Downloaded 63 times





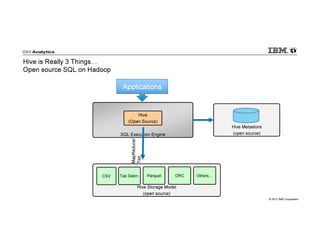
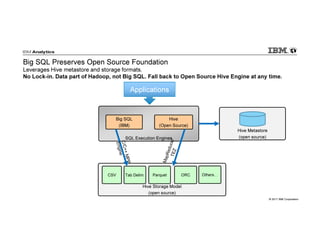

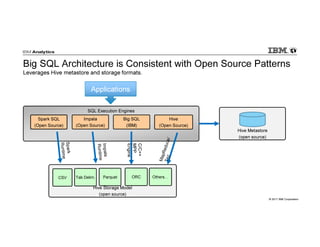




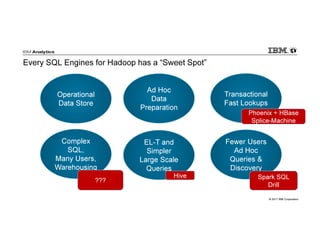


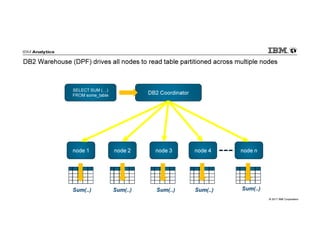
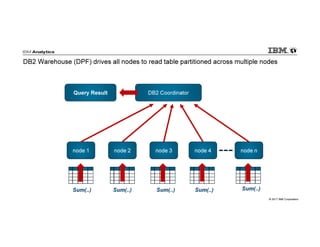
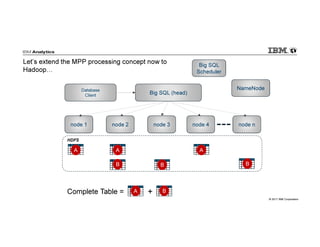
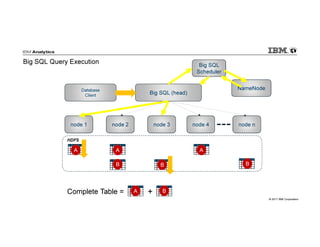
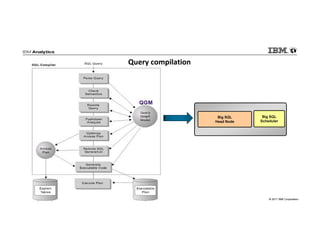
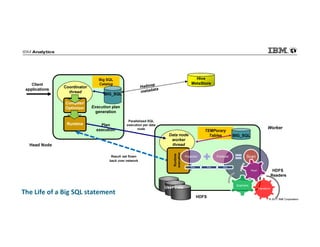
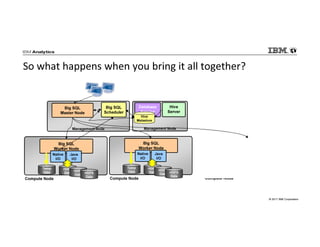
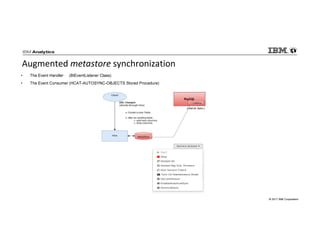



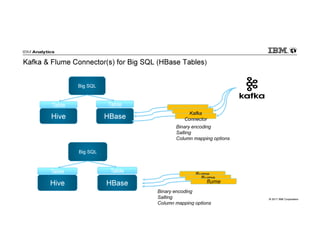

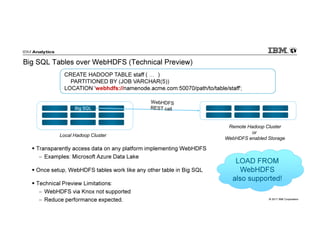
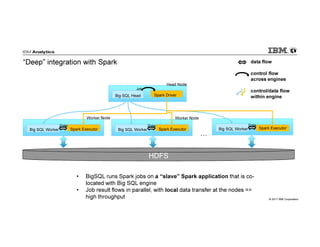



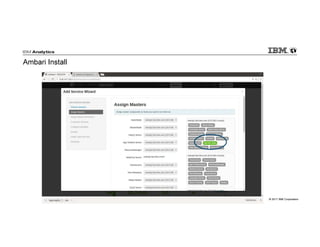
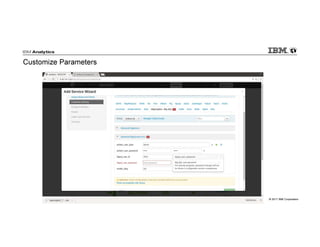
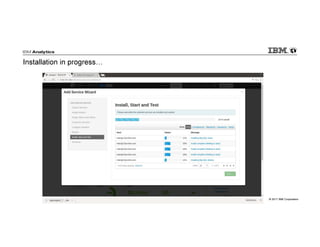
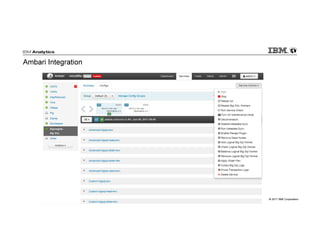
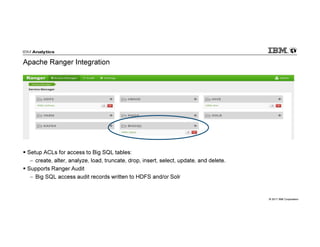

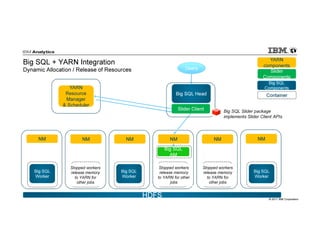
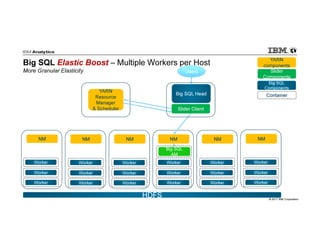

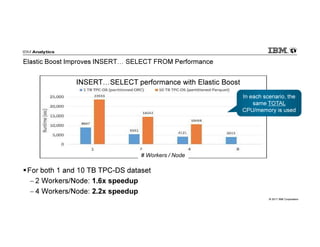

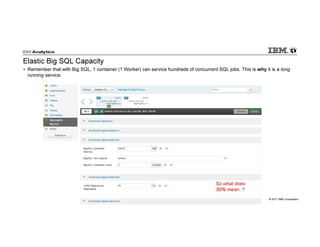
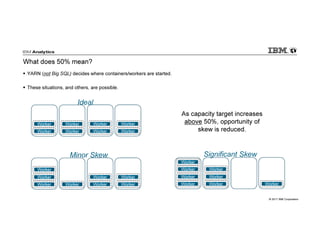

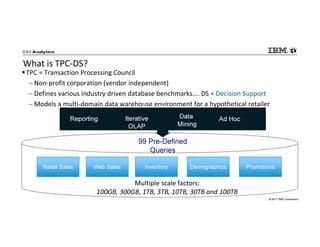


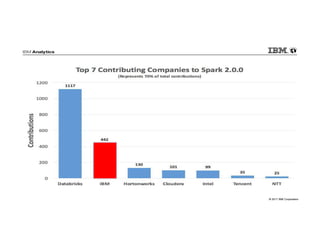
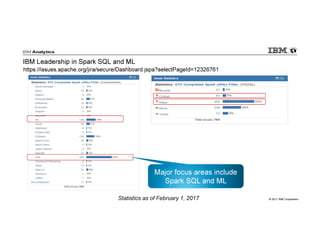
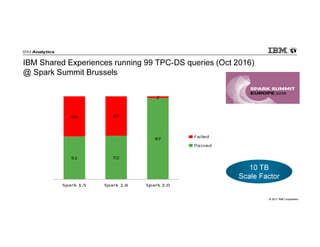

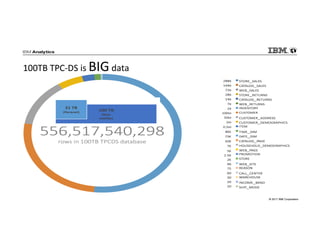

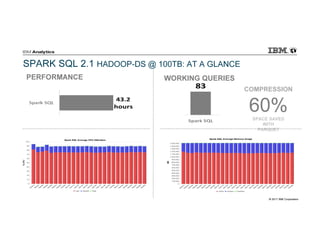



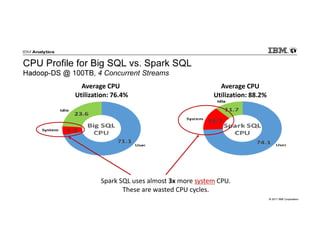
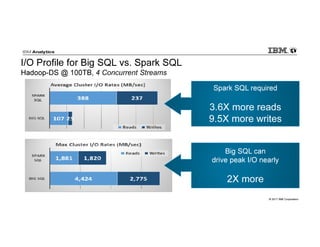
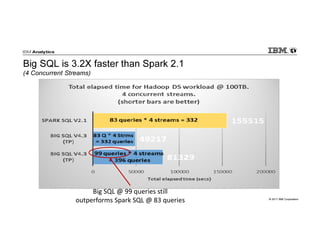

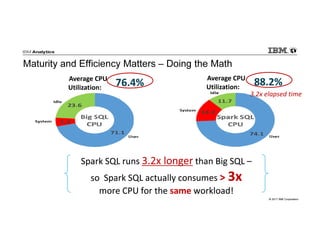


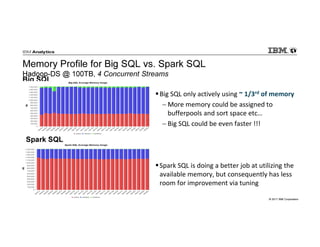
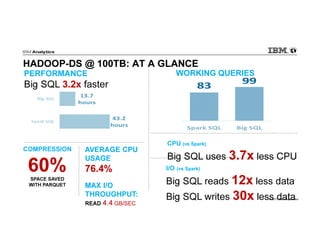






IBM Big SQL is a powerful SQL optimizer designed for open source environments, enabling high performance, concurrency, and scalability for analytical SQL workloads on Hadoop. The system integrates with various components like Hive and Spark, allowing for seamless data access and manipulation while maintaining an open-source foundation without vendor lock-in. The document outlines its architecture, features, and performance enhancements, highlighting its ability to run complex queries efficiently.






















































































