Download as PDF, PPTX










![19 ICTeam S.p.A. – Presentazione della Divisione Progettazione
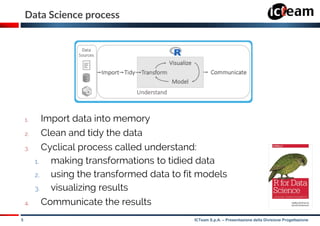
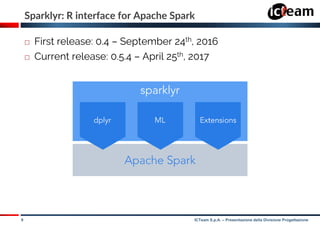
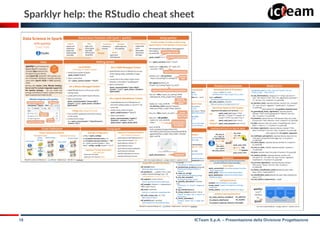
SparkR vs Sparklyr
natively included in Spark after
version 1.6.2
developed by RStudio, available
on CRAN and GitHub
it allows to download and install
Spark for development purposes
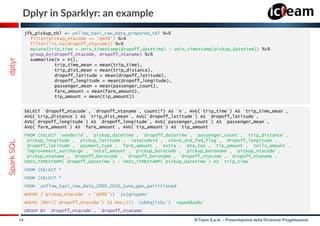
df <- createDataFrame(flights)
head(select(df, df$distance, df$origin))
or
head(df[, c(‘distance', ‘origin')])
filter(df, df$distance > 3000)
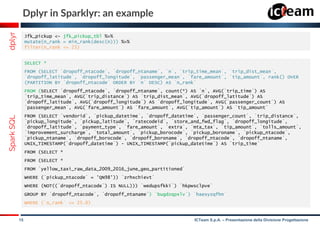
df <- copy_to(sc2, flights)
head(select(df, distance, origin))
filter(df, distance > 3000)
documentation through R’s help documentation through R’s help
SparkR Sparklyr](https://image.slidesharecdn.com/sparklyr-170517092206/85/Sparklyr-Big-Data-enabler-for-R-users-19-320.jpg)

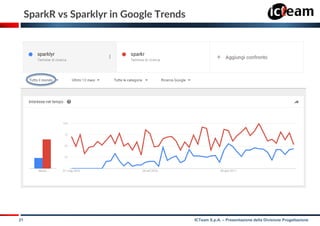
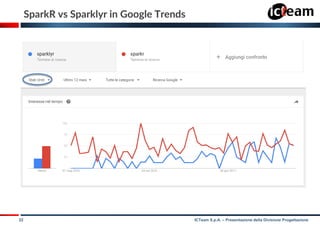



This document presents an overview of sparklyr, an R interface for Apache Spark, highlighting its features and utility in big data analysis for R users. It discusses the data science process, including challenges with big data and how sparklyr facilitates access and analysis through its functionalities. The document also covers examples, comparisons with sparkR, and extensions that can be created to enhance sparklyr's capabilities.



































































