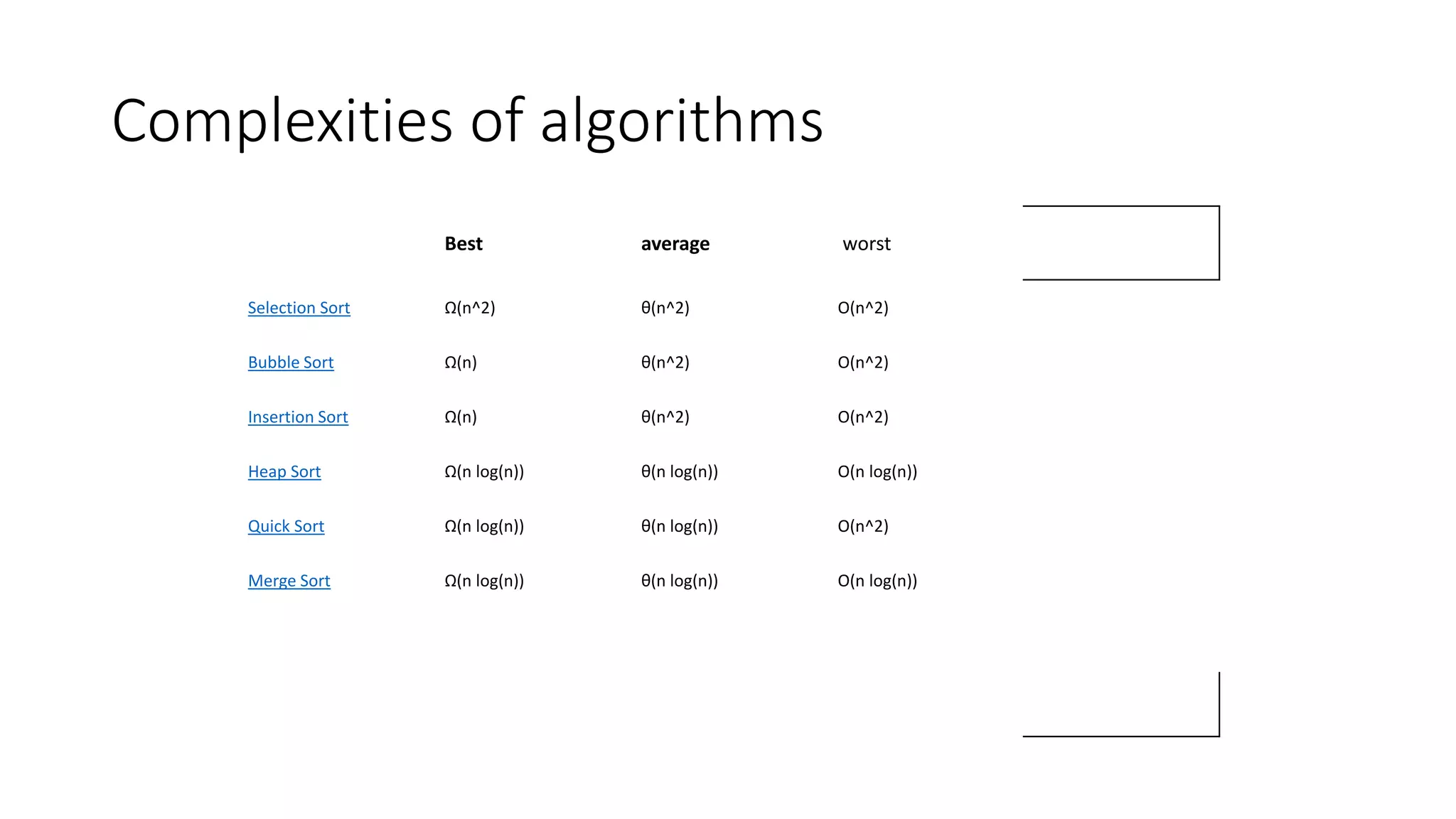
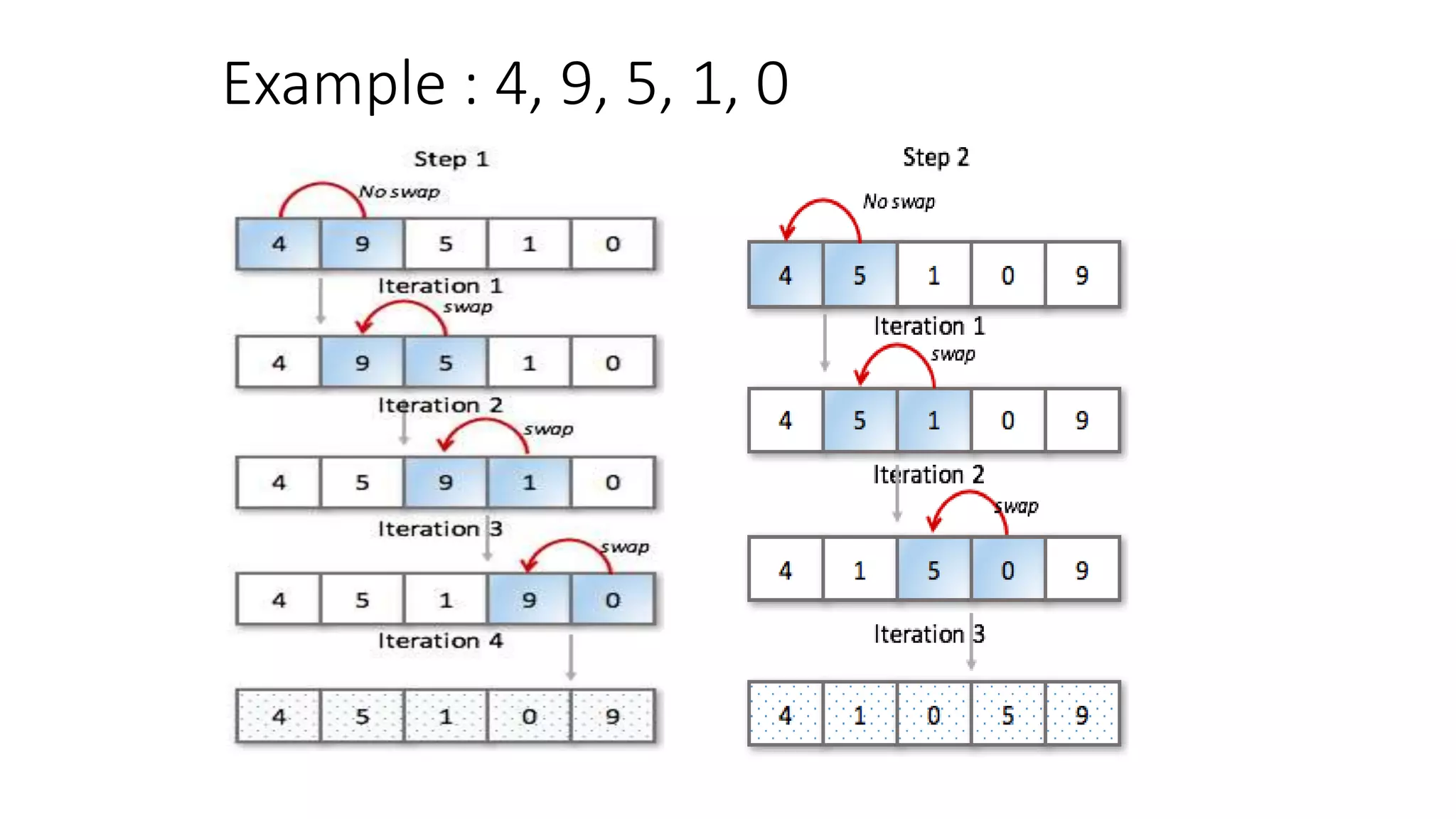
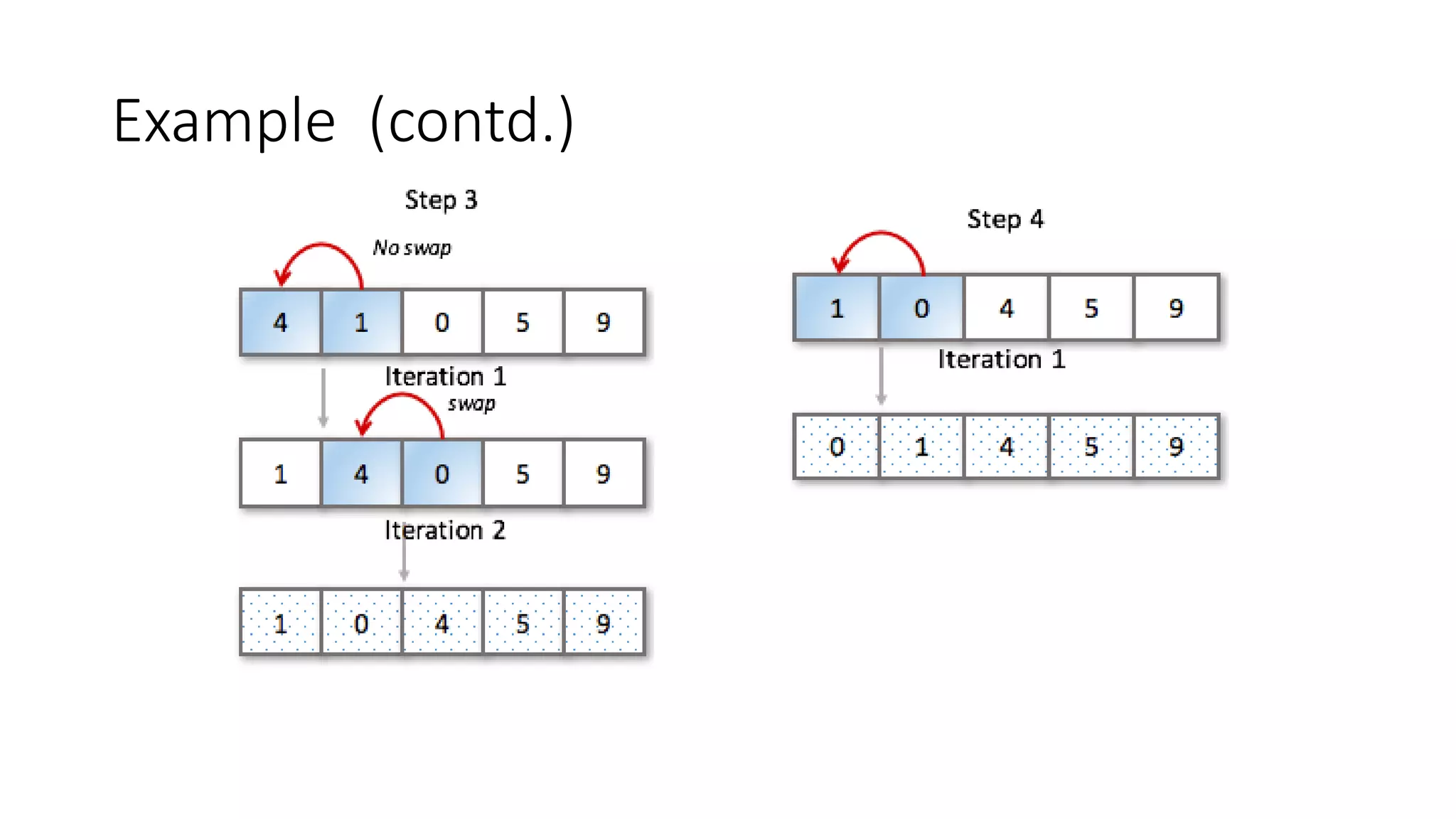
The document discusses various sorting algorithms like bubble sort, selection sort, insertion sort, merge sort, quicksort and heap sort. It provides pseudocode to explain the algorithms. For each algorithm, it explains the basic approach, complexity analysis and provides an example to illustrate the steps. Quicksort is explained in more detail with pseudocode and examples to demonstrate how it works by picking a pivot element, partitioning the array and recursively sorting the sub-arrays.


![Algorithm
int temp;
for(int i=0; i<a.length; i++)
{
int flag=0;
for(int j=0; j<a.length-1-i; j++)
{
if (a[j]>a[j+i])
{
temp=a[j];
a[j]=a[j+1]
a[j+1]=temp;
flag=1;
}
}
If (flag==0)
{
break;
}
}](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-6-2048.jpg)
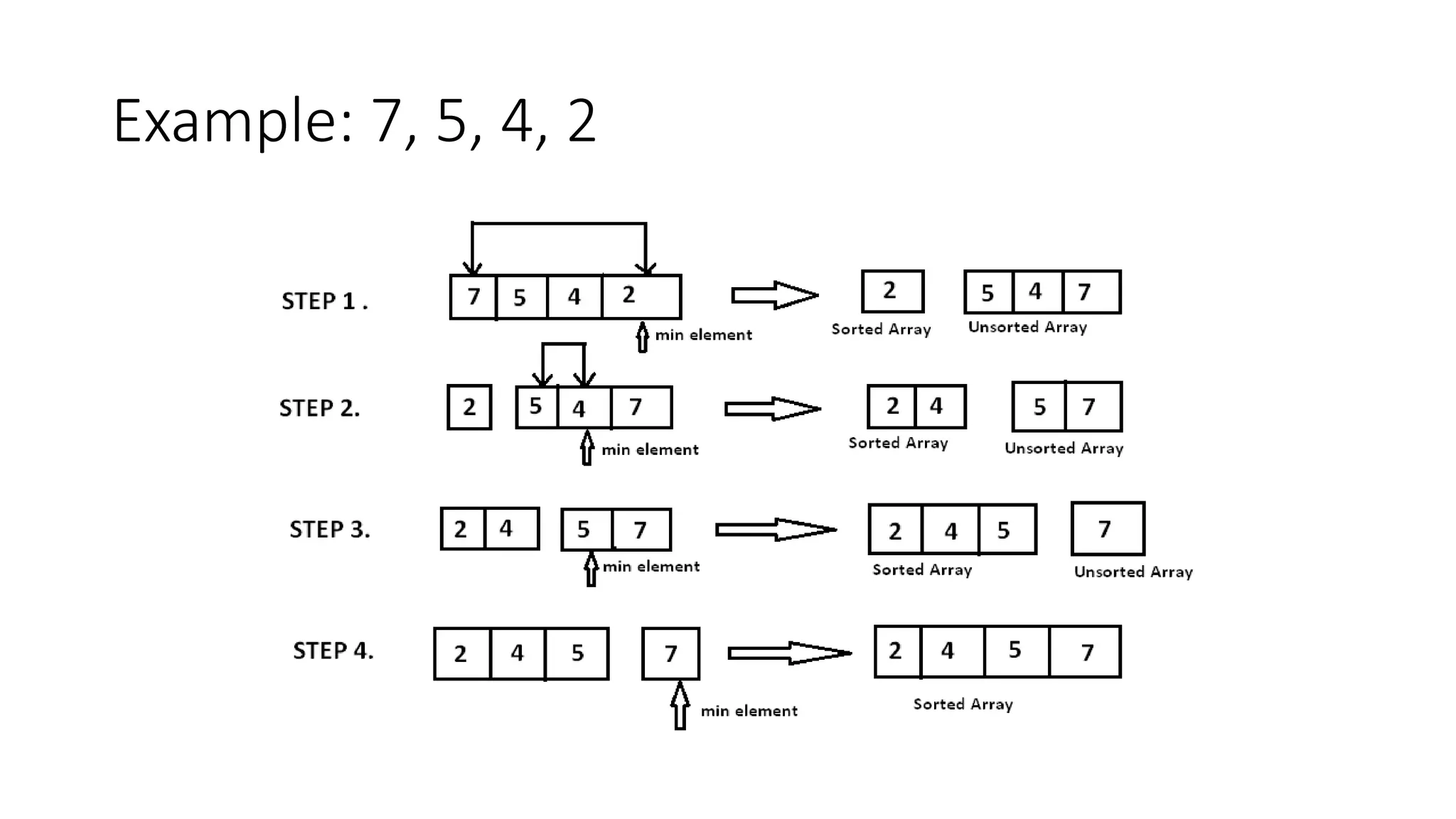
![2. SELECTION SORT
The Selection sort algorithm is based on the idea of finding the minimum or maximum
element in an unsorted array and then putting it in its correct position in a sorted array.
Assume that the array A=[7,5,4,2] needs to be sorted in ascending order.
The minimum element in the array i.e. 2 is searched for and then swapped with the
element that is currently located at the first position, i.e. 7. Now the minimum element in
the remaining unsorted array is searched for and put in the second position, and so on.](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-7-2048.jpg)
![PSUDOCODE
void sort(int arr[])
{
int n = arr.length;
for (int i = 0; i < n-1; i++)
{
// Find the minimum element in unsorted array
int min_idx = i;
for (int j = i+1; j < n; j++)
if (arr[j] < arr[min_idx])
min_idx = j;
// Swap the found minimum element with the first element
int temp = arr[min_idx];
arr[min_idx] = arr[i];
arr[i] = temp;
}
}](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-9-2048.jpg)
![Algorithm
Algo SelectionSort(a[ ])
{
int min, temp=0;
for (i=0; i<a.length; i++)
{
min=i;
for(int j=i+1; j<a.length; j++)
{
if (a[j] < a[min])
{
min=j;
}
}
temp=a[i];
a[i]=a[min];
a[min]=temp;
}](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-10-2048.jpg)

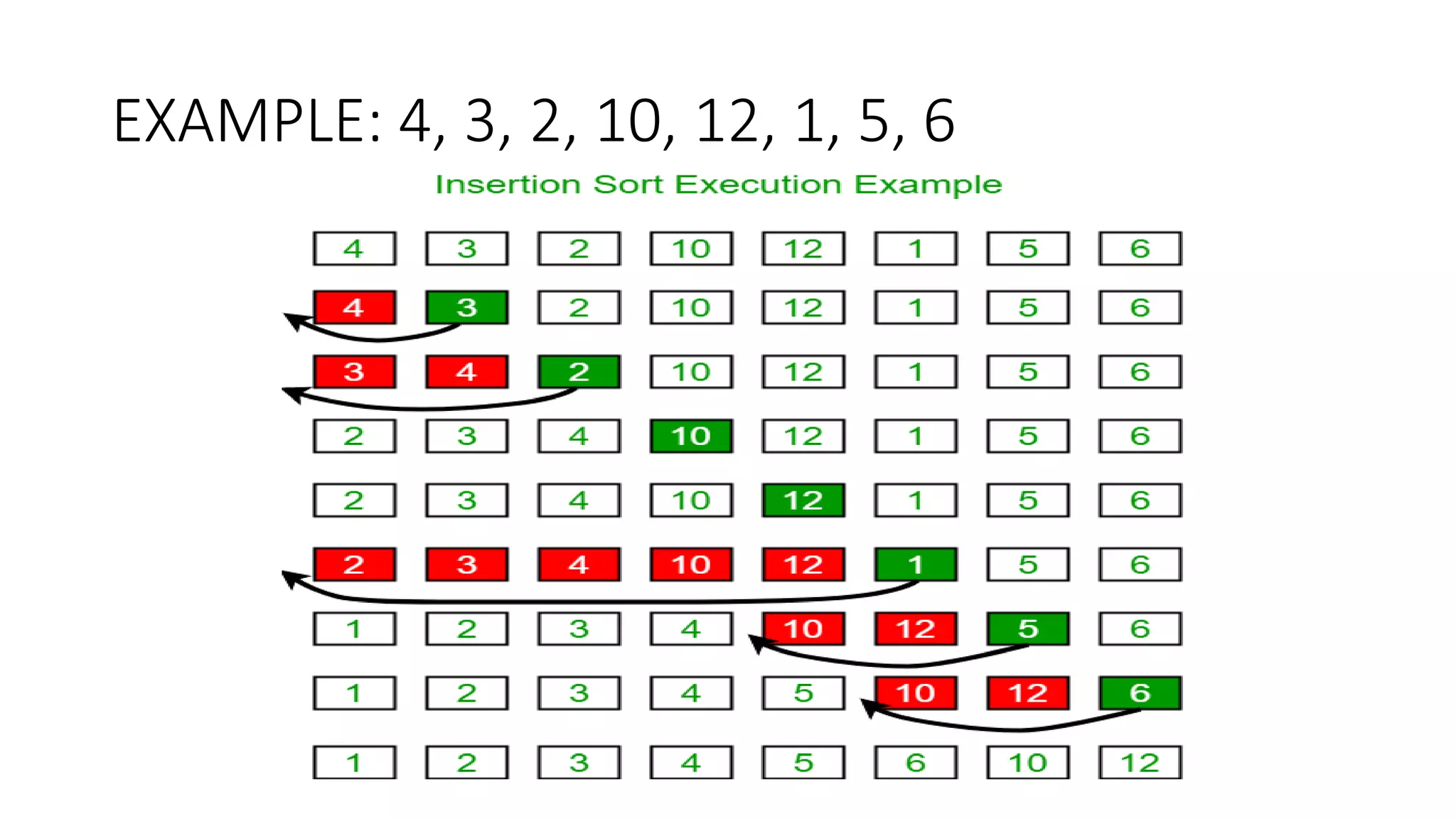
![EXAMPLE: 11, 12, 13, 5, 6
Let us loop for i = 1 (second element of the array) to 4 (last element of the array)
• i = 1. Since 11 is smaller than 12, move 12 and insert 11 before 12
11, 12, 13, 5, 6
• i = 2. 13 will remain at its position as all elements in A[0..I-1] are smaller than 13
11, 12, 13, 5, 6
• i = 3. 5 will move to the beginning and all other elements from 11 to 13 will move one position ahead of their current
position.
5, 11, 12, 13, 6
• i = 4. 6 will move to position after 5, and elements from 11 to 13 will move one position ahead of their current position.
5, 6, 11, 12, 13](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-13-2048.jpg)
![Algorithm- Insertion Sort
void sort(int arr[])
{
int n = arr.length;
for (int i = 1; i < n; ++i) {
int key = arr[i];
int j = i - 1;
/* Move elements of arr[0..i-1], that are
greater than key, to one position ahead
of their current position */
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j = j - 1;
}
arr[j + 1] = key;
}
}](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-14-2048.jpg)

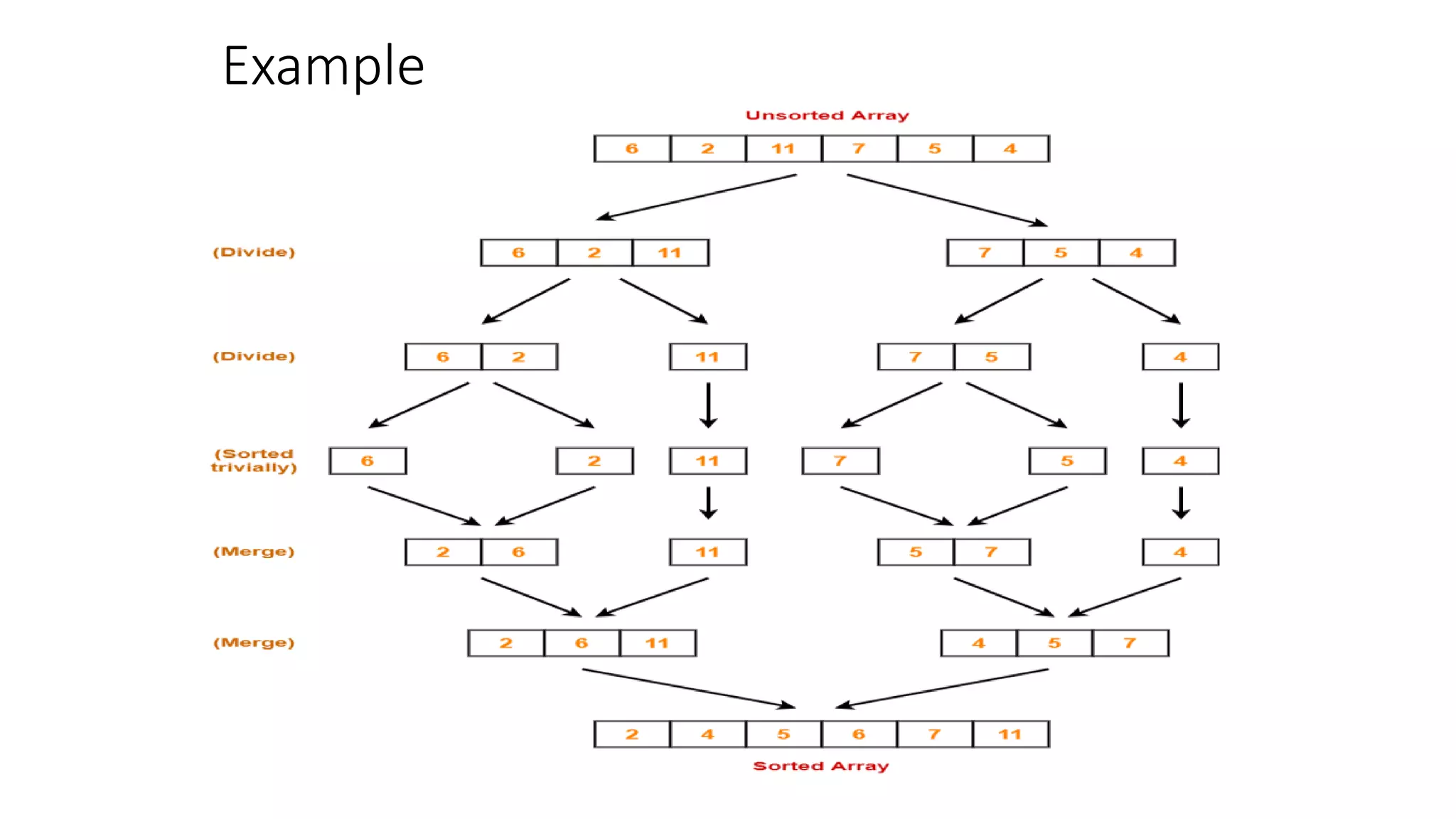
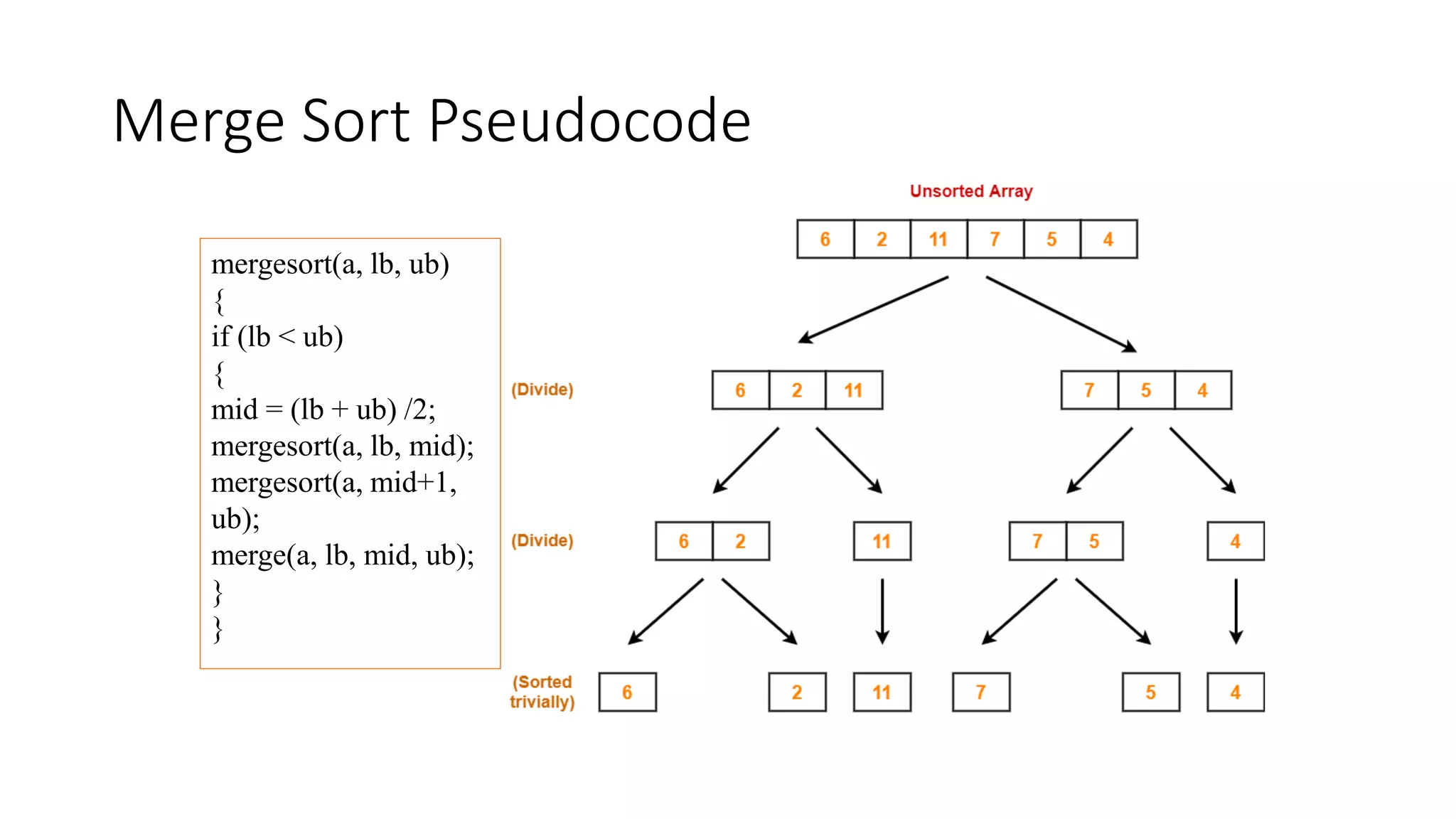
![Merge Pseudocode
merge(a, lb, mid, ub)
{
i=lb; j=mid+1; k=lb;
while (i<=mid && j<=ub)
{
if(a[i]<=a[j])
{
b[k]=a[i];
i++; k++;
}
else
{
b[k]=a[j];
j++; k++;
}
}
if (i>mid)
{
while (j<=ub)
{
b[k] = a[j];
j++;
k++;
}
}
else if (j>ub)
{
while (i<=mid)
{
b[k]=a[i];
i++;
k++;
}}](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-18-2048.jpg)


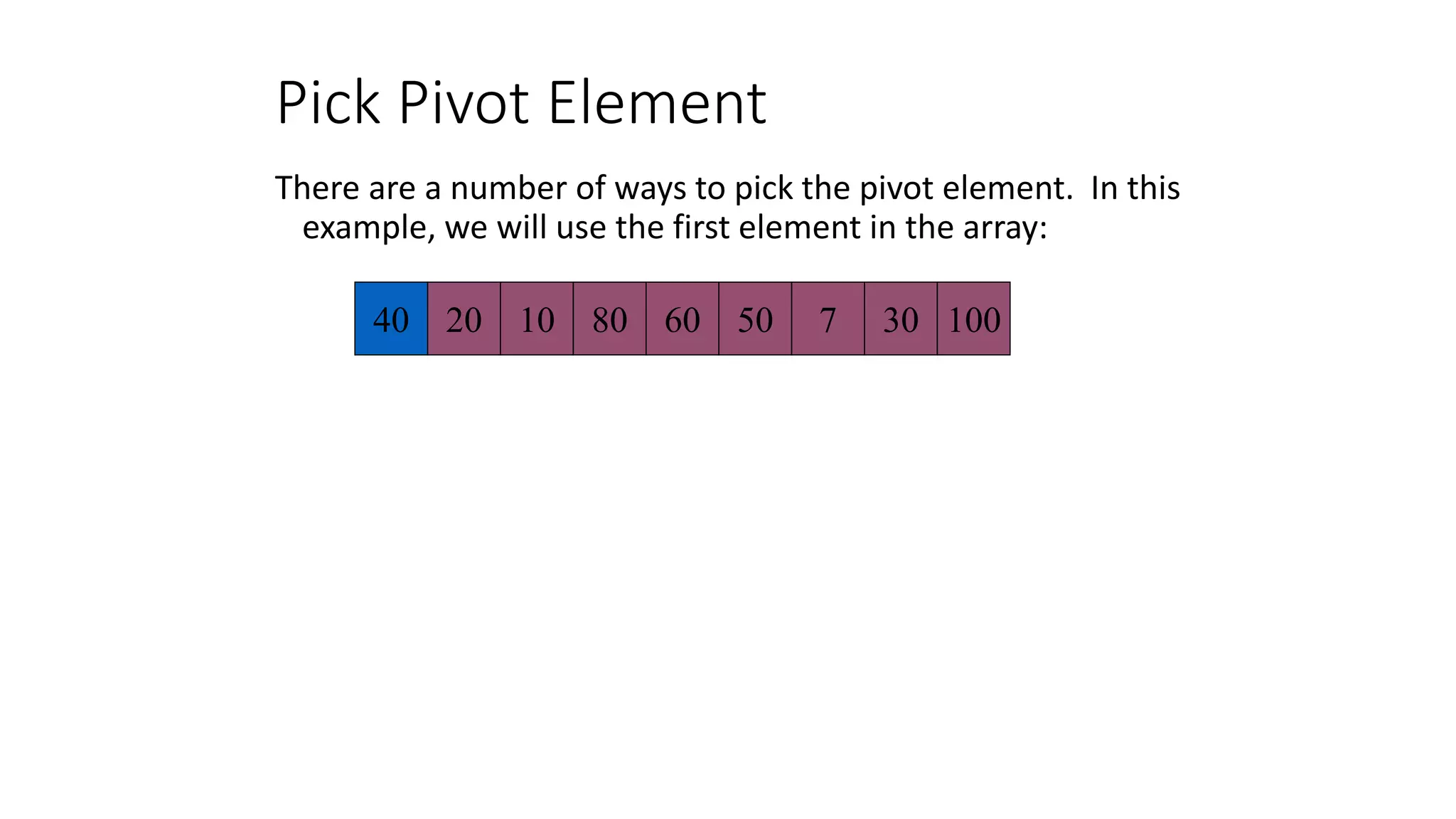

![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-23-2048.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-24-2048.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-25-2048.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-26-2048.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-27-2048.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-28-2048.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-29-2048.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-30-2048.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-31-2048.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-32-2048.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-33-2048.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-34-2048.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-35-2048.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-36-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-37-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-38-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-39-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-40-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-41-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-42-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-43-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-44-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-45-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-46-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
7 20 10 30 40 50 60 80 100
pivot_index = 4
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-47-2048.jpg)
![Partition Result
7 20 10 30 40 50 60 80 100
[0] [1] [2] [3] [4] [5] [6] [7] [8]
<= data[pivot] > data[pivot]](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-48-2048.jpg)
![Recursion: Quicksort Sub-arrays
7 20 10 30 40 50 60 80 100
[0] [1] [2] [3] [4] [5] [6] [7] [8]
<= data[pivot] > data[pivot]](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-49-2048.jpg)








![Quicksort: Worst Case
• Assume first element is chosen as pivot.
• Assume we get array that is already in order:
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-58-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-59-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-60-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-61-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-62-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-63-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-64-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
> data[pivot]
<= data[pivot]](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-65-2048.jpg)






![Improved Pivot Selection
Pick median value of three elements from data array:
data[0], data[n/2], and data[n-1].
Use this median value as pivot.](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-72-2048.jpg)
![Improving Performance of Quicksort
• Improved selection of pivot.
• For sub-arrays of size 3 or less, apply brute force search:
• Sub-array of size 1: trivial
• Sub-array of size 2:
• if(data[first] > data[second]) swap them
• Sub-array of size 3: left as an exercise.](https://image.slidesharecdn.com/lecture3andlecture4-221106082402-56488fa4/75/Sorting-techniques-73-2048.jpg)














![Data Structures - Lecture 9 [Stack & Queue using Linked List]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture-9stackqueueusinglinkedlist-150219032411-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)



























![UNIT V Searching Sorting Hashing Techniques [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/unitvsearchingsortinghashingtechniquesautosaved-241014040608-74caa0f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![UNIT V Searching Sorting Hashing Techniques [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/unitvsearchingsortinghashingtechniquesautosaved-241126054304-95a69c51-thumbnail.jpg?width=640&height=640&fit=bounds)







































