Downloaded 11 times





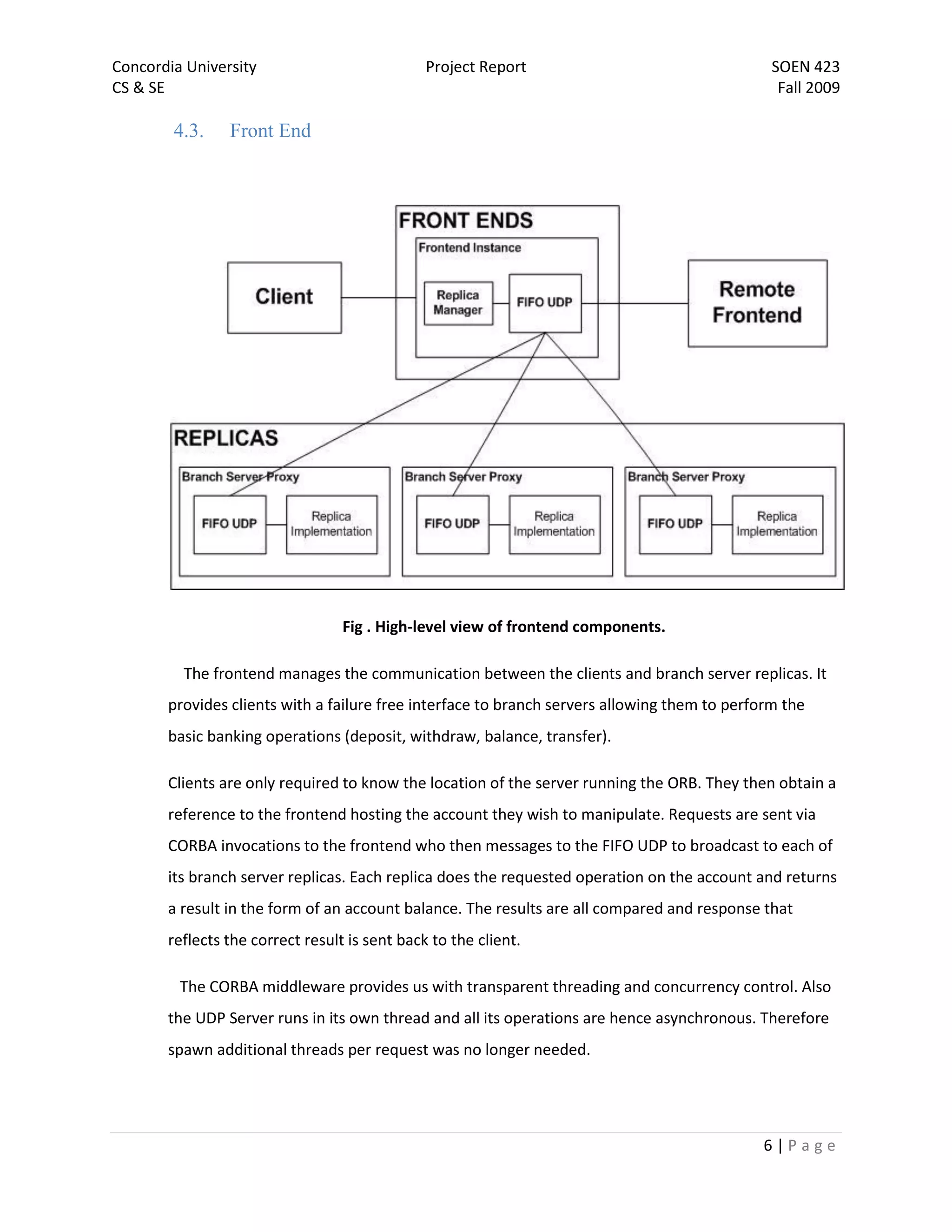




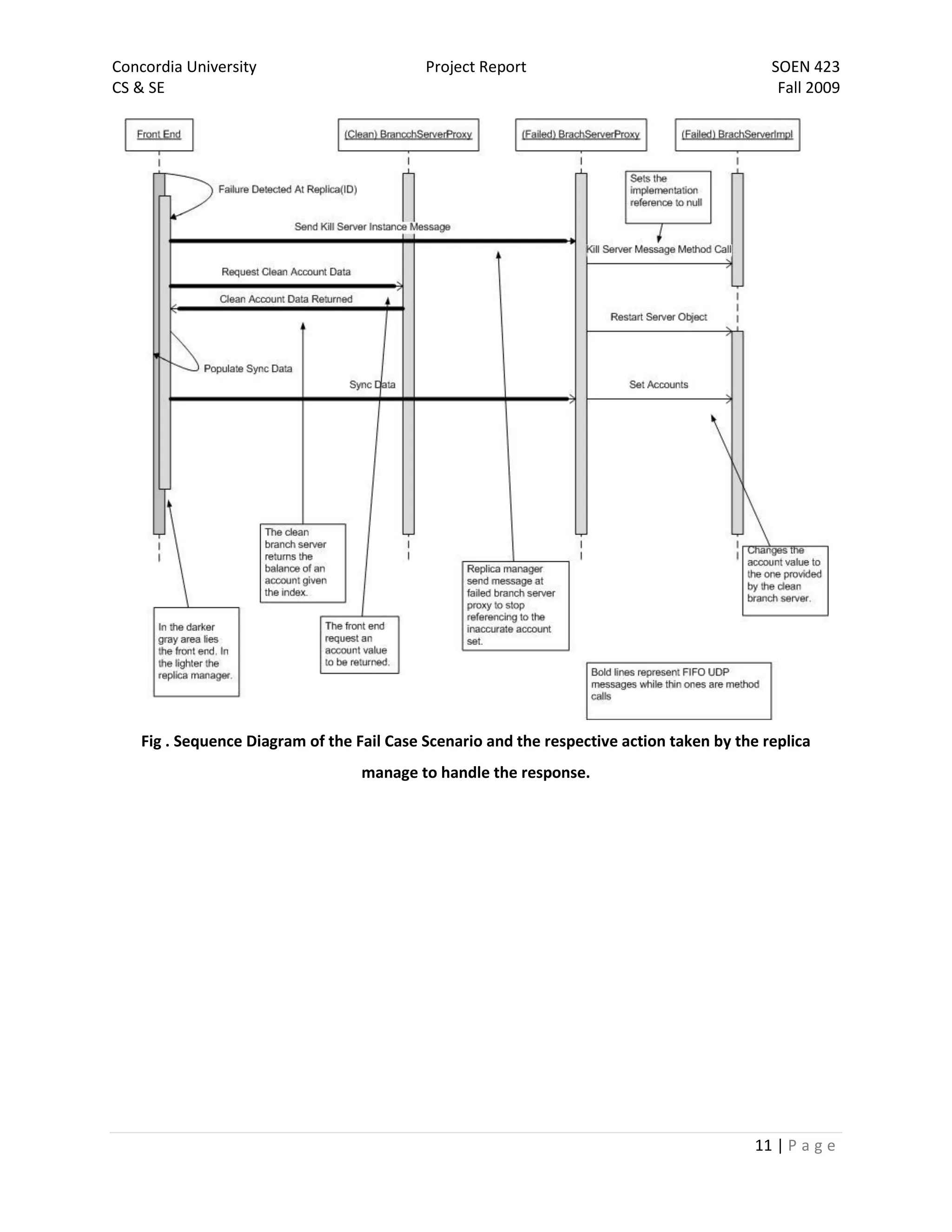





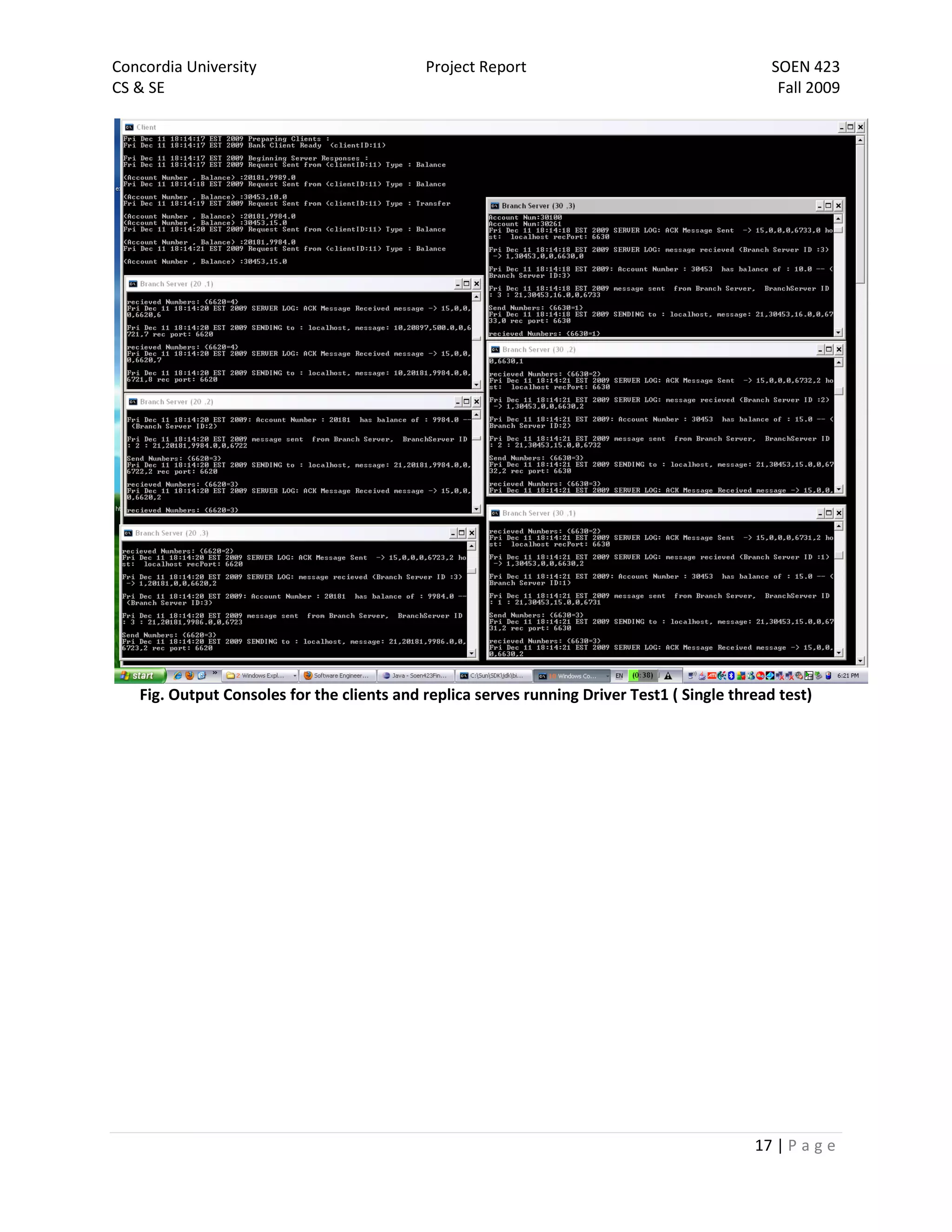
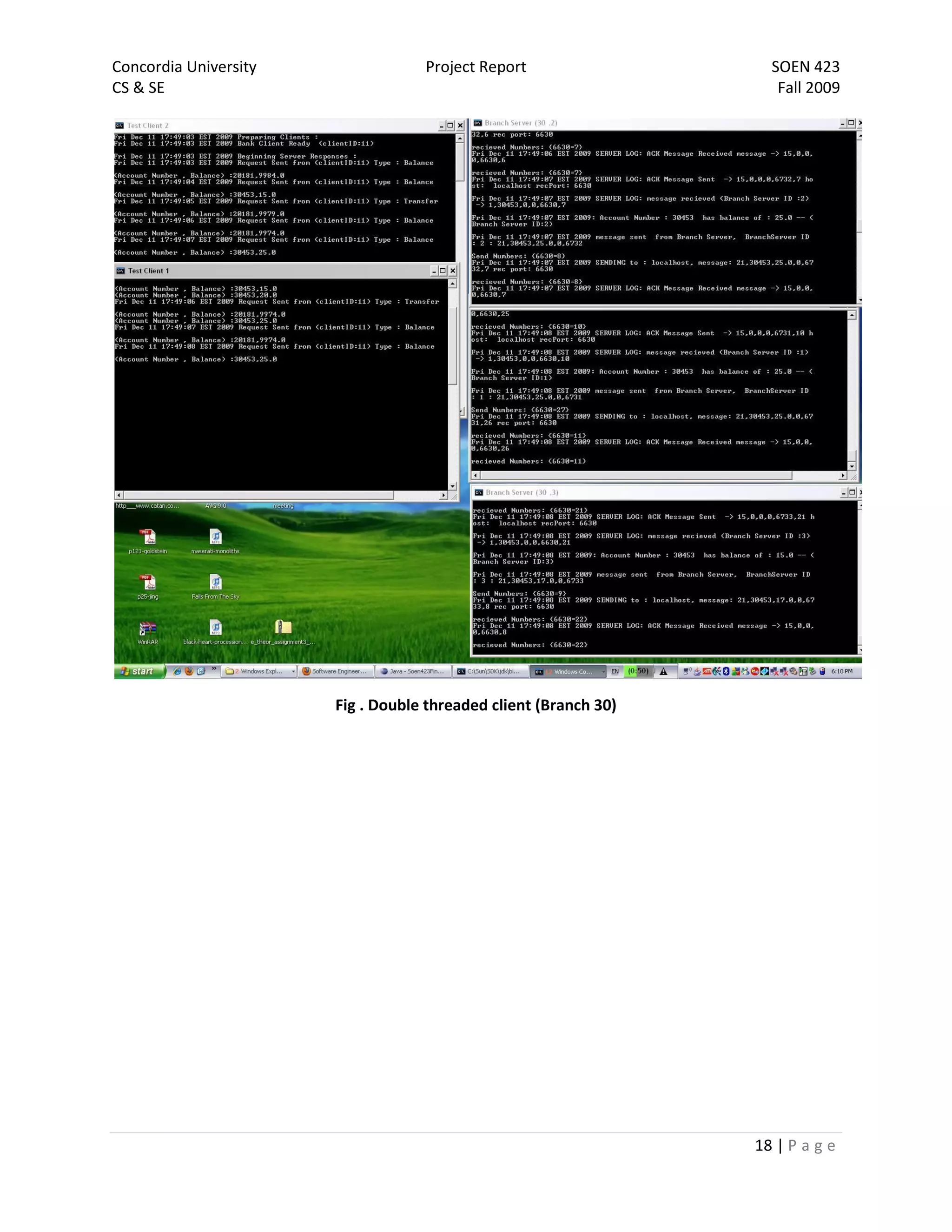
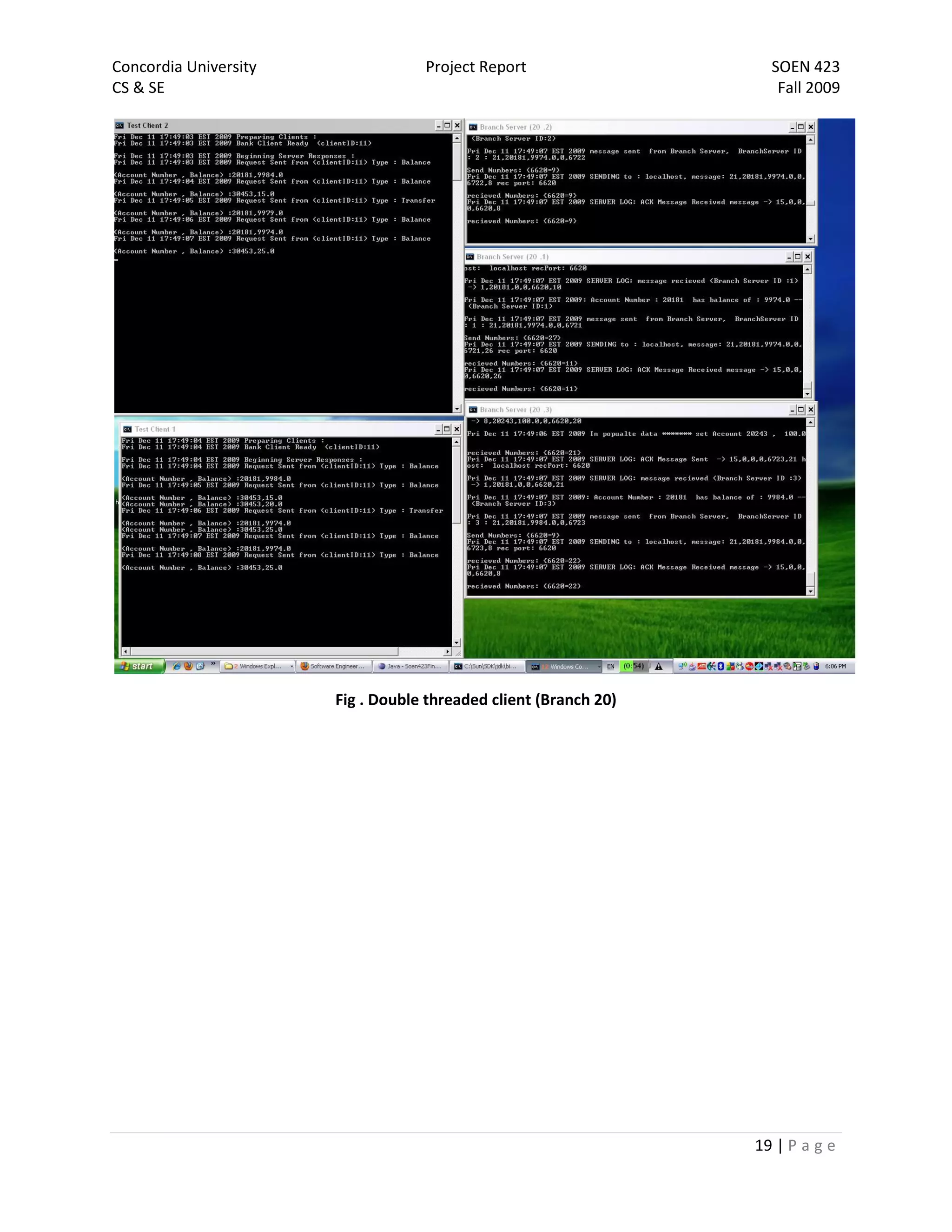
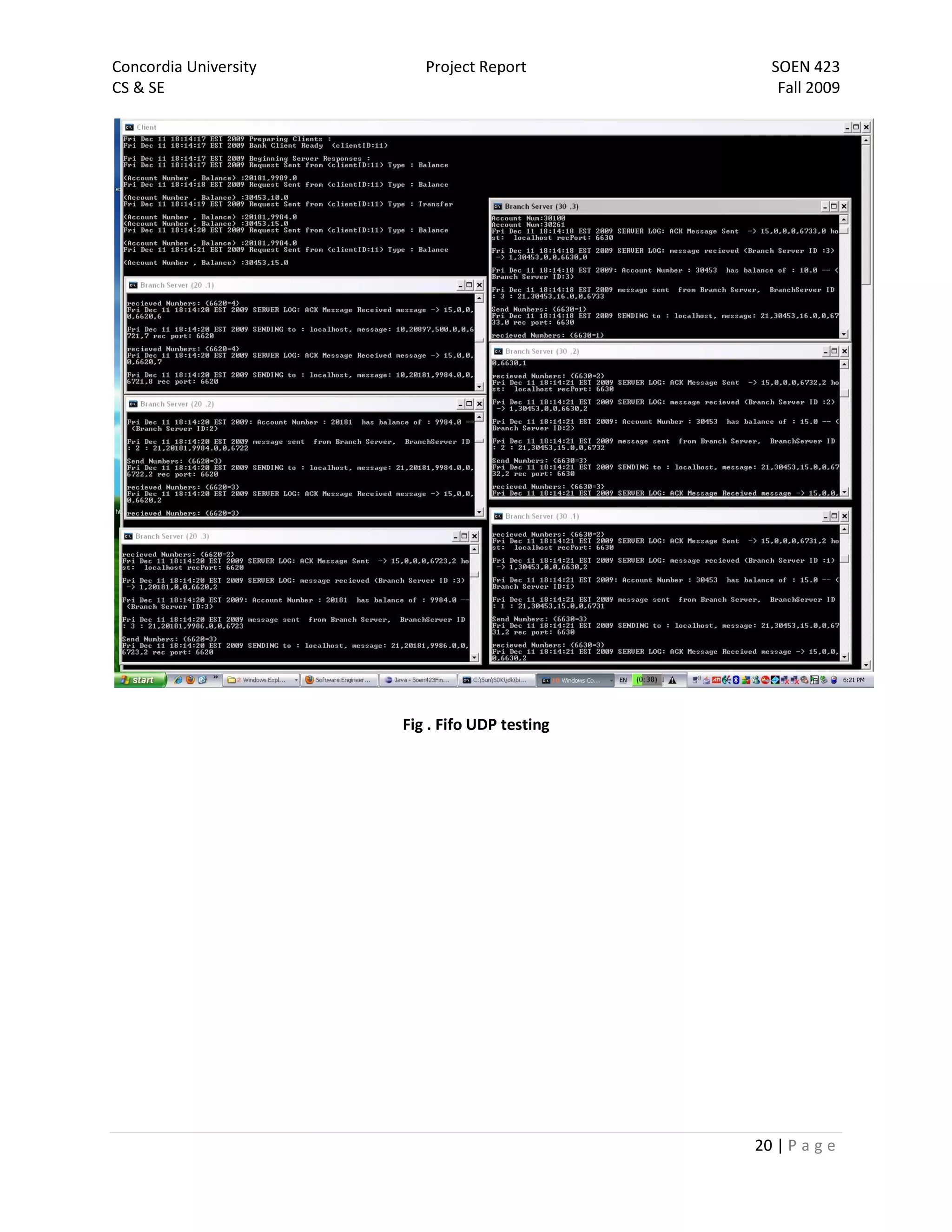


The document is a project report for SOEN 423 at Concordia University, detailing a distributed banking system developed by a team. It covers the problem statement, system design, implementation details, and testing, with specific focus on features like a failure-free front end and reliable communication. The implementation successfully meets project requirements, providing correct results in varying scenarios.























































































