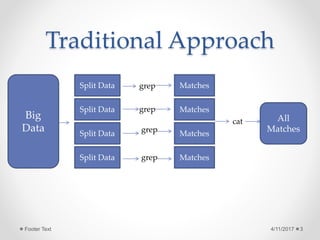
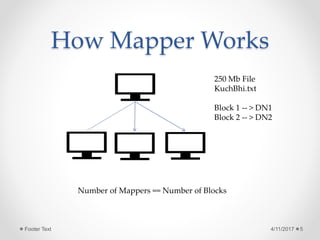
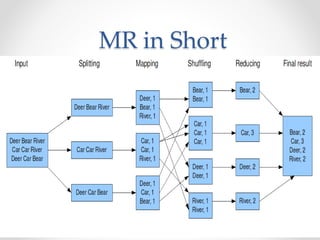
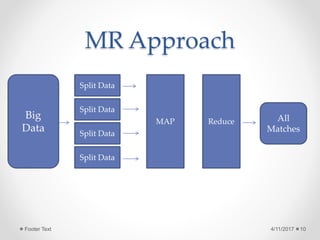
The document outlines the Hadoop development process, focusing on the MapReduce programming model and its components such as mappers and reducers. It details the workflow of MapReduce, including how data is processed in key-value pairs and describes the typical processes performed by mappers and reducers. Additionally, it hints at further practical applications to be explored in subsequent materials.