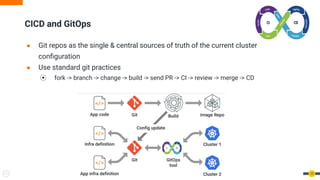
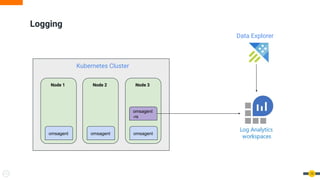
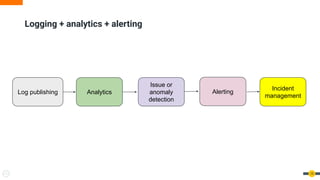
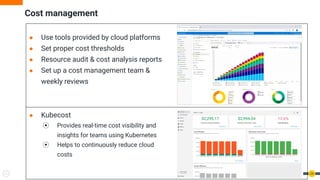
The document discusses software reliability engineering (SRE) practices for managing Kubernetes clusters. It describes how SRE teams use infrastructure as code, continuous integration/delivery (CI/CD), monitoring, logging, incident response processes, and other methodologies to ensure reliability and reduce toil. The document recommends that organizations adopt SRE practices gradually by starting small, defining standards, and working closely with development teams.





















































































![[WSO2Con Asia 2014] Accelerating Mobile App Development with MBaaS](https://cdn.slidesharecdn.com/ss_thumbnails/mbaas-wso2conasia-2014-140325234640-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






























