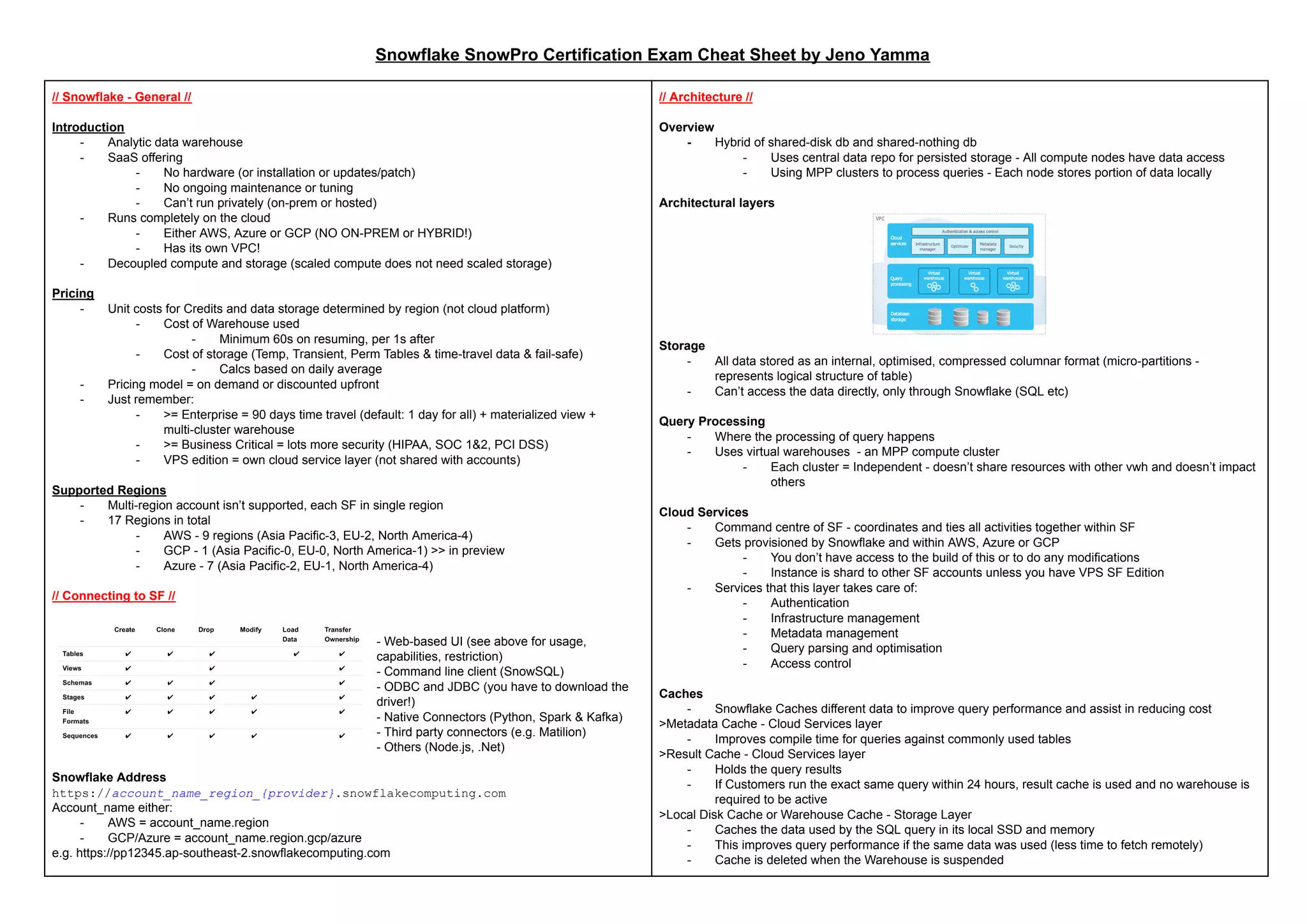
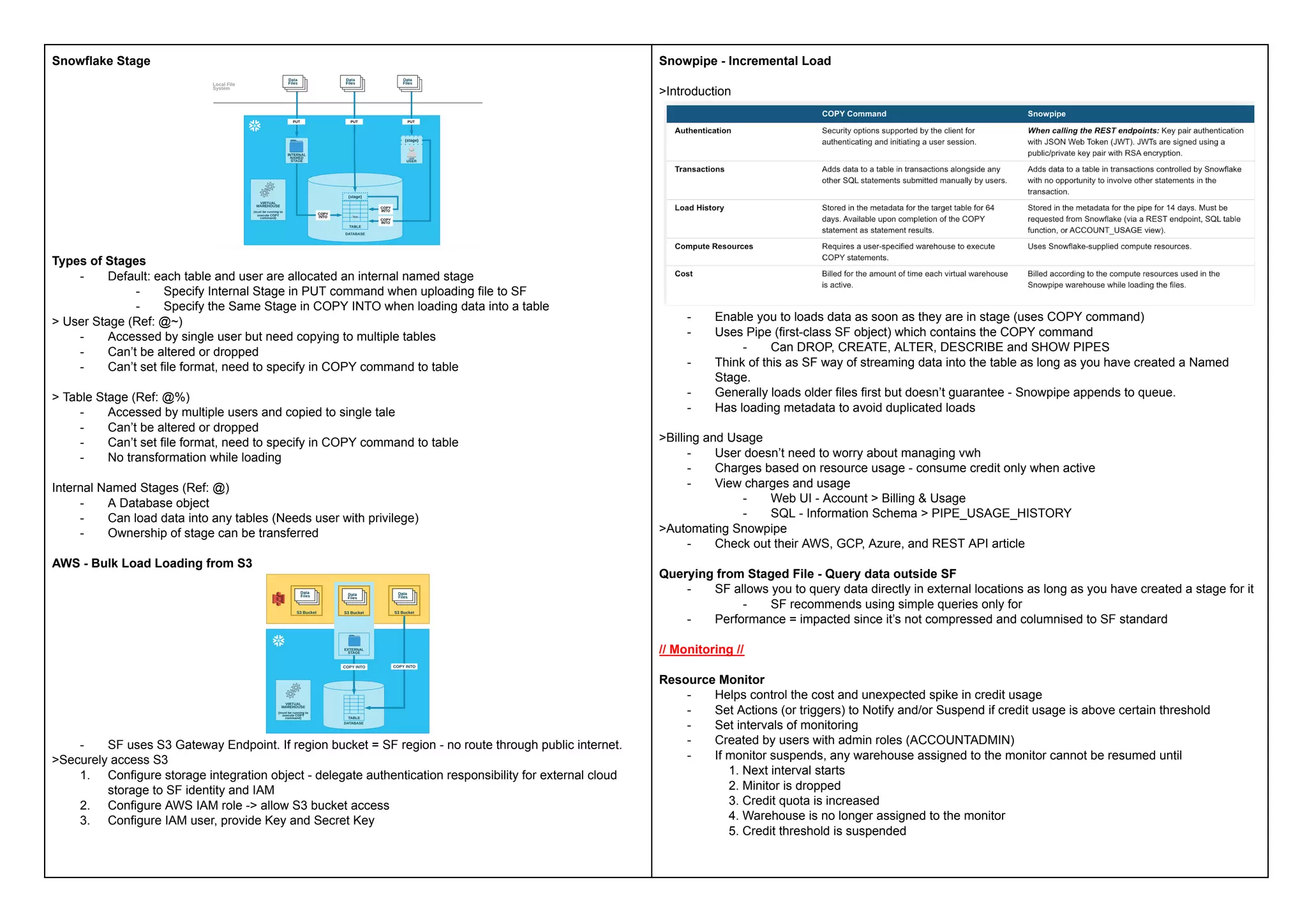
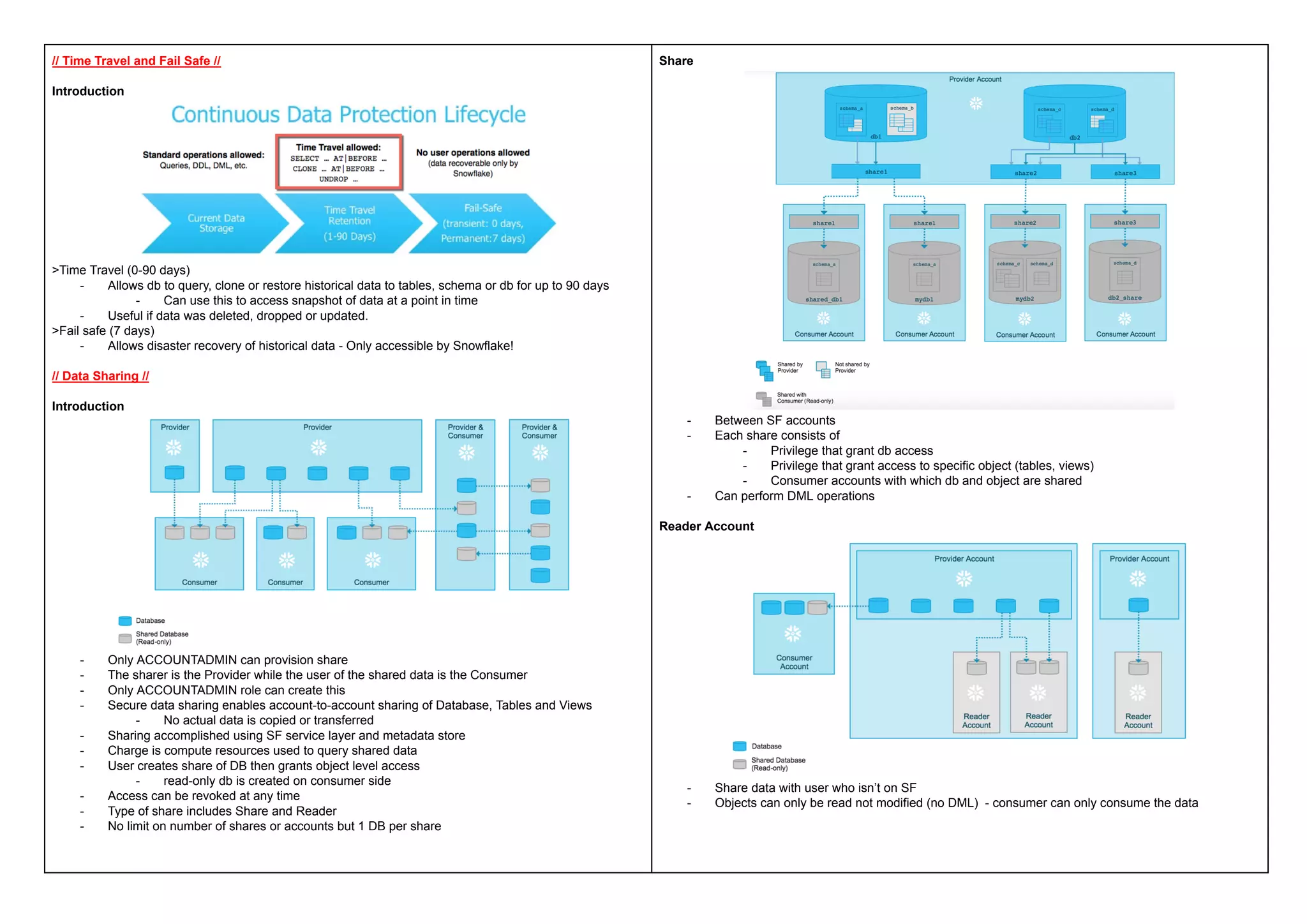
This document provides a comprehensive overview of Snowflake's architecture, pricing, data loading, and management practices, emphasizing its cloud-based, data warehousing capabilities. Key features include on-demand or discounted pricing, decoupled compute and storage, and support for various data types and formats. Additionally, it covers aspects of data transformation, monitoring, and sharing, along with operational guidance for optimizing performance and managing resources.