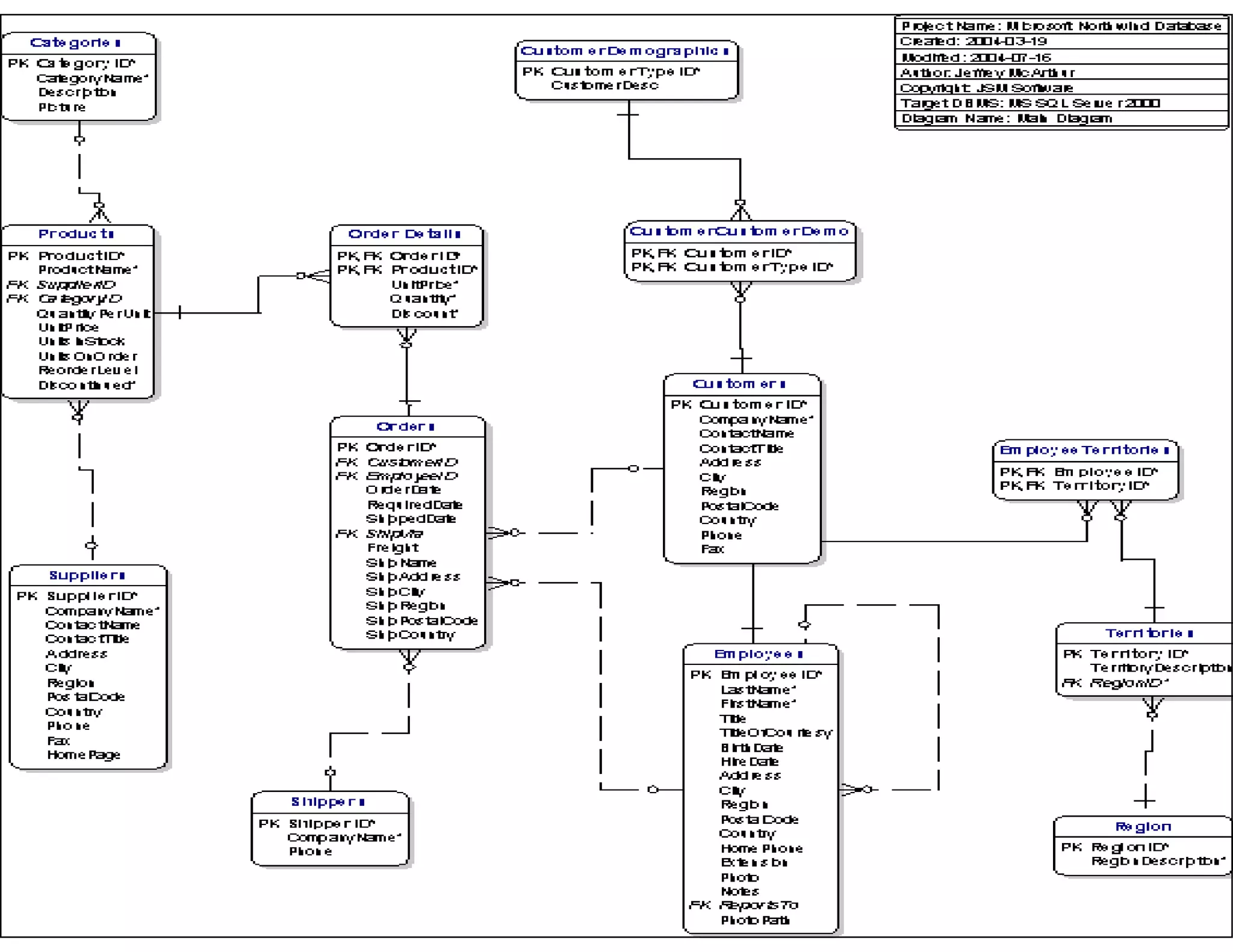
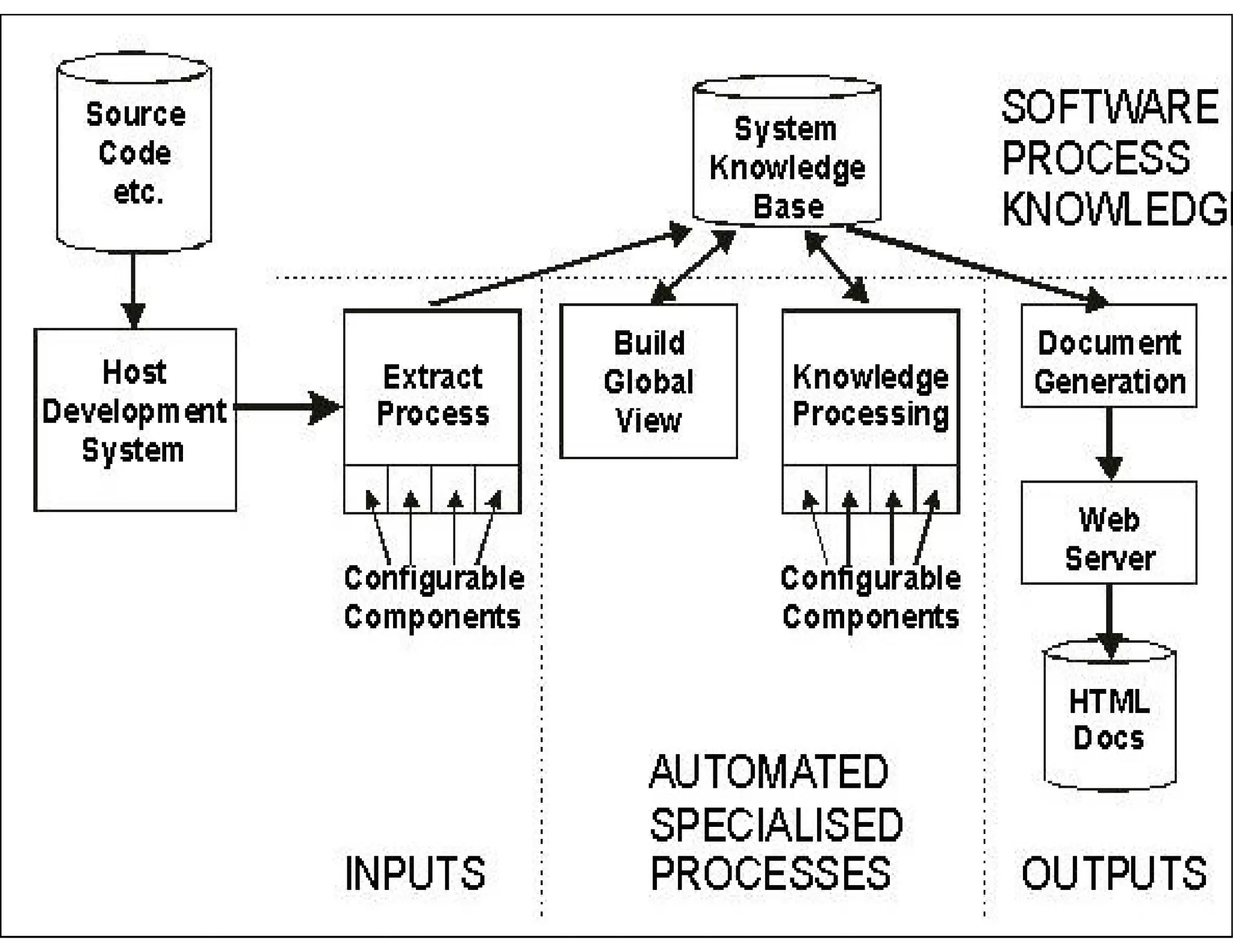
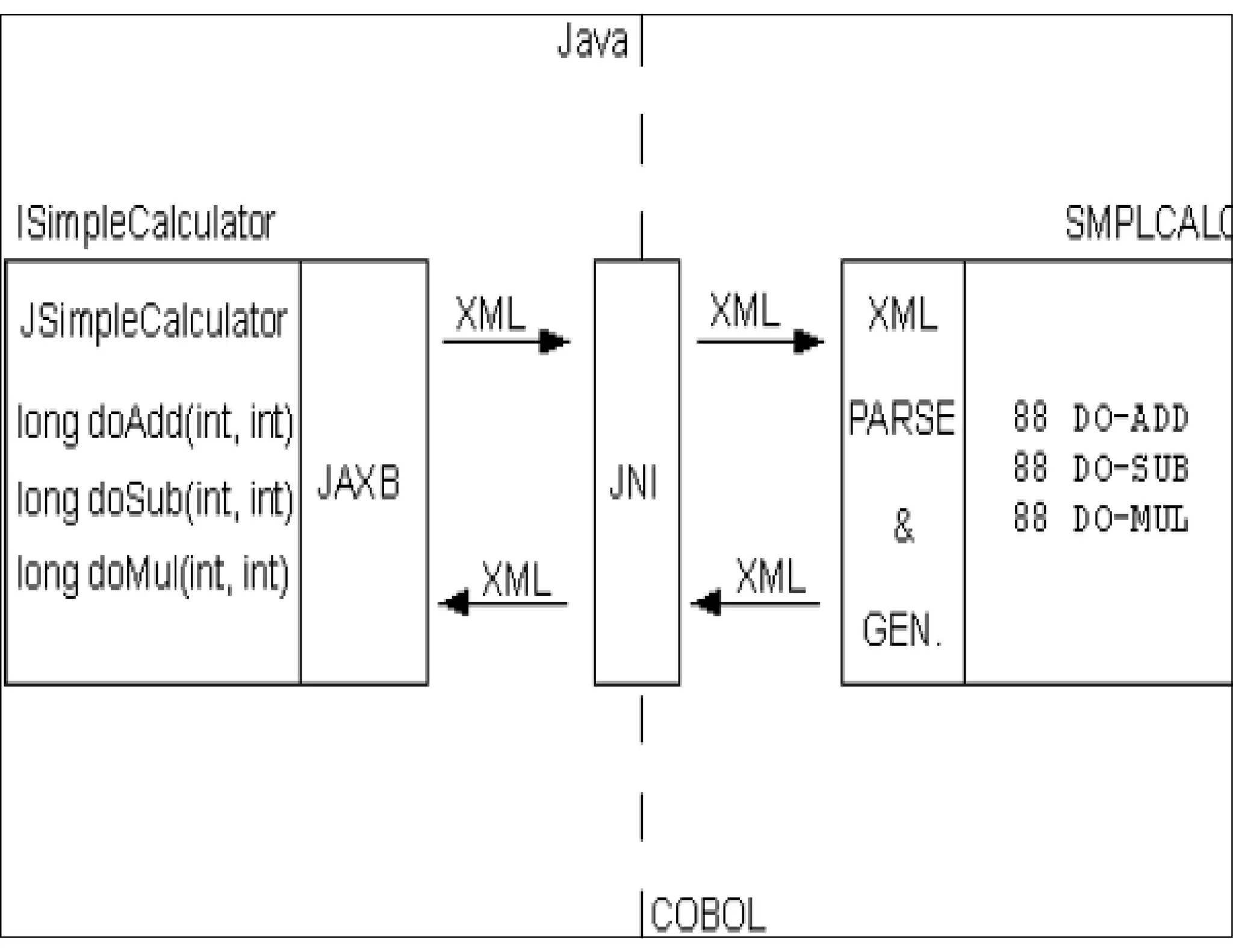
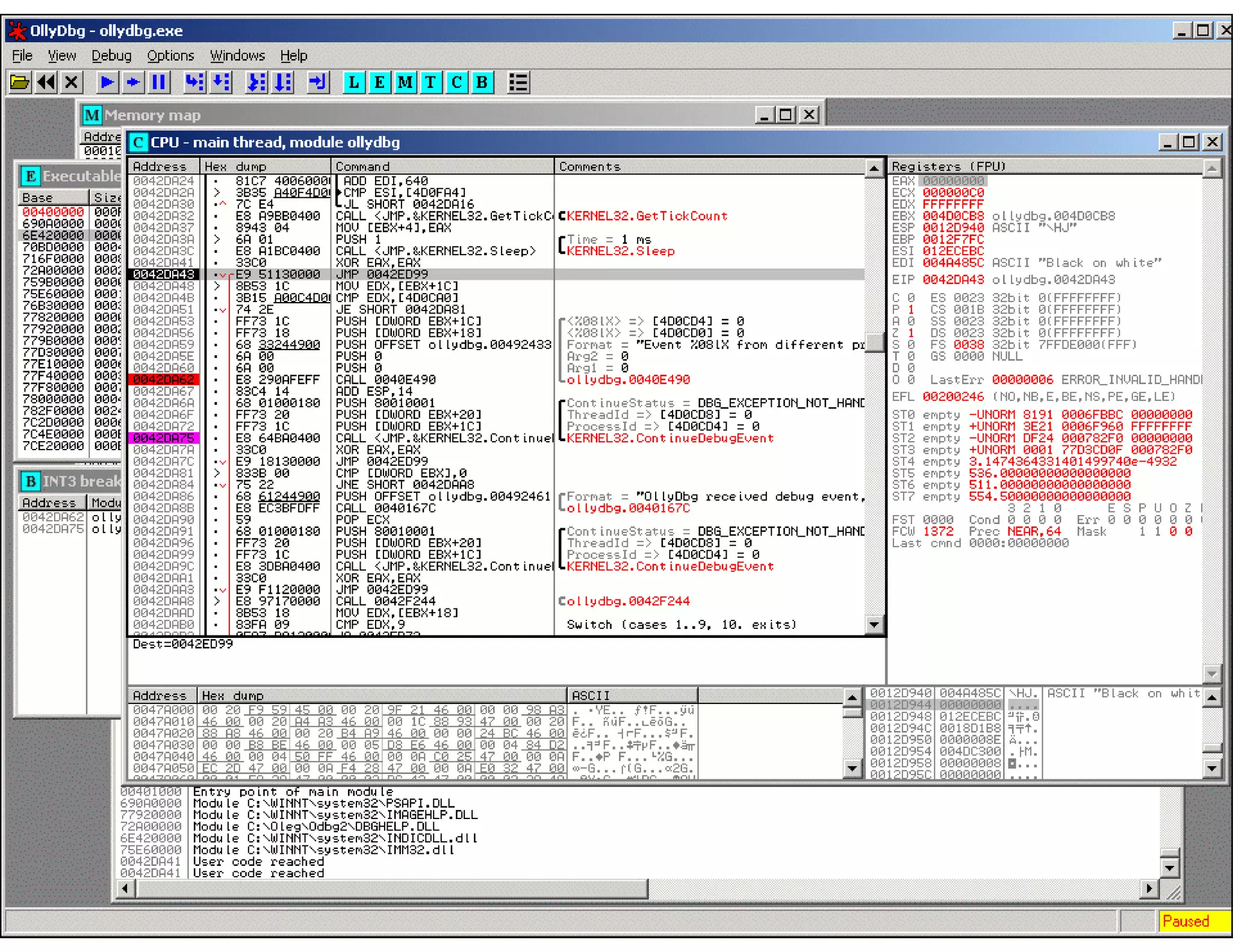
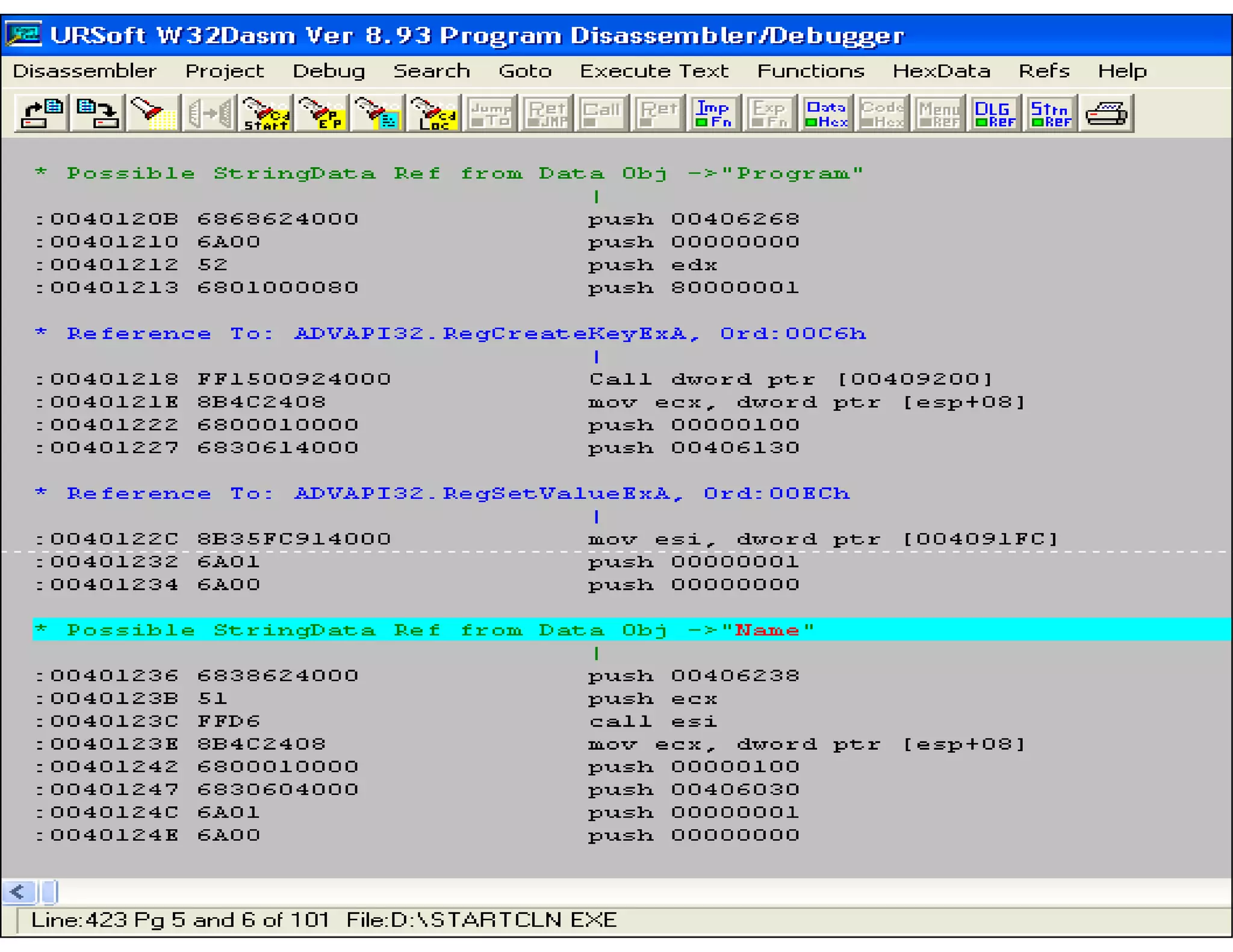
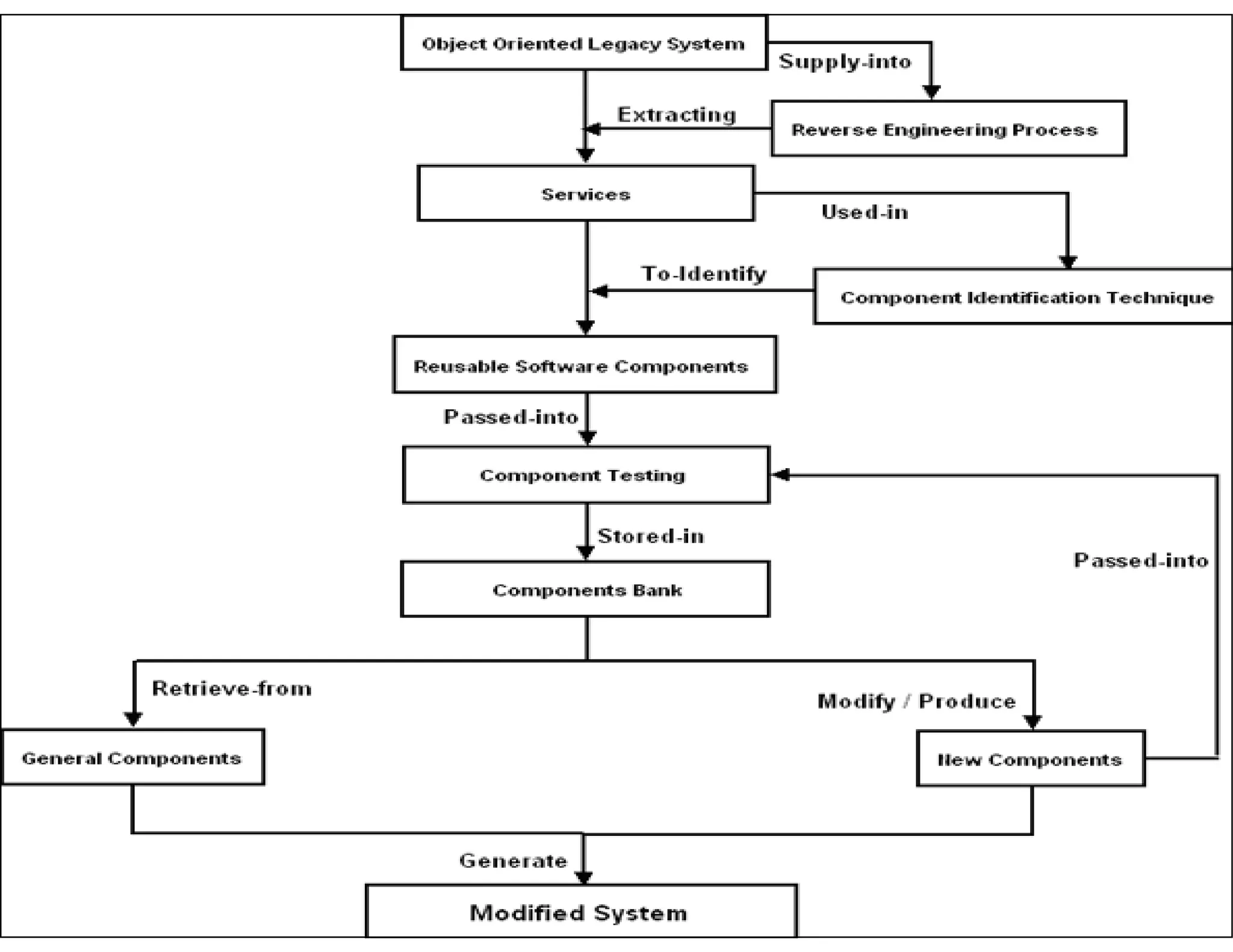
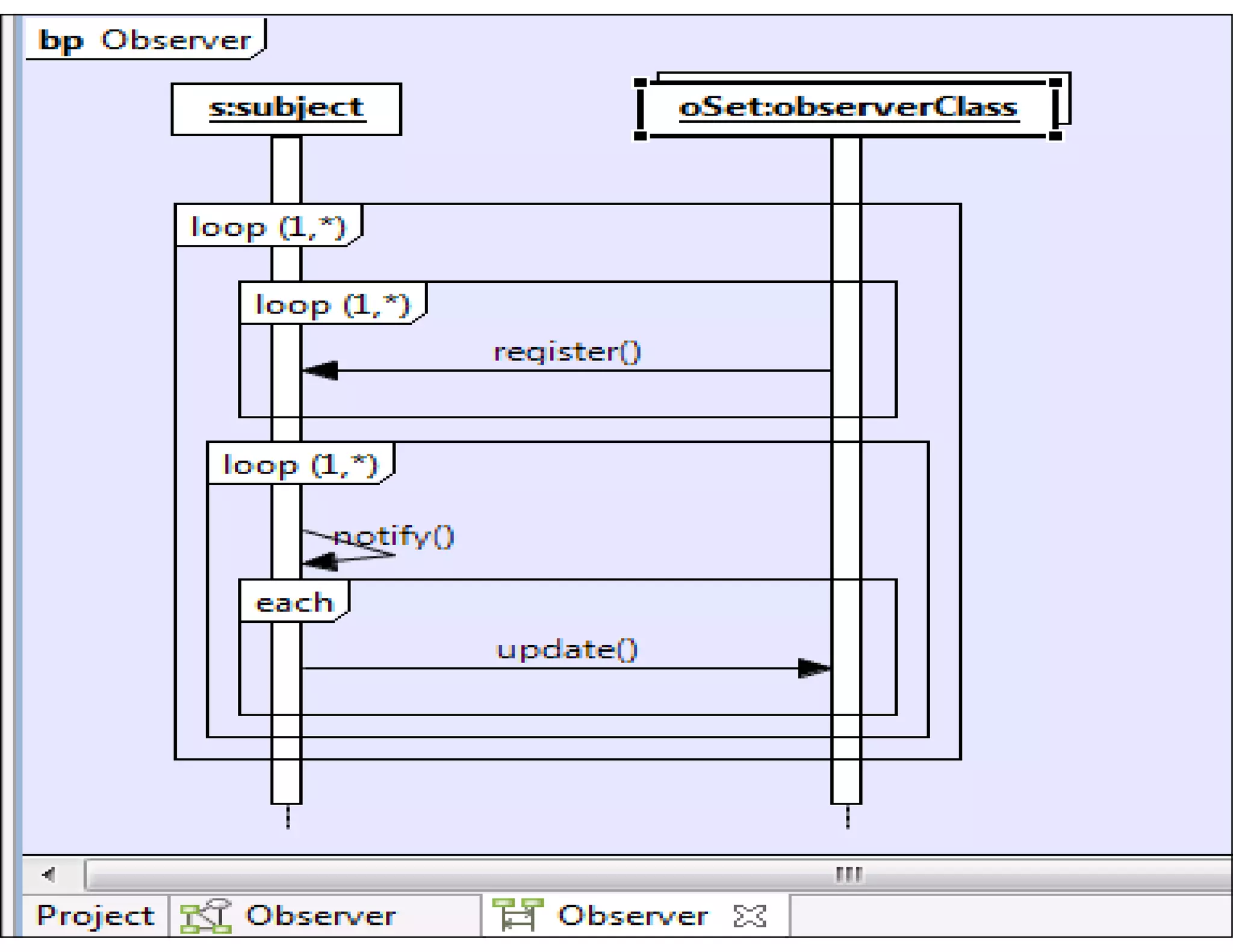
This document discusses reverse engineering software programs. It begins by defining reverse engineering as the process of understanding how a machine works by examining its behavior and structure without access to internal designs. It describes using debuggers and disassemblers to analyze a program's logical flow and machine code. The document notes that reverse engineering provides critical insights into how a program functions, which can enable changing its structure and patching code. While it can be used for good or bad ends, common techniques discussed include error tracing, input tracing, and using breakpoints to speed up the decompilation process.