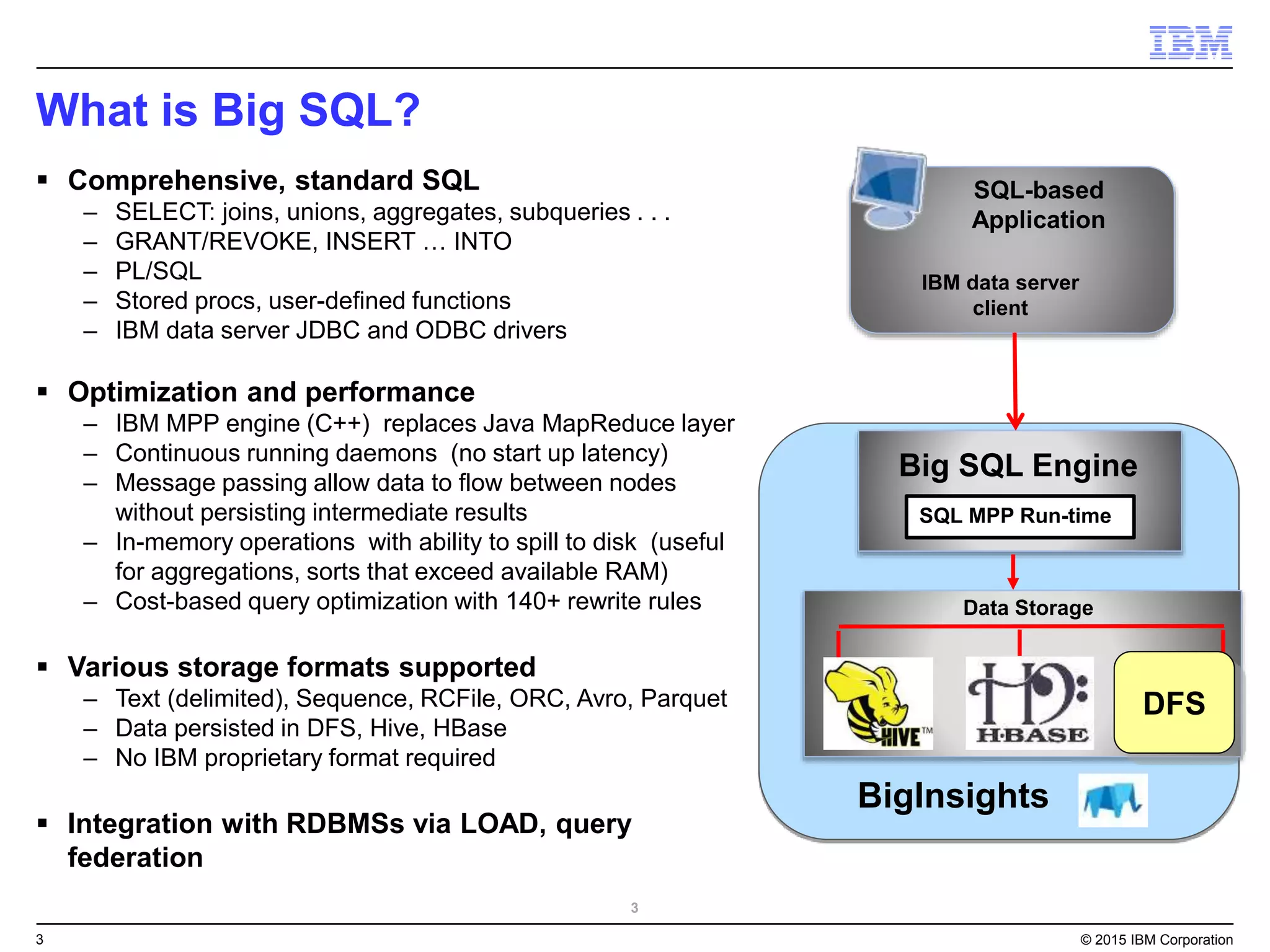
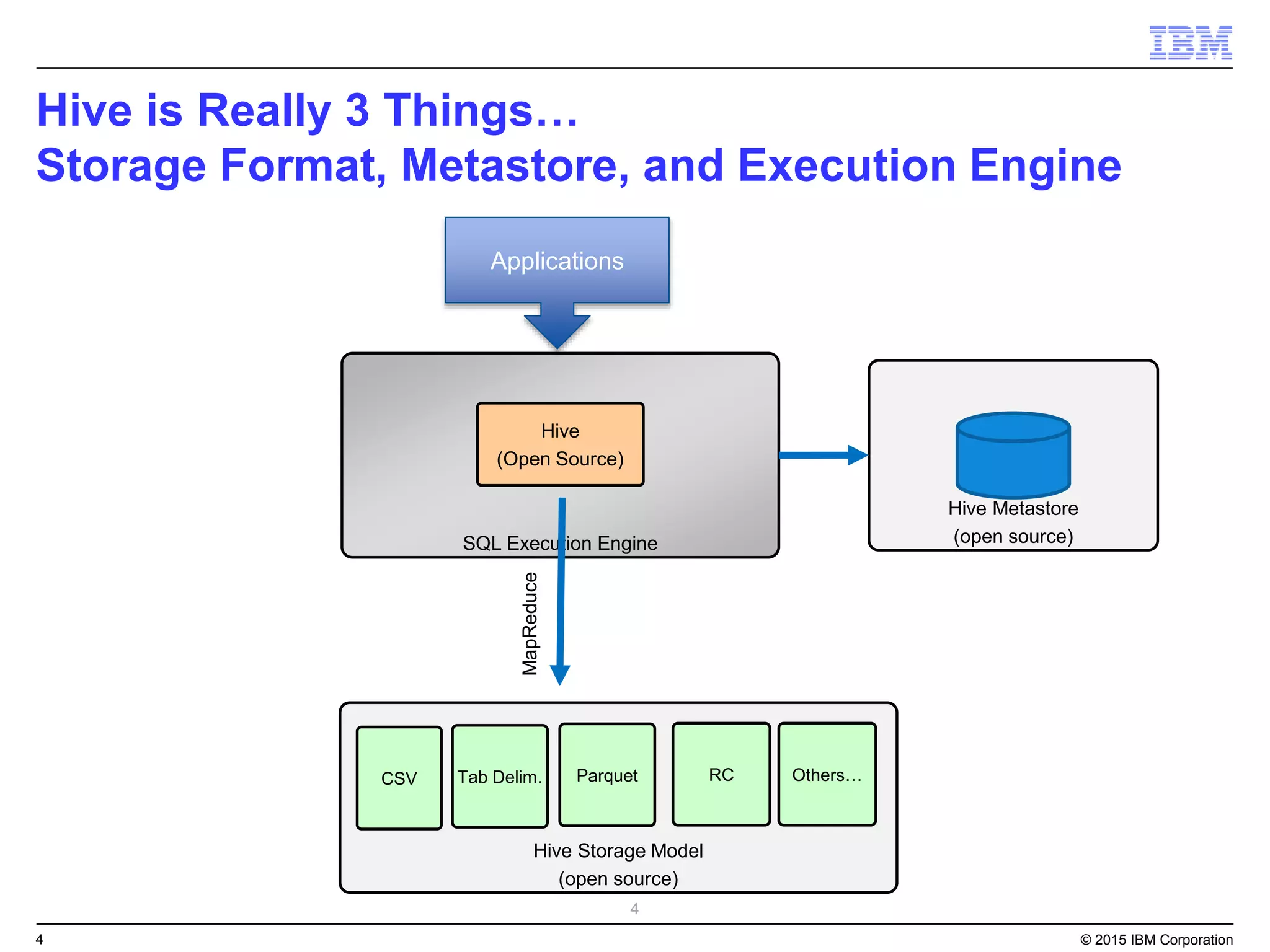
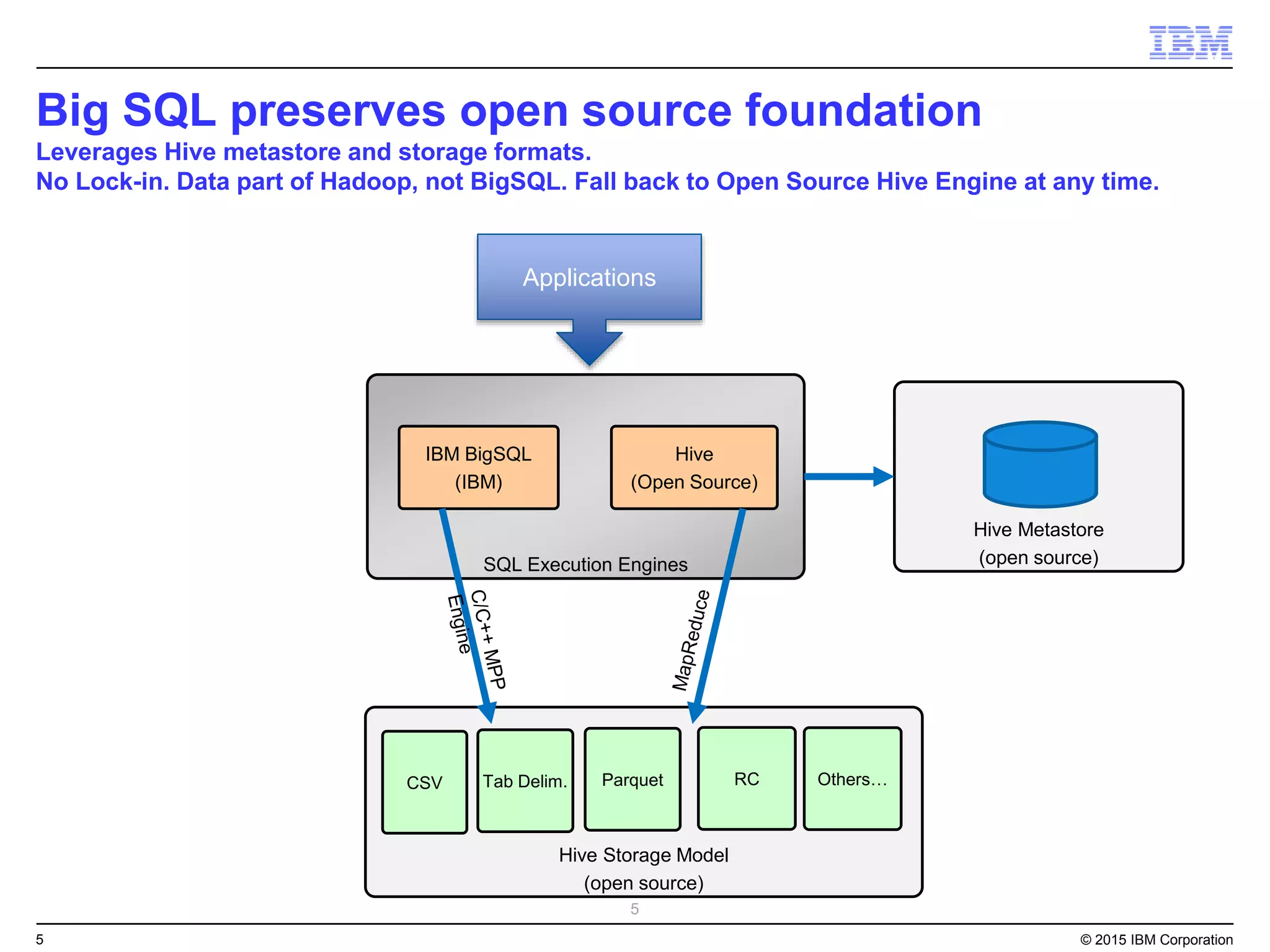
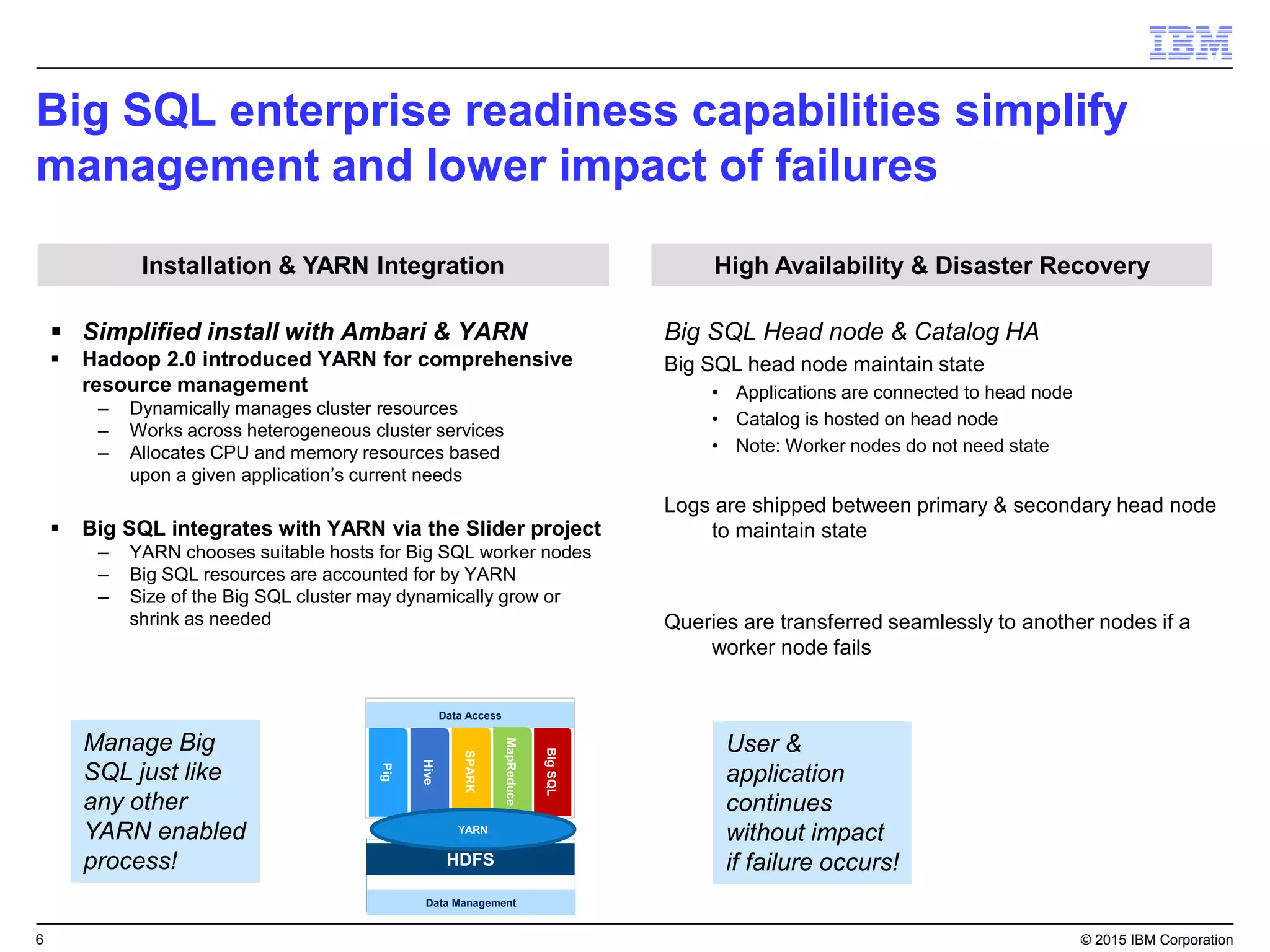
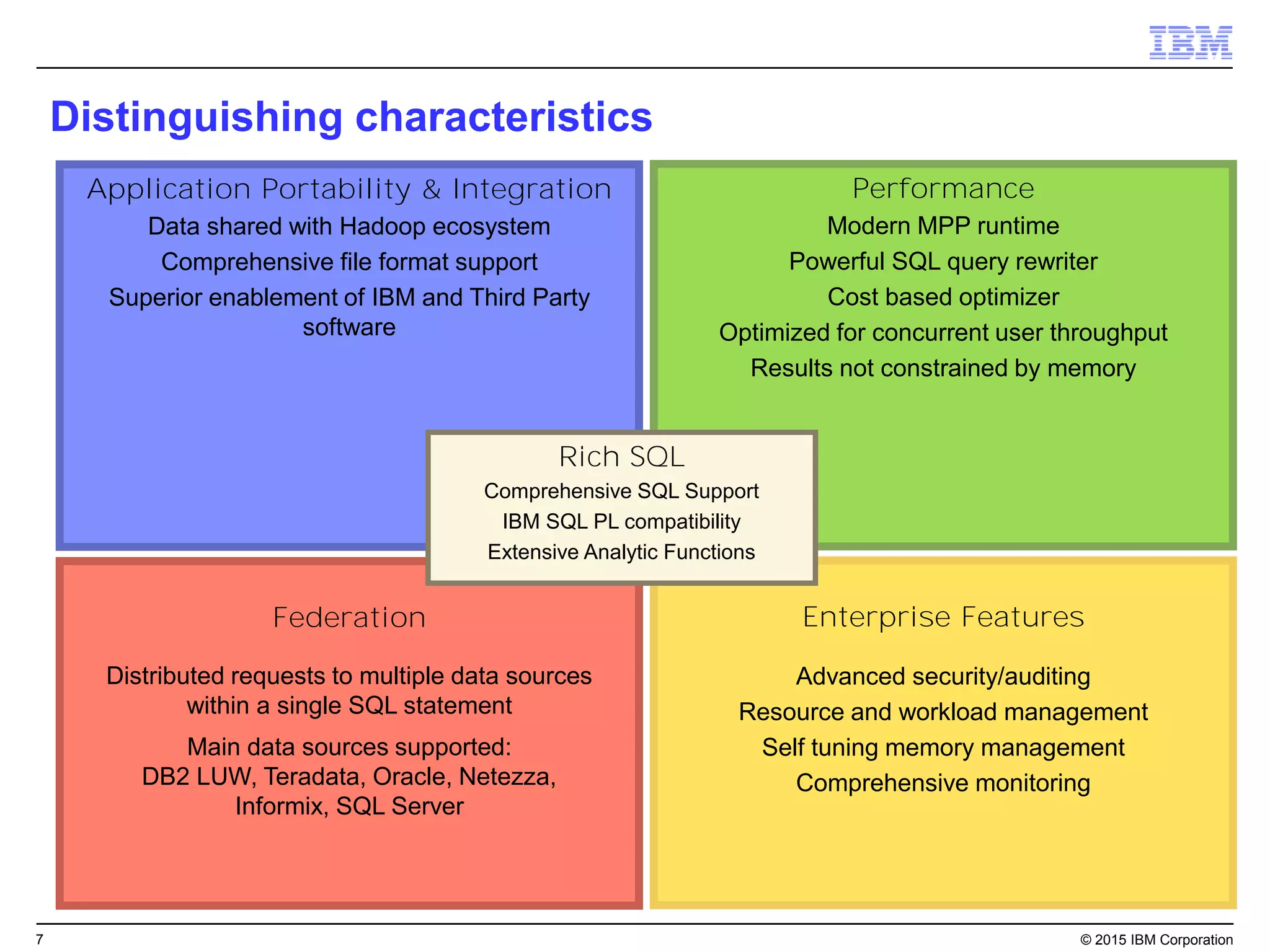
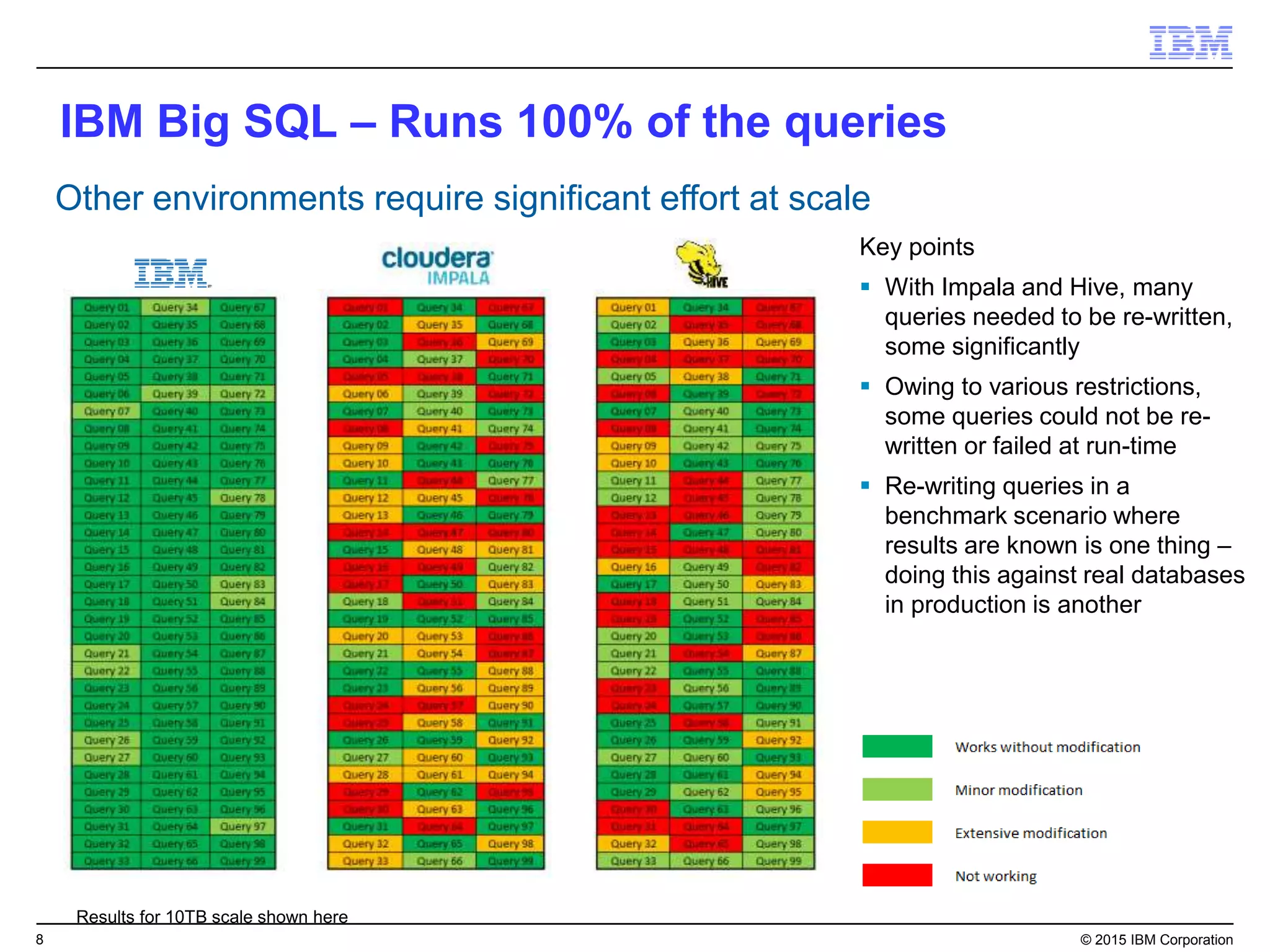
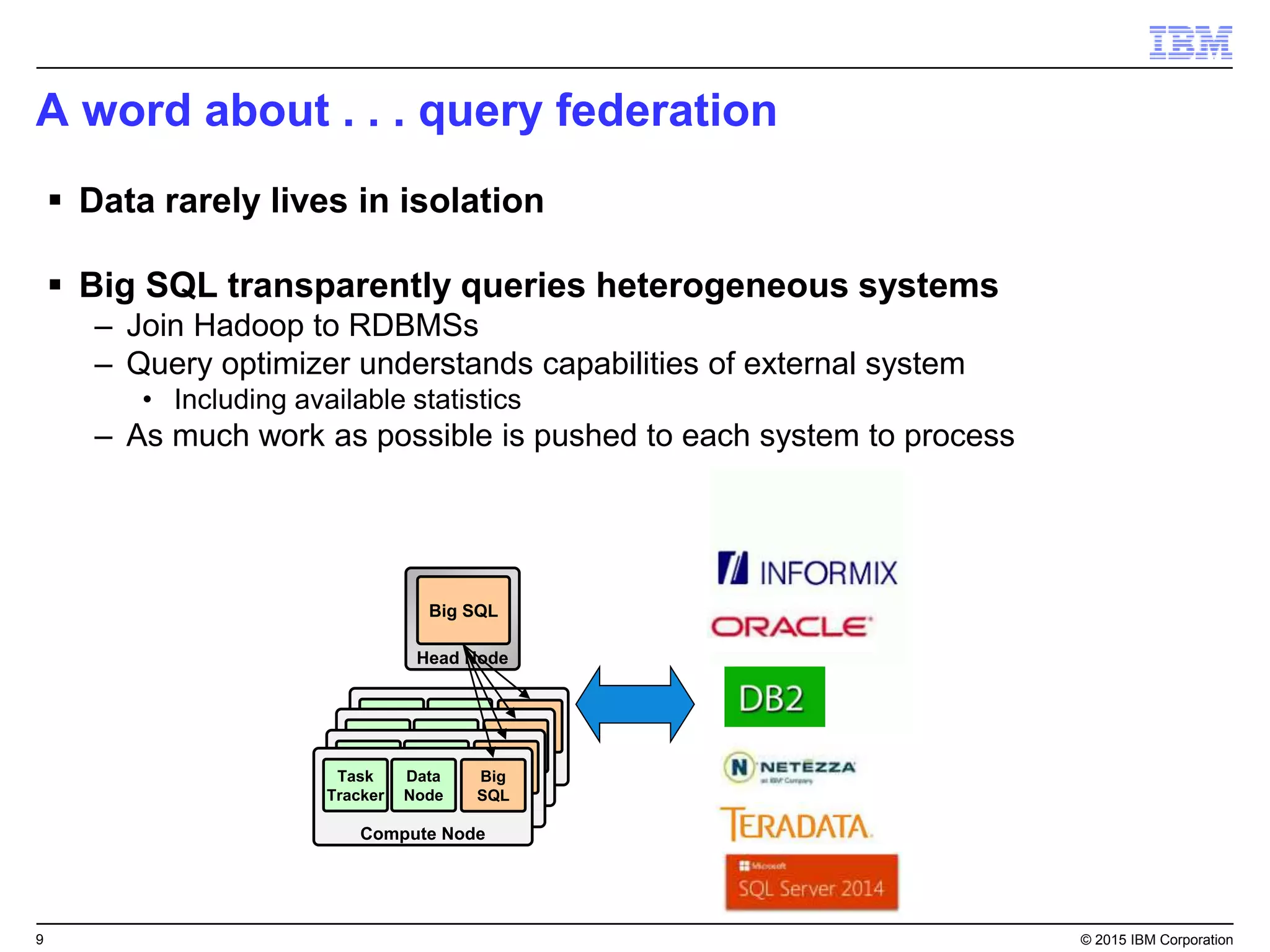
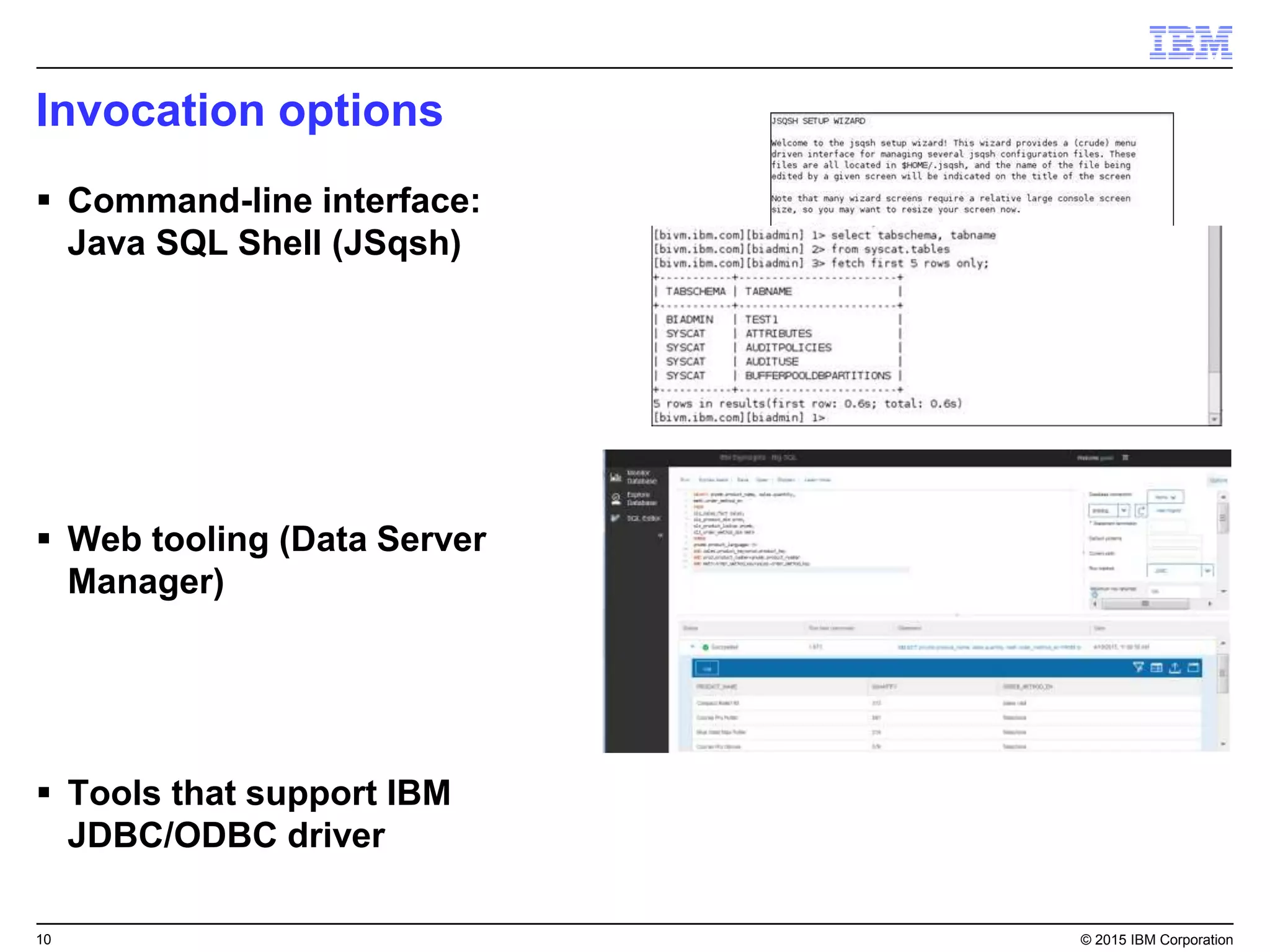
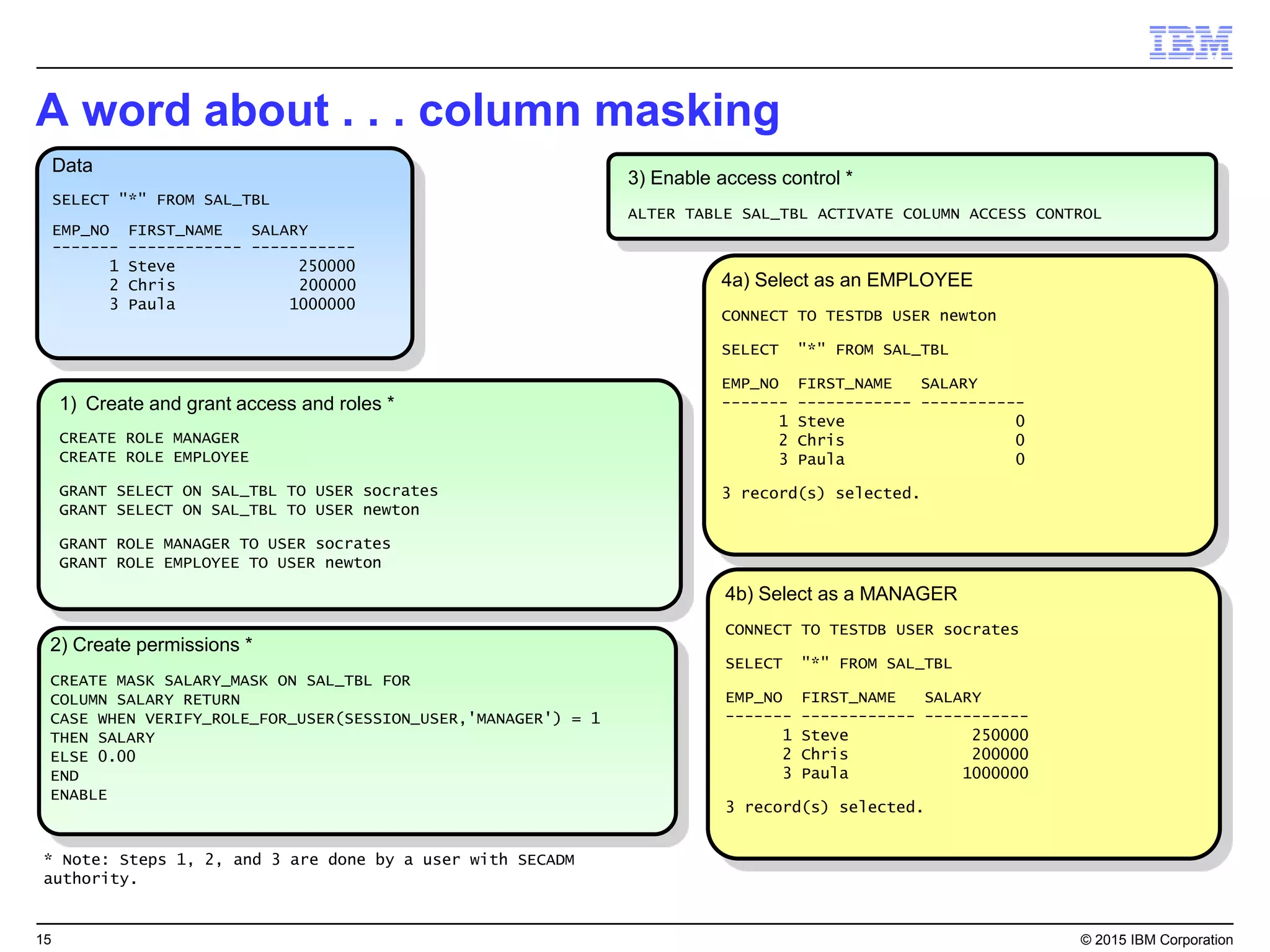
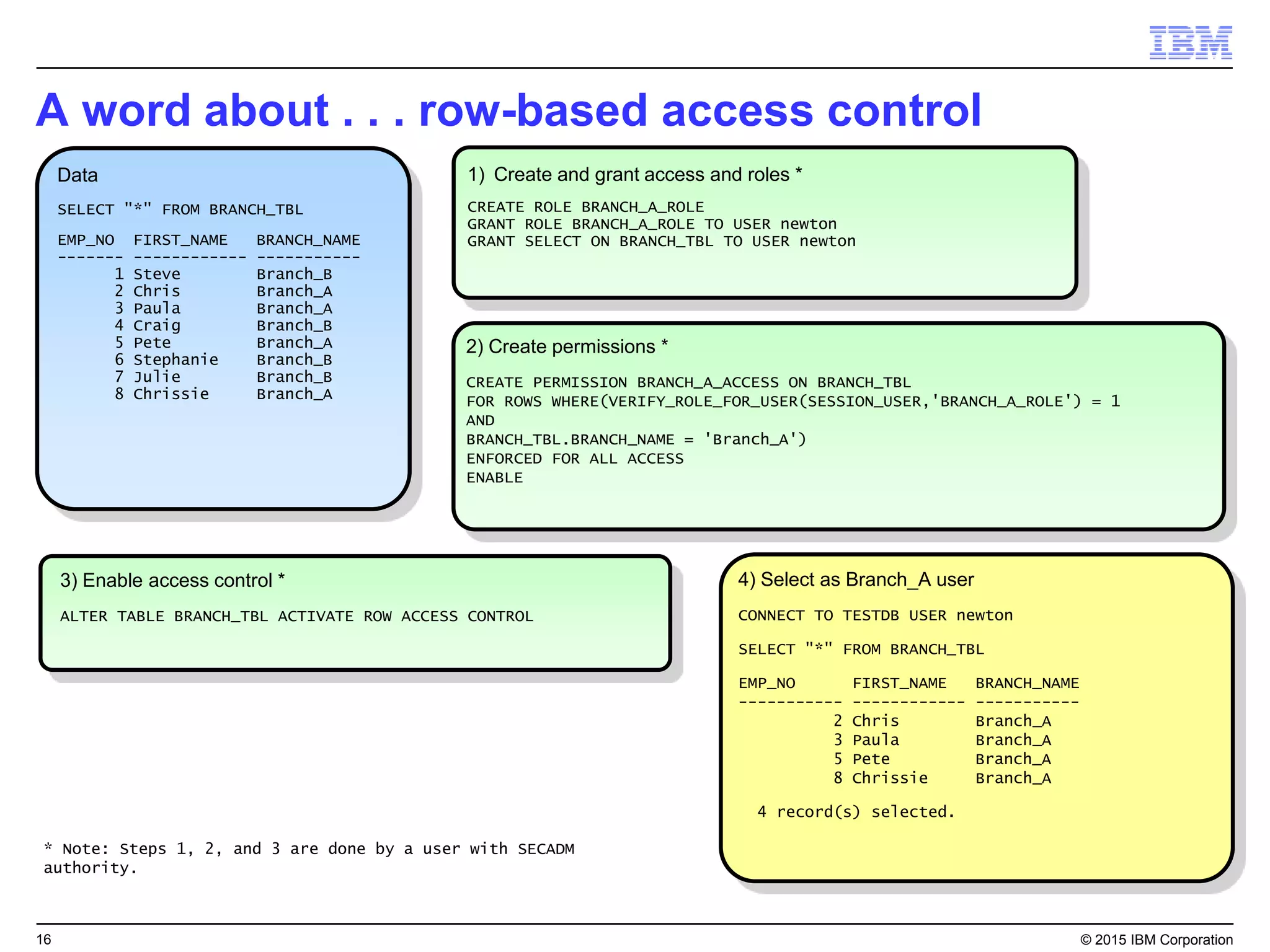
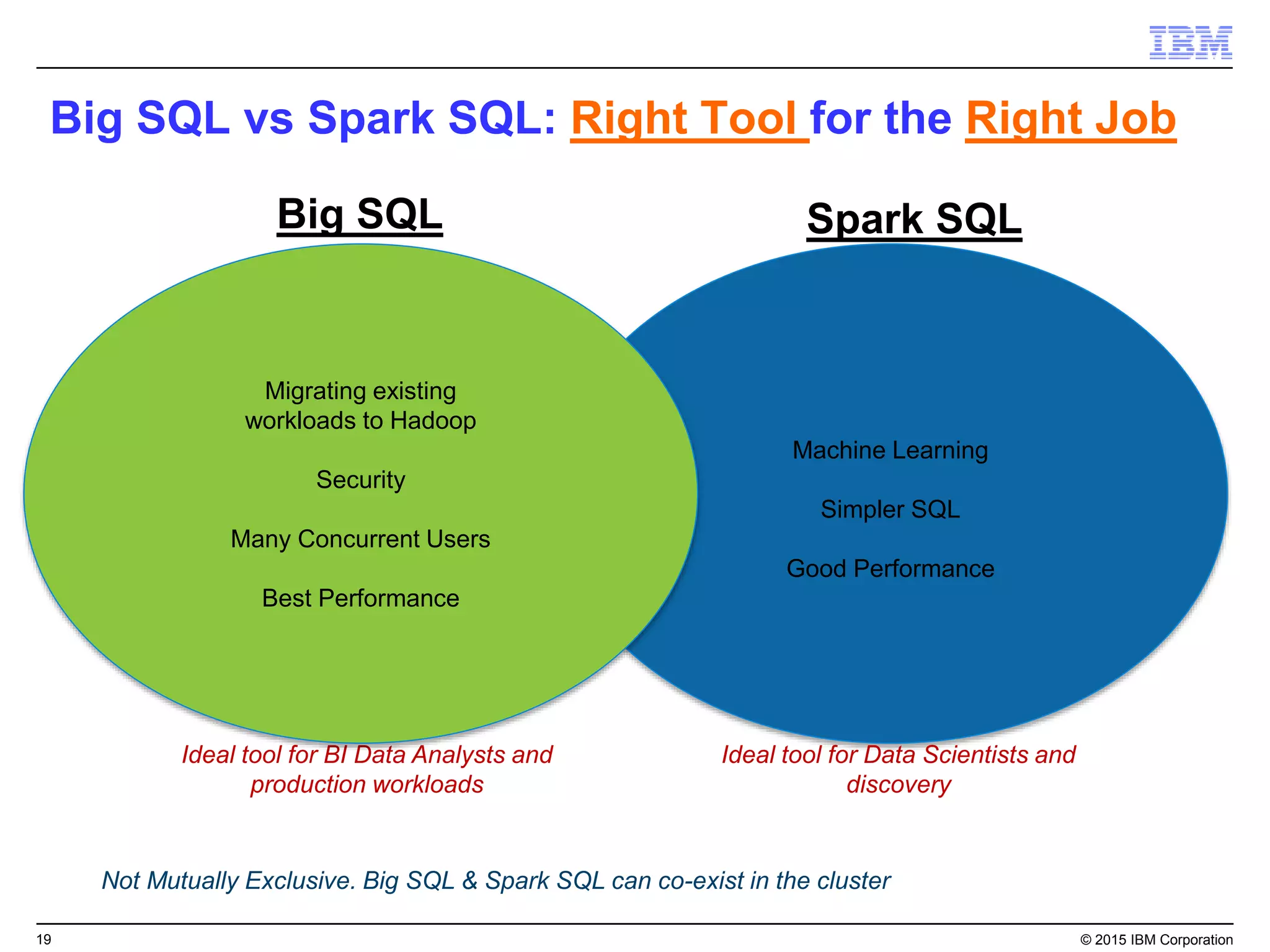
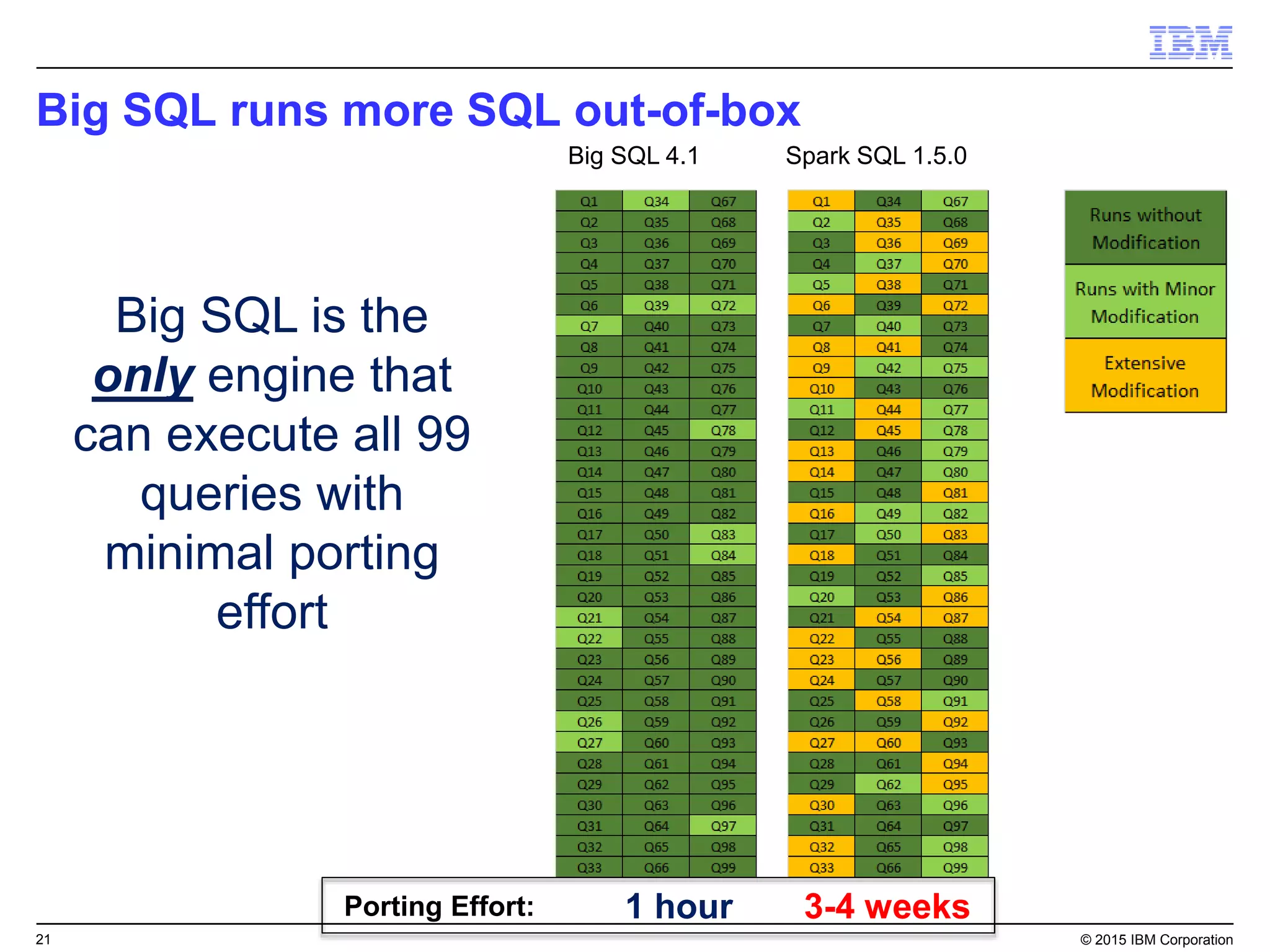
Big SQL is IBM's massively parallel processing SQL engine for Apache Hadoop that allows users to run SQL queries against data stored in HDFS file formats like Parquet and ORC. It provides high performance, scalability, and integration with other data sources through query federation. Big SQL also offers advanced security, high availability, workload management, and monitoring capabilities for enterprise-grade analytics on large datasets.