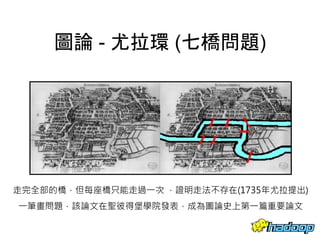
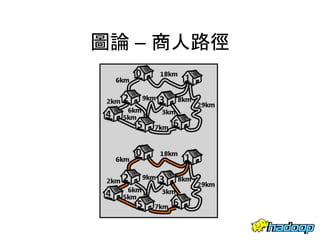
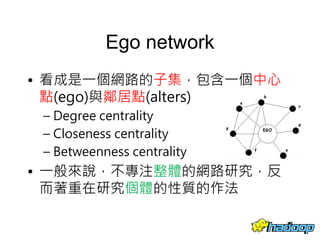
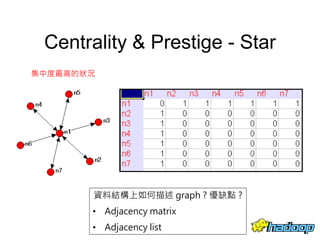
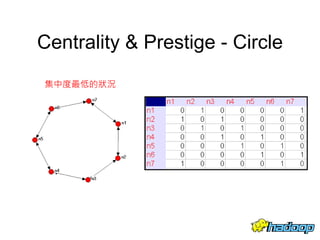
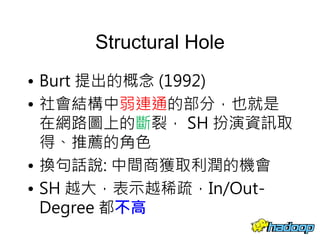
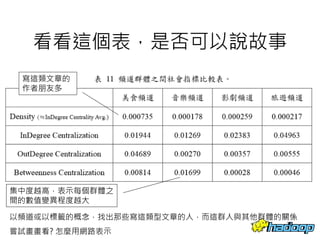
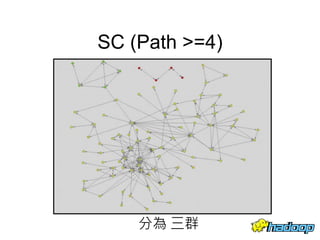
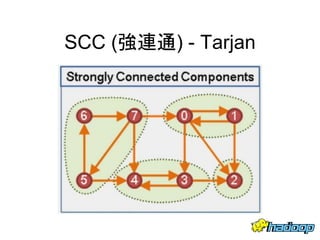
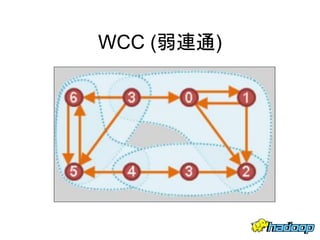
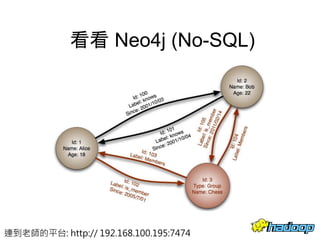
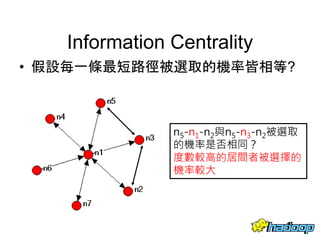
本文件介绍了社交网络分析和图论的基础知识,讨论了不同的中心性指标,如度中心性、接近中心性和中介中心性,以及它们在社交网络中的应用。文中还提到诸如六度分隔理论和信息中心性的相关概念,并探讨了如何用算法和数据结构来优化和解决图形问题。最后提供了与社交网络分析相关的工具和资源。