This document discusses different graph query languages such as SQL, SPARQL, and Gremlin and provides examples of querying graph data models that were created from relational databases. It begins by introducing the authors and providing an overview of querying entity relations with different languages. Several examples are then given that demonstrate how to express common graph queries like finding connections between nodes in each language using sample data from GitHub and Northwind databases modeled as graphs.













![examples 2
common contributors of two projects
g.v('#11:47').in("contributes").as("x").out.retain([g.v('#11:57')]).back("x").login
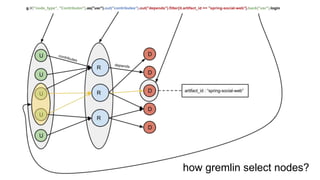
users who work on projects, using a specific library
g.V("node_type", "Contributor").as("usr")
.out("contributes")
.out("depends")
.filter{it.artifact_id == "spring-social-web"}
.back("usr")
.login](https://image.slidesharecdn.com/xgkb32ebr3kxgrghuivh-140604162952-phpapp02/85/Find-your-way-in-Graph-labyrinths-17-320.jpg)
![examples 3
five most used libraries
g.V("node_type", "Dependency").inE("depends").inV.groupCount{it.artifact_id}.cap.orderMap(T.
decr)[0..4]
contributors of projects with more than ten contributors
g.V("node_type", "Repository").filter{it.inE("contributes").count() > 10}.in("contributes").login](https://image.slidesharecdn.com/xgkb32ebr3kxgrghuivh-140604162952-phpapp02/85/Find-your-way-in-Graph-labyrinths-19-320.jpg)

























































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)










