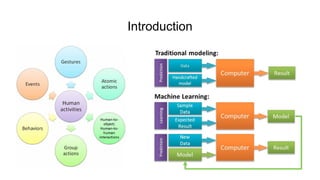
This document presents a thesis on using recurrent neural networks for skeleton-based human action recognition. The proposed method uses two RNNs - a temporal RNN to model the temporal dynamics of joints over time, and a spatial RNN to model the dependencies between joints spatially. The RNNs are trained on skeleton data extracted from video datasets like NTU RGB+D and Kinetics. Experimental results show the method achieves state-of-the-art accuracy on the NTU datasets and can recognize actions in real-time from new video inputs. Future work involves exploring more advanced temporal modeling and evaluating on larger datasets.













































![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2020 [O3-01] Extreme 3D センシング](https://cdn.slidesharecdn.com/ss_thumbnails/200612-ssii-extreme3dsensing-print3-200608114658-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]HoloGAN: Unsupervised learning of 3D representations from natural images](https://cdn.slidesharecdn.com/ss_thumbnails/hologanslideshare-190906010228-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]3D Human Pose Estimation @ CVPR’19 / ICCV’19](https://cdn.slidesharecdn.com/ss_thumbnails/190816dlseminar3dhpe-190816032821-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=640&height=640&fit=bounds)

![[20240812_LabSeminar_Huy]Spatio-Temporal Fusion for Human Action Recognition ...](https://cdn.slidesharecdn.com/ss_thumbnails/20240812labseminarhuyjtformer-240820045816-732e4933-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NS][Lab_Seminar_250512]Context-based Interpretable Spatio-Temporal Graph Con...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250512cist-gcn-250512120201-79318fd1-thumbnail.jpg?width=640&height=640&fit=bounds)





![[NS][Lab_Seminar_240923]Prompt-supervised Dynamic Attention Graph Convolution...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240923pda-gcn-240924122920-dcc31601-thumbnail.jpg?width=640&height=640&fit=bounds)
![[20240902_LabSeminar_Huy]Dynamic Semantic-Based Spatial Graph Convolution Net...](https://cdn.slidesharecdn.com/ss_thumbnails/20240902labseminarhuyds-gcn-240902113404-3ec0de5d-thumbnail.jpg?width=640&height=640&fit=bounds)
![240325_Thanh_LabSeminar[SkeletalGNN].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240325thanhlabseminarskeletalgnn-240409103130-afc3c703-thumbnail.jpg?width=640&height=640&fit=bounds)





































