Download to read offline



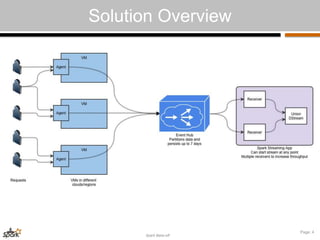
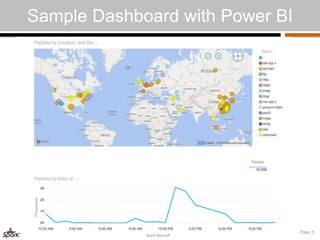


The document details a team's solution for real-time packet analysis using Apache Spark, led by Silvio Fiorito, who has a background in development and app security. The solution involves a high-throughput setup for analyzing TCP packets from distributed hosts, utilizing Azure and AWS services, and incorporates Spark Streaming for data ingestion and processing. Future improvements include adding anomaly detection, testing with real traffic, and enhancing visualization capabilities.











































































