Download as PDF, PPTX











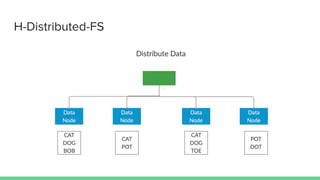




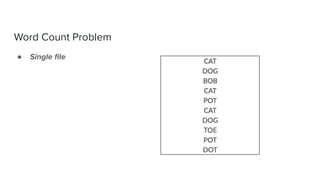
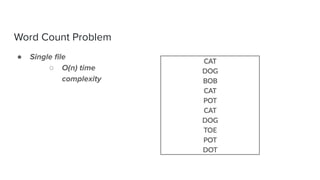
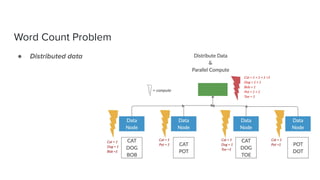
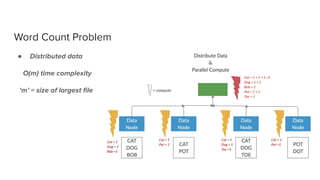
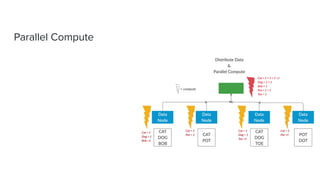
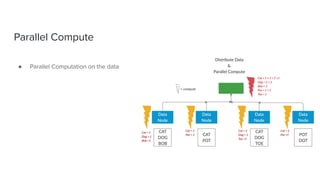
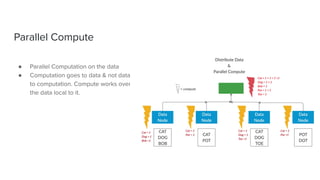
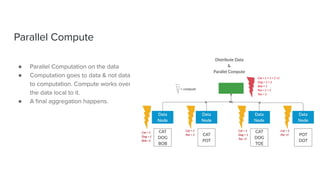
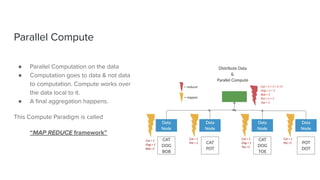






The document discusses data storage and processing. Data can be stored in memory or on disk using file systems like local XFS/ZFS or distributed systems like HDFS, S3, or Ceph. Distributed file systems allow for parallel processing of data by moving computation to the data locations. This map-reduce framework involves mapping functions to distributed data segments followed by reducing the results. Hadoop uses HDFS for storage and the MapReduce framework for distributed computation on large datasets across clusters.














































































