Downloaded 19 times





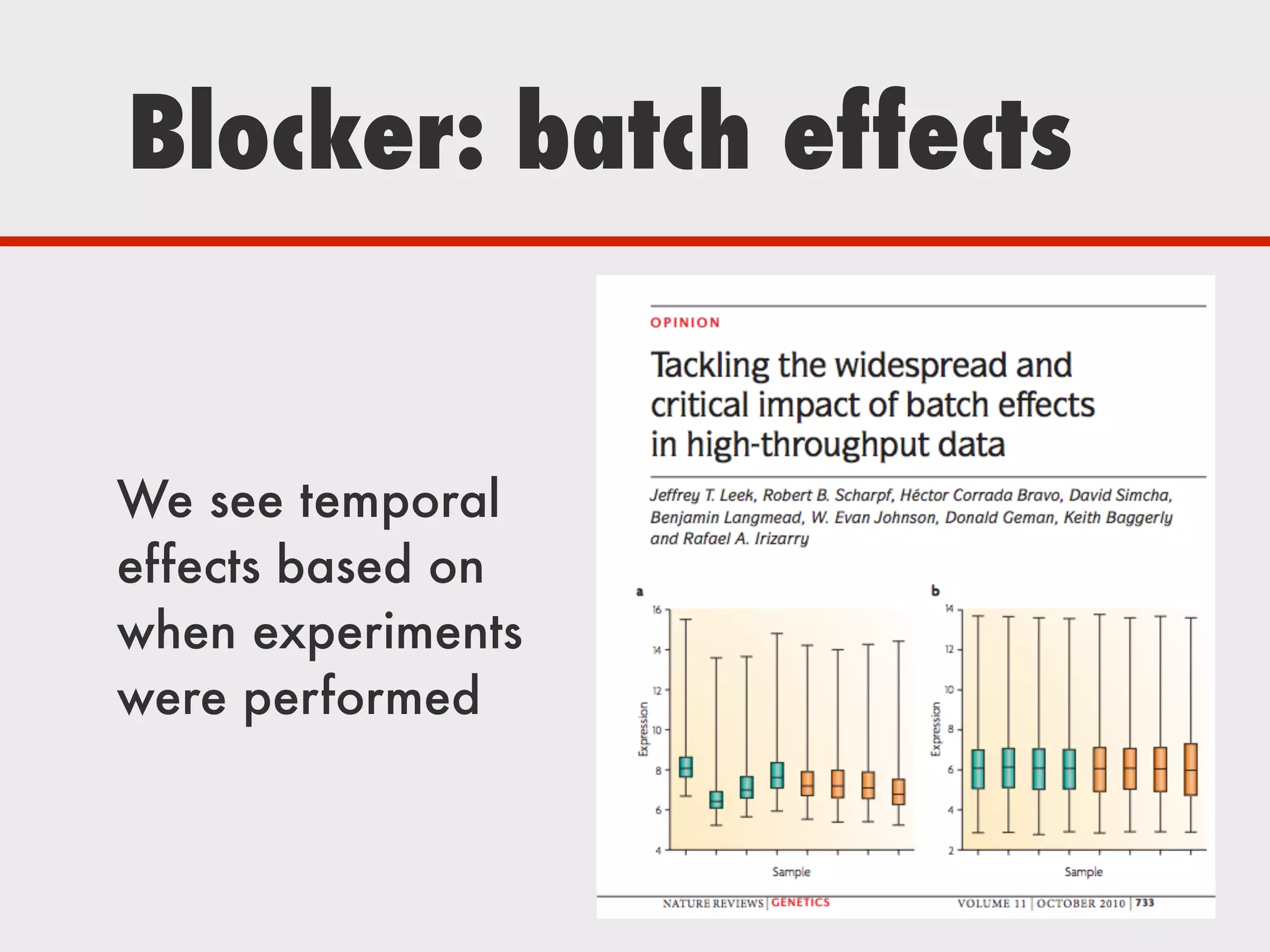

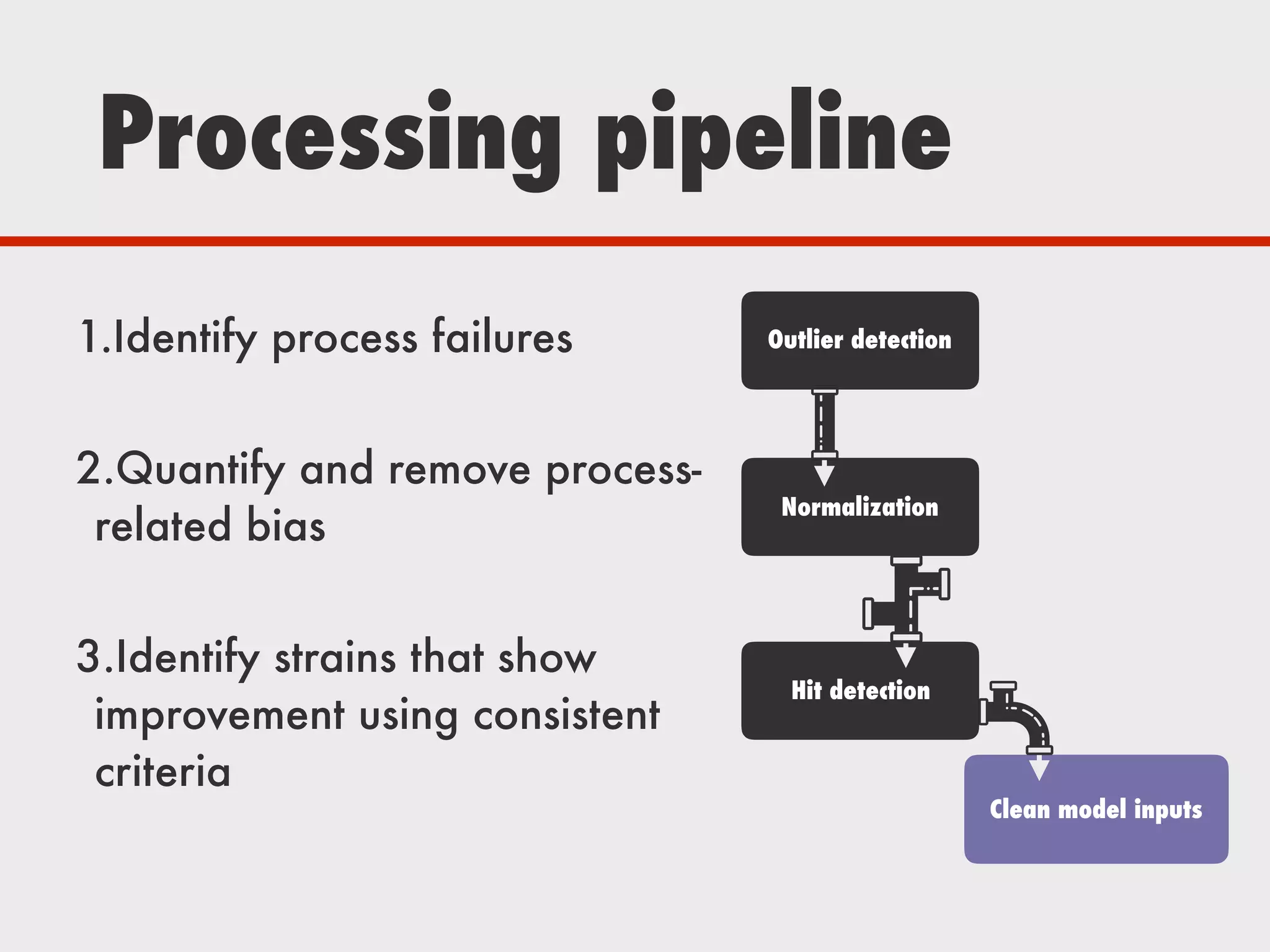
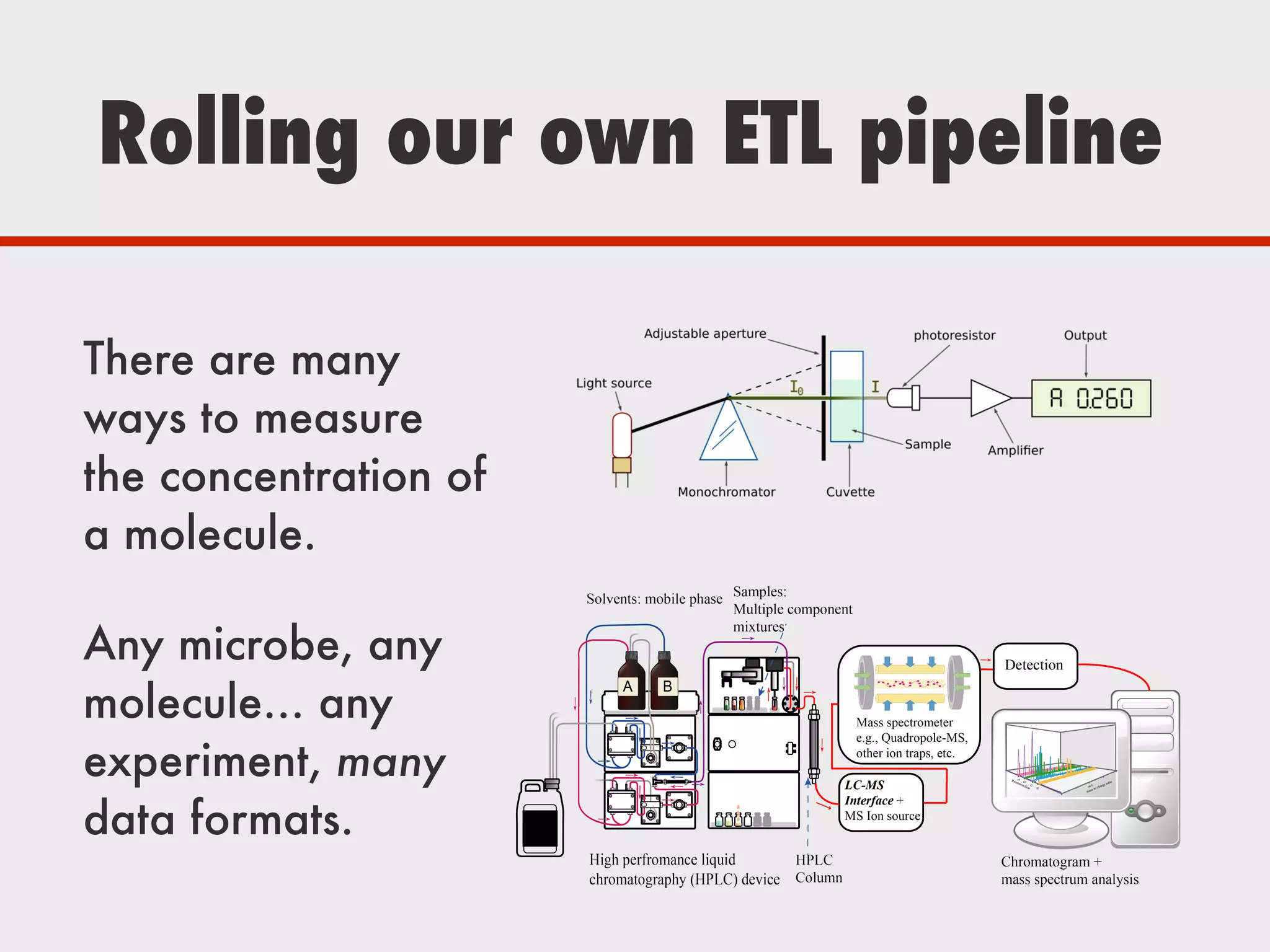
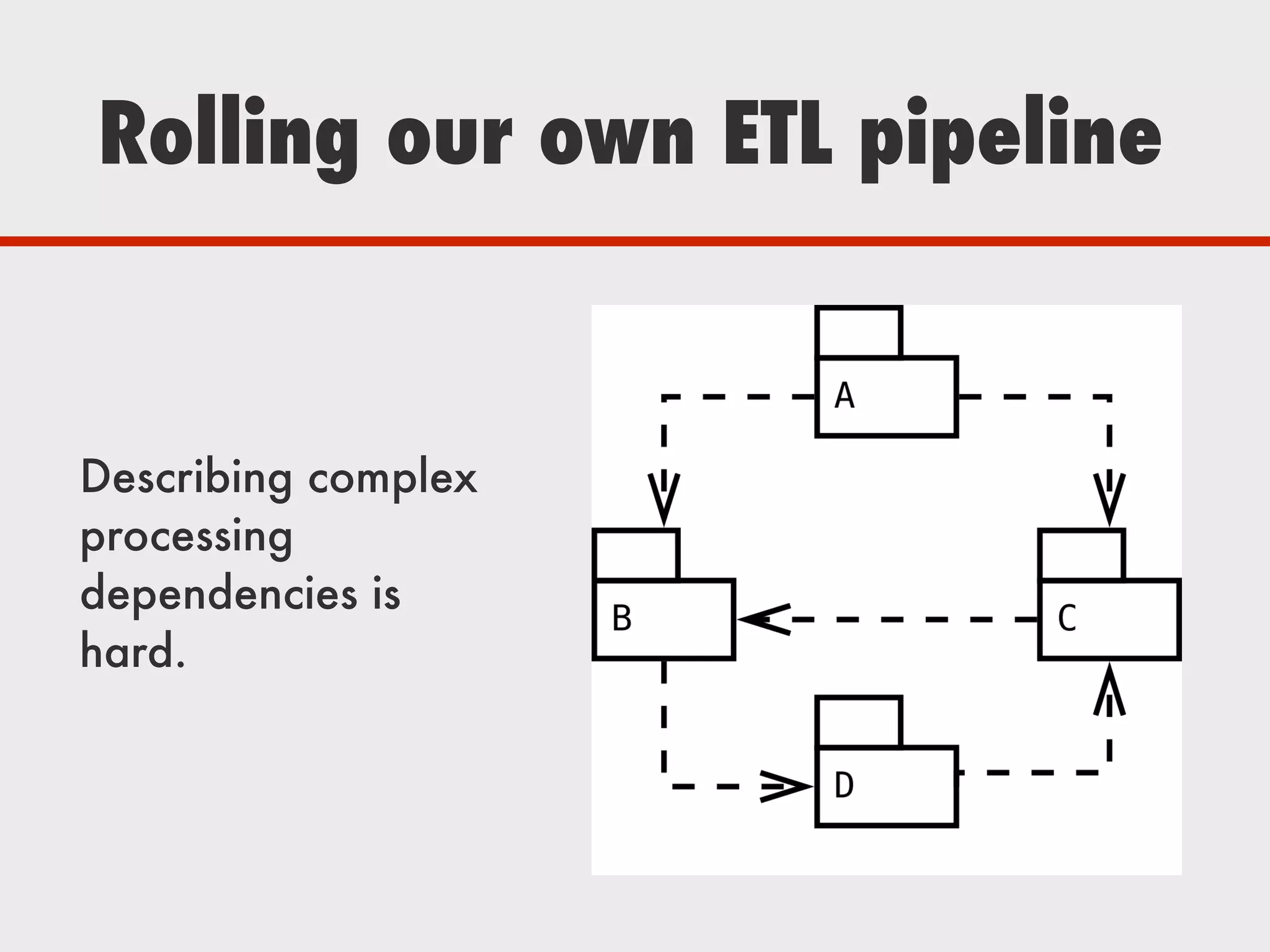


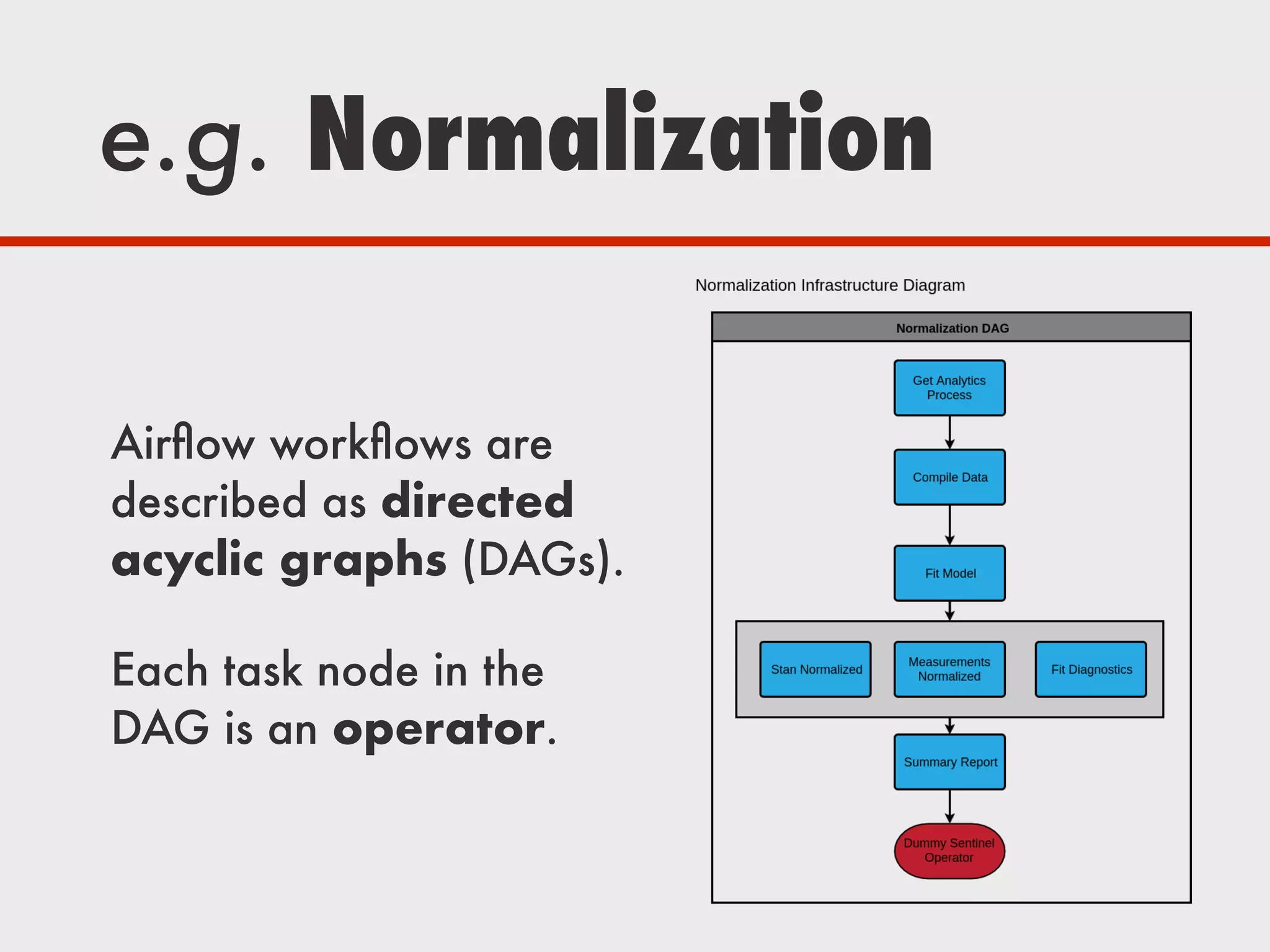
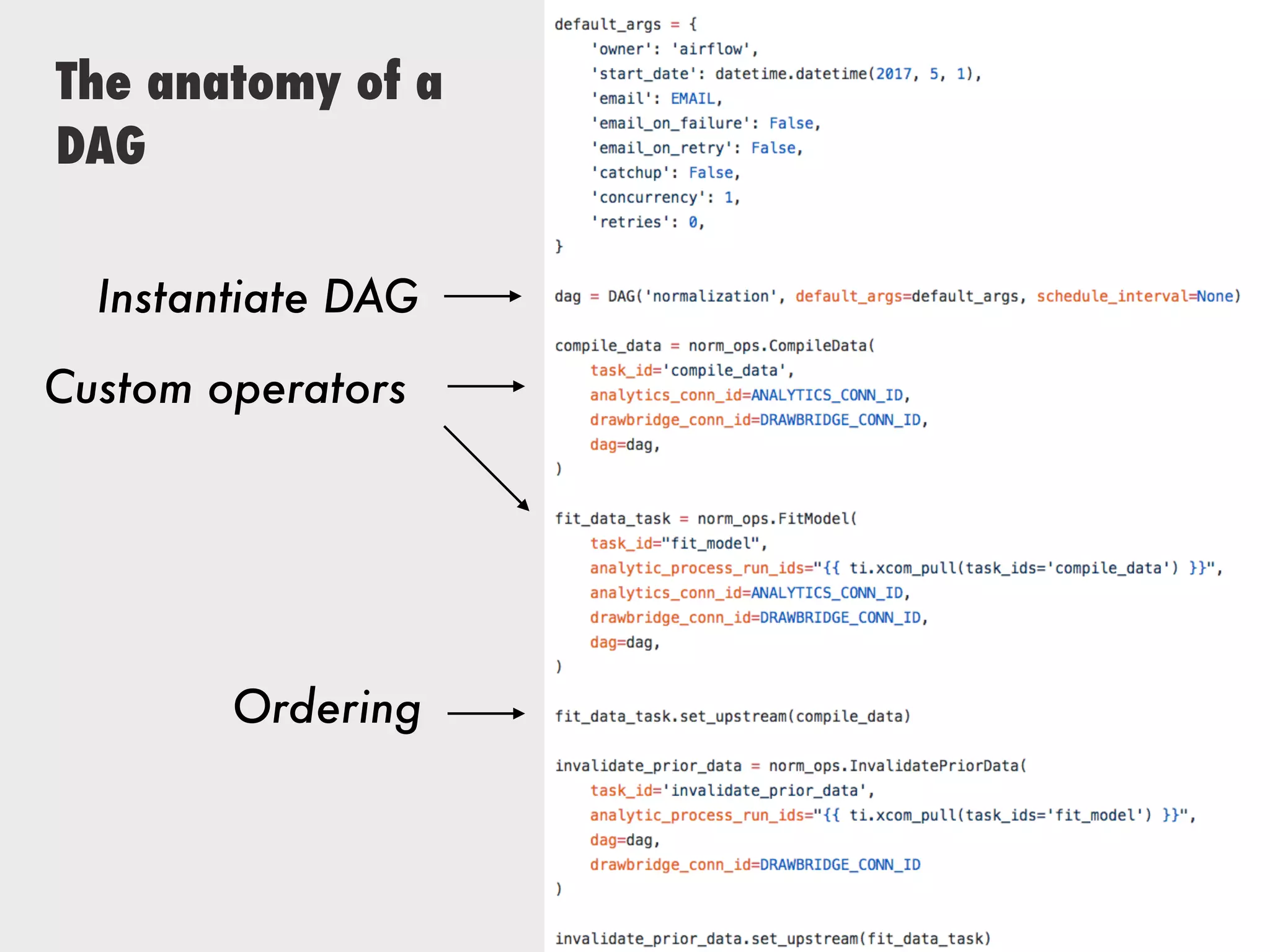





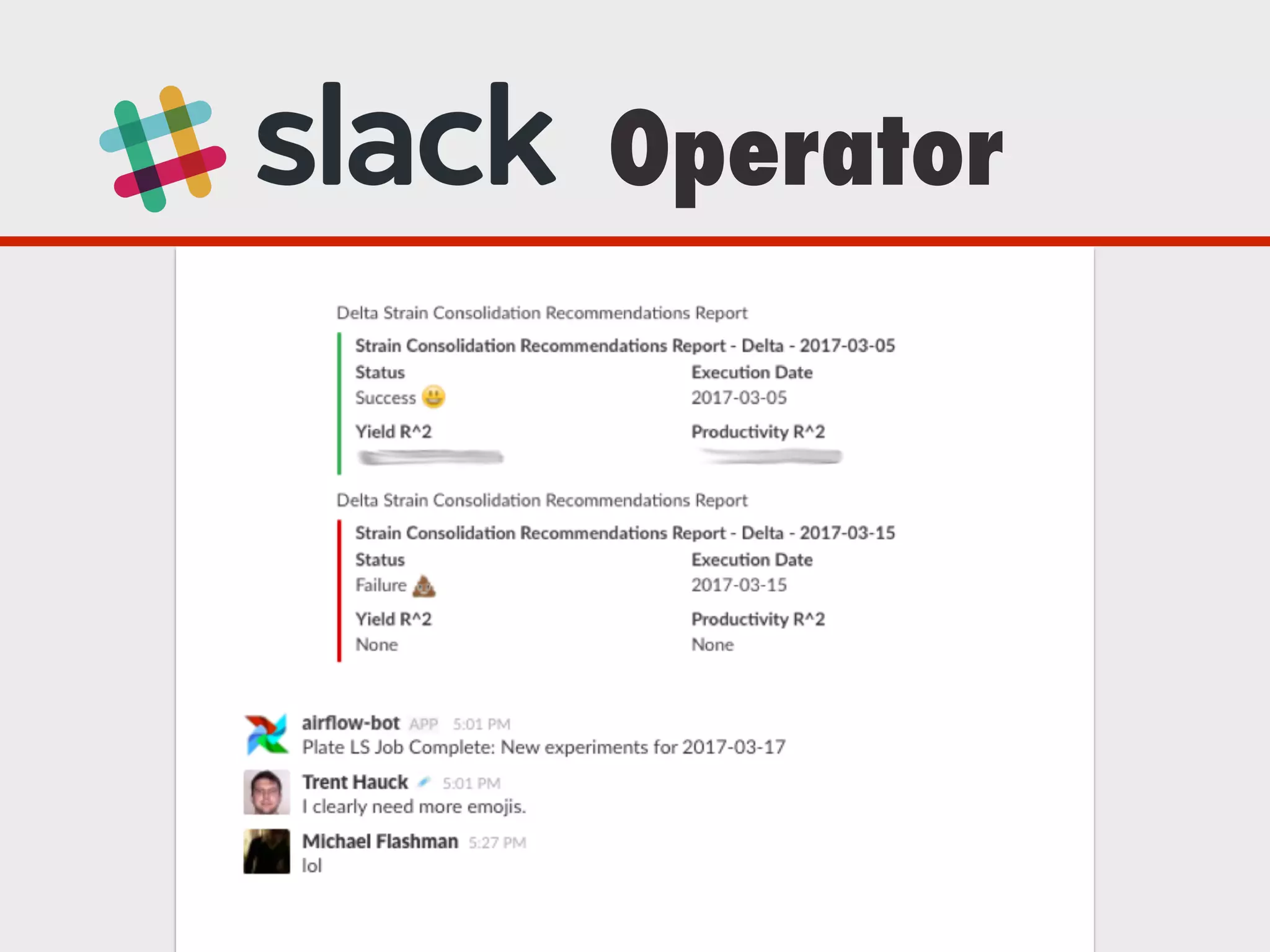


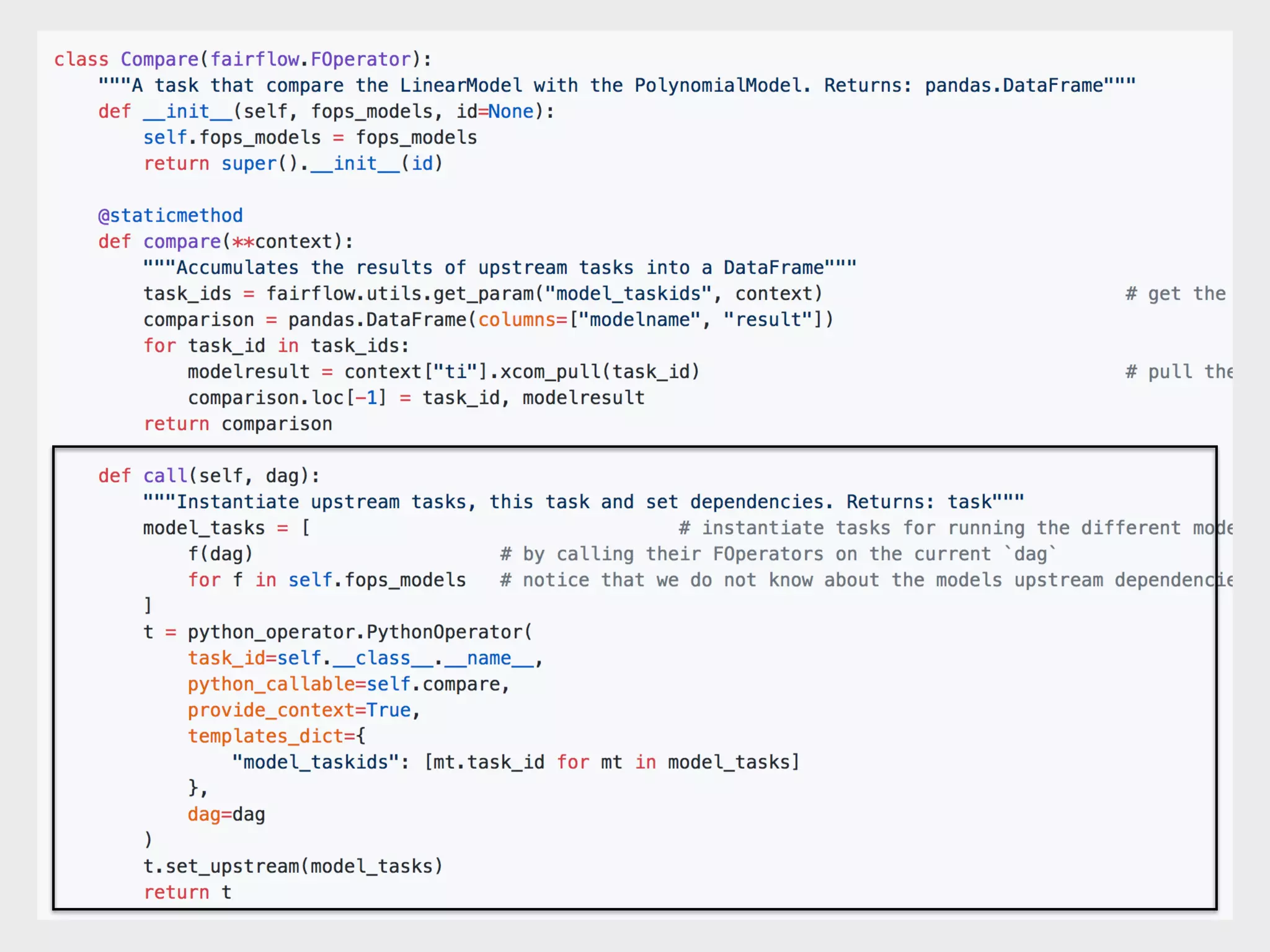

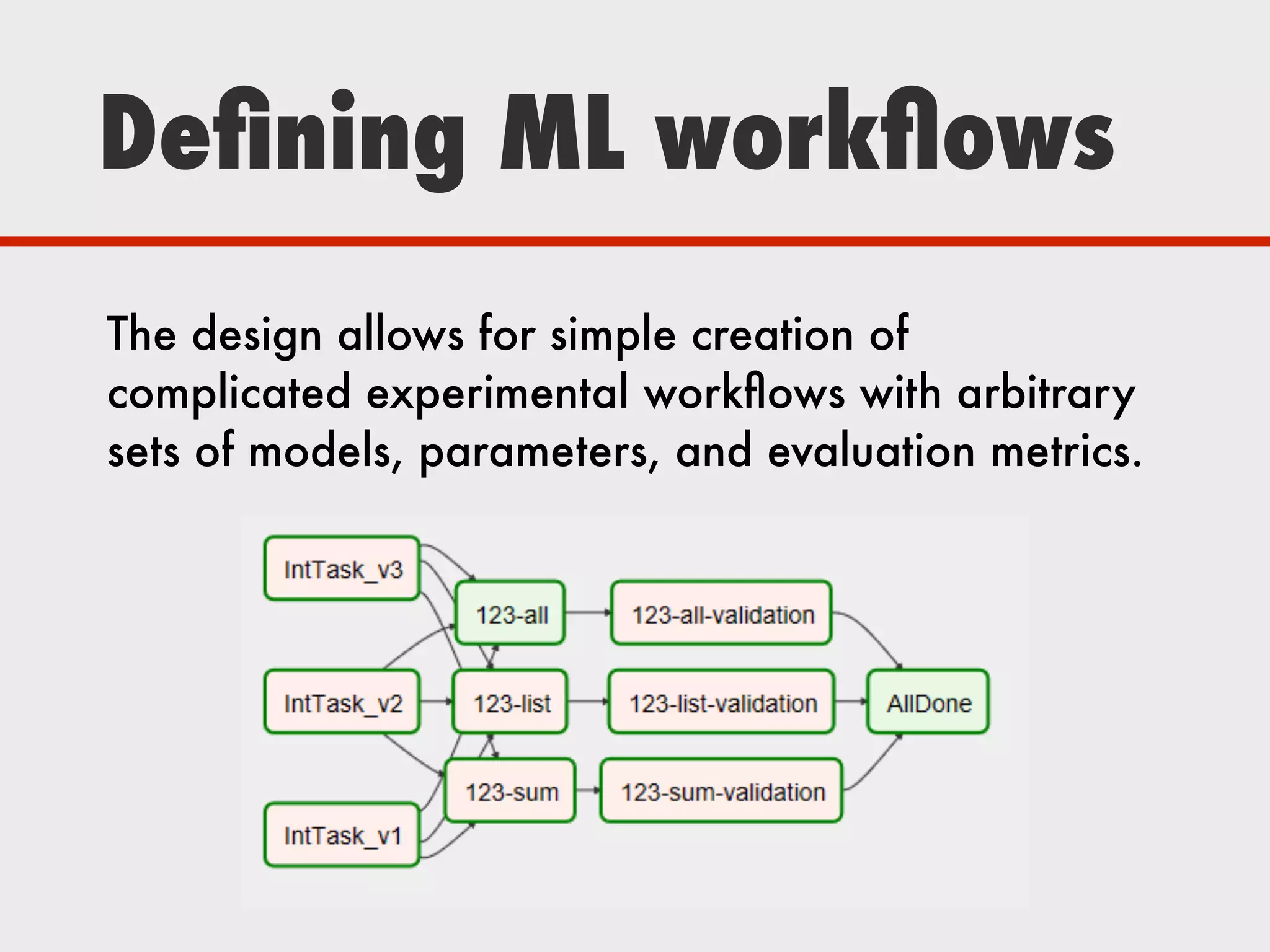



The document discusses Zymergen's approach to building robust experimentation pipelines using Airflow for managing complex workflows in genetic engineering and fermentation processes. It highlights challenges such as process failures, biases in data, and the integration of diverse data sources through custom ETL solutions. The use of tools like Airflow and Bayesian models is emphasized for flexible and modular workflow management in machine learning and experimental setups.










































































