Download to read offline























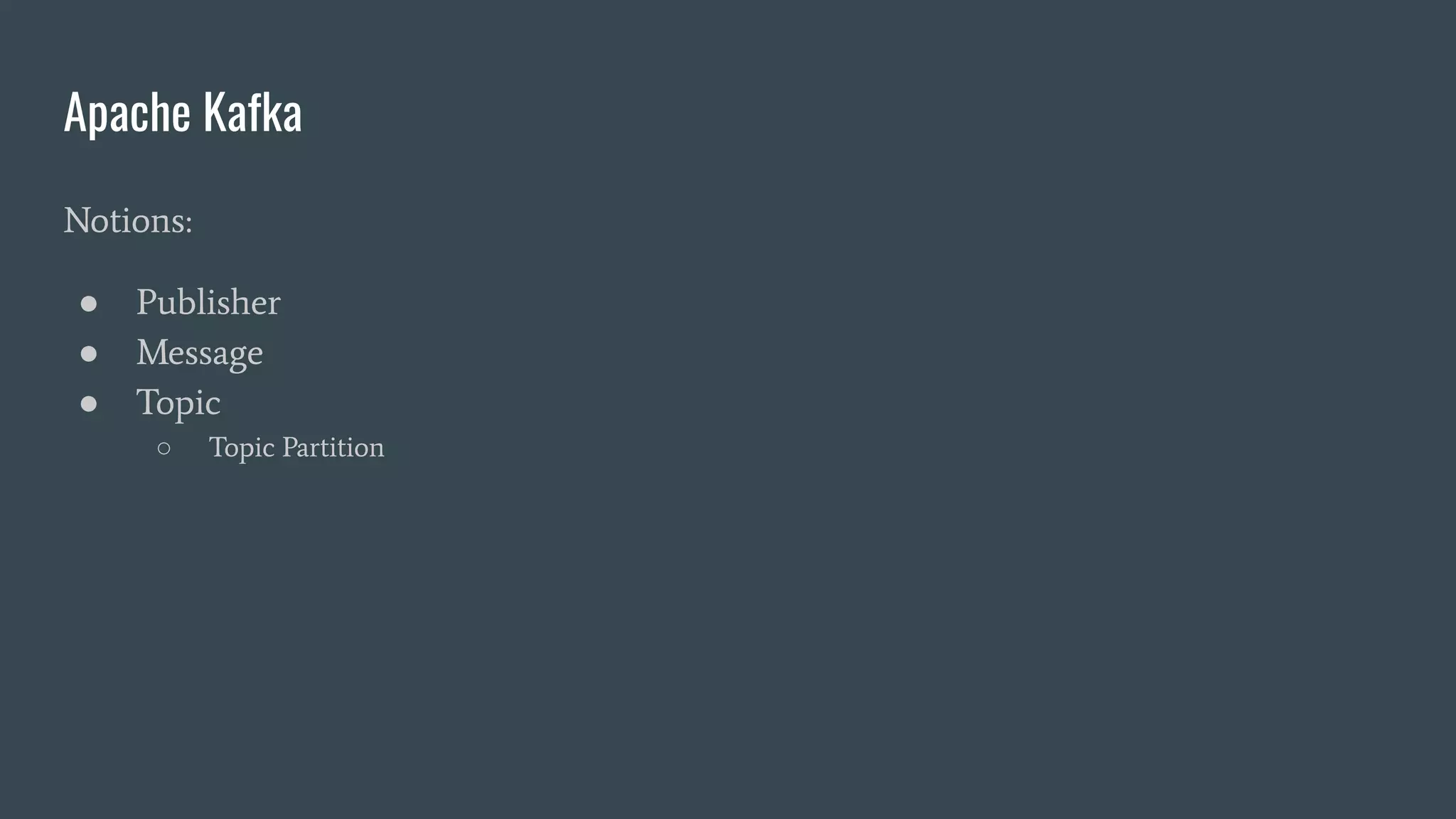


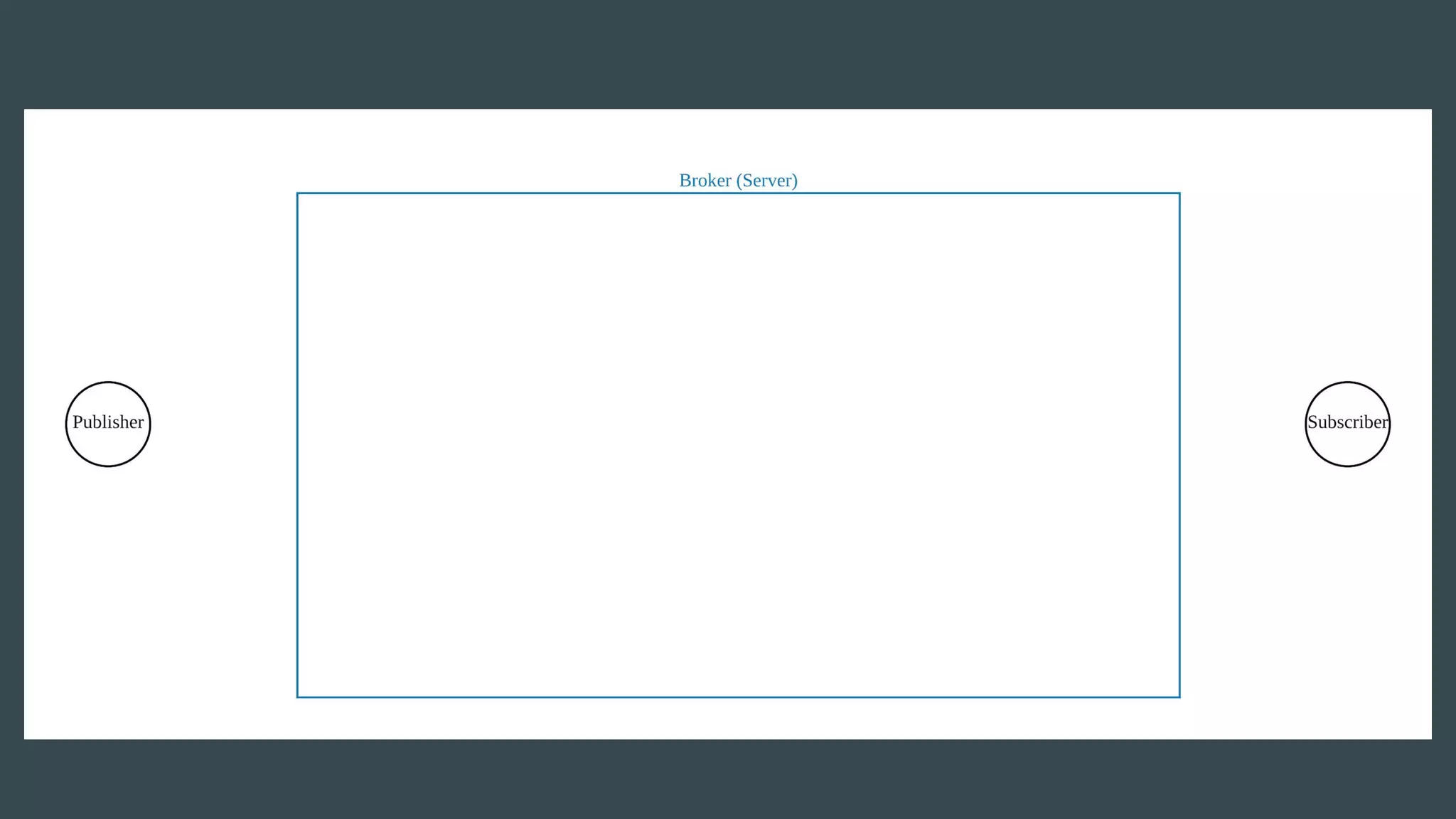
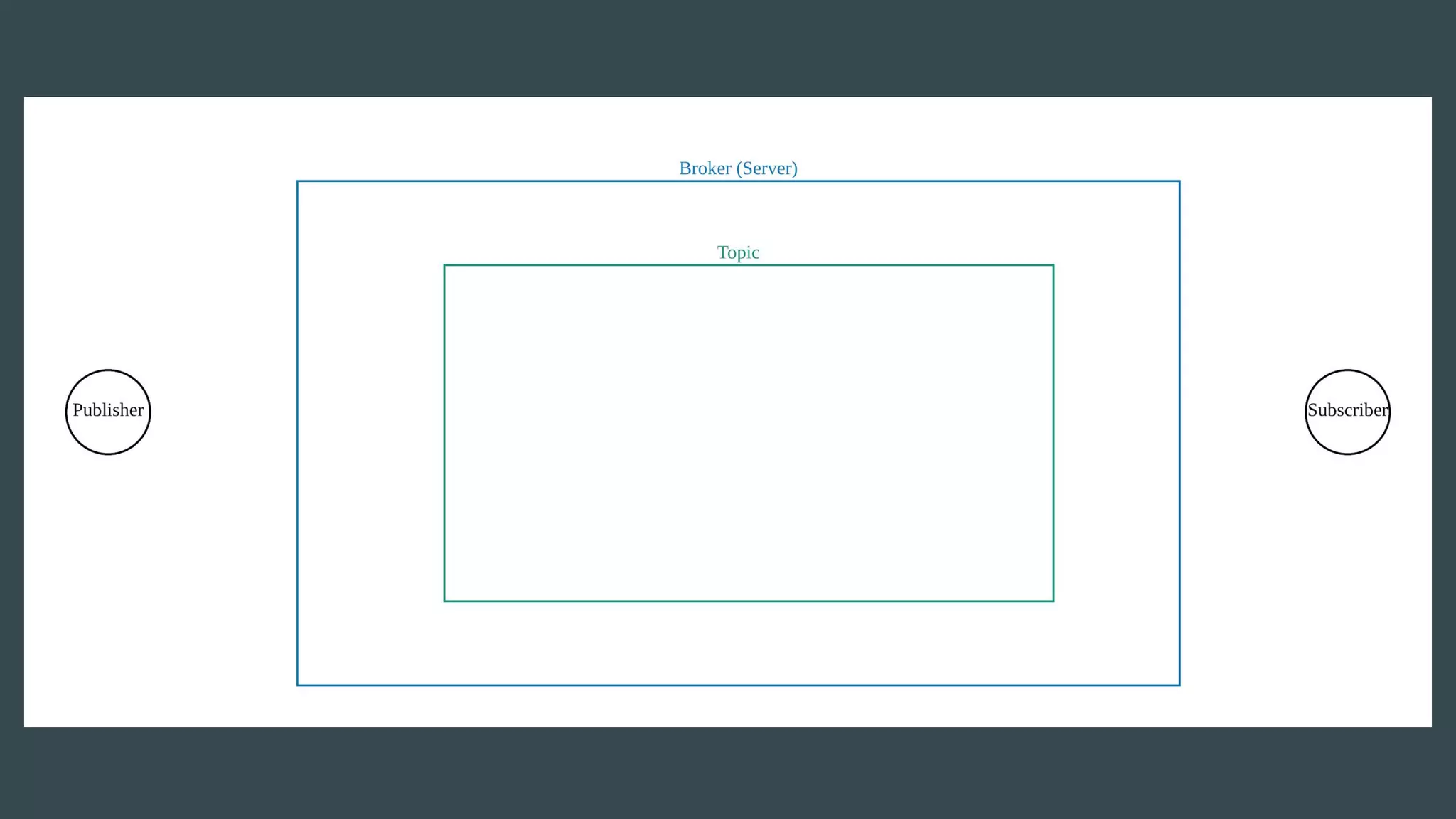
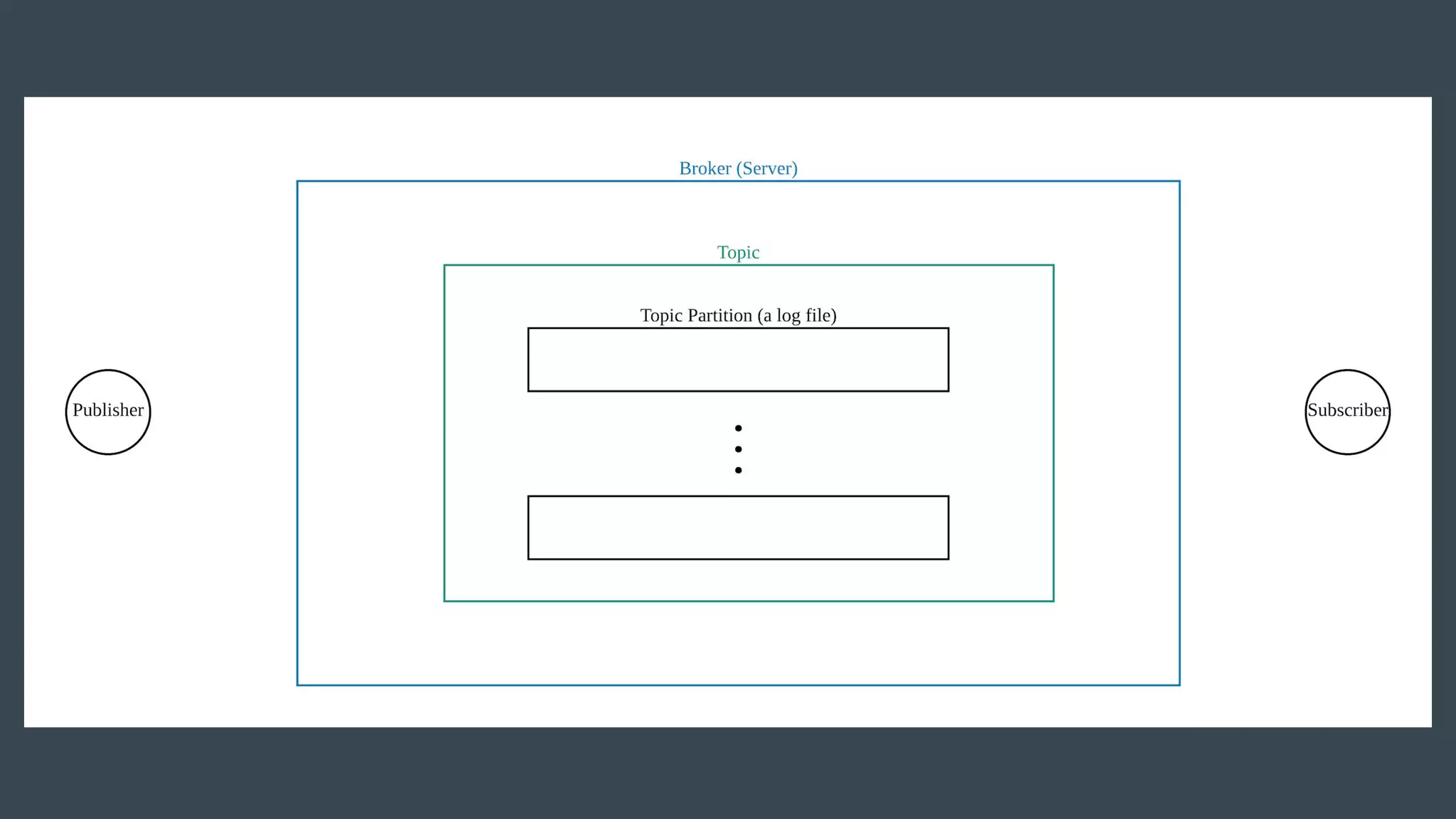
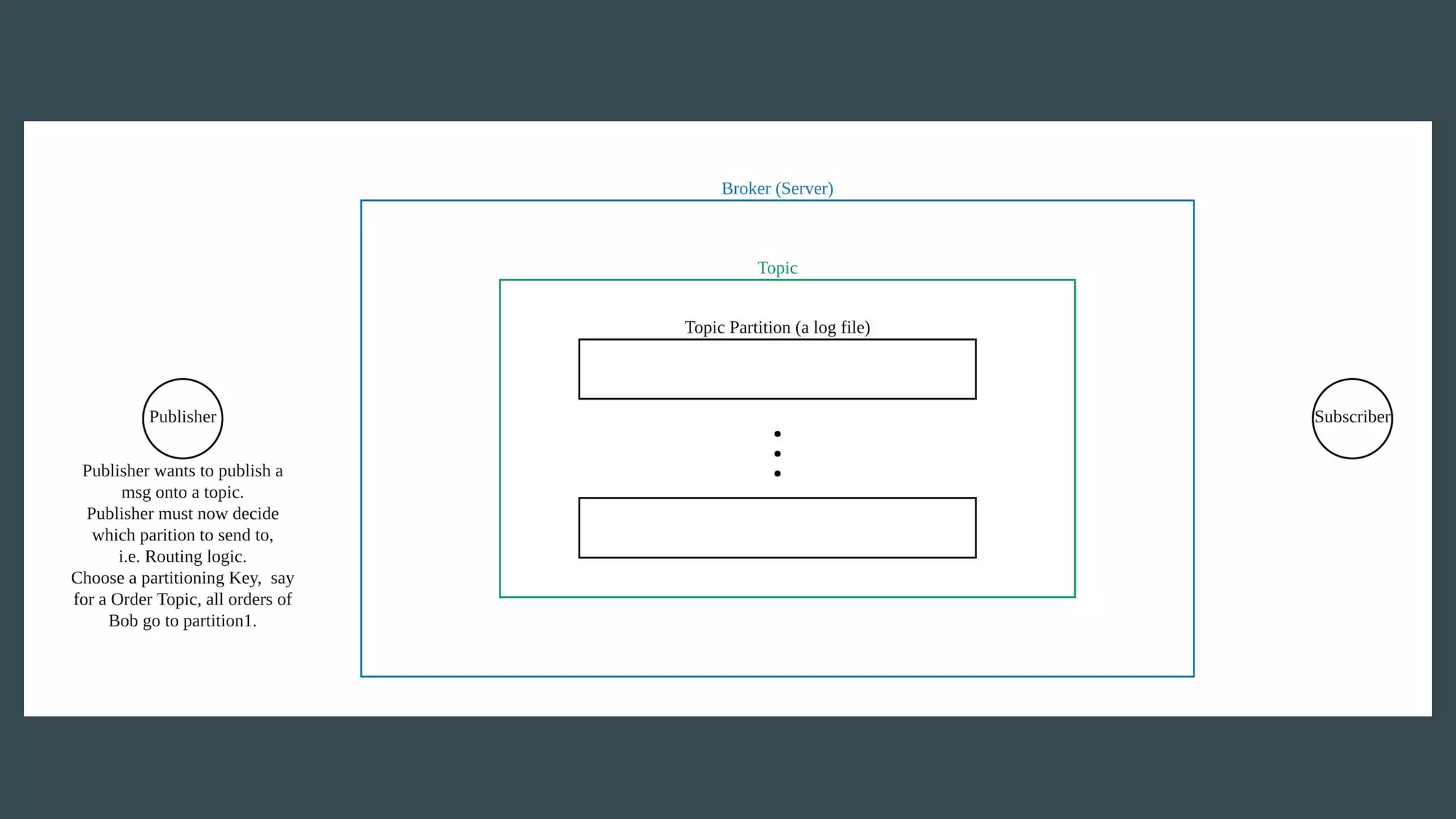
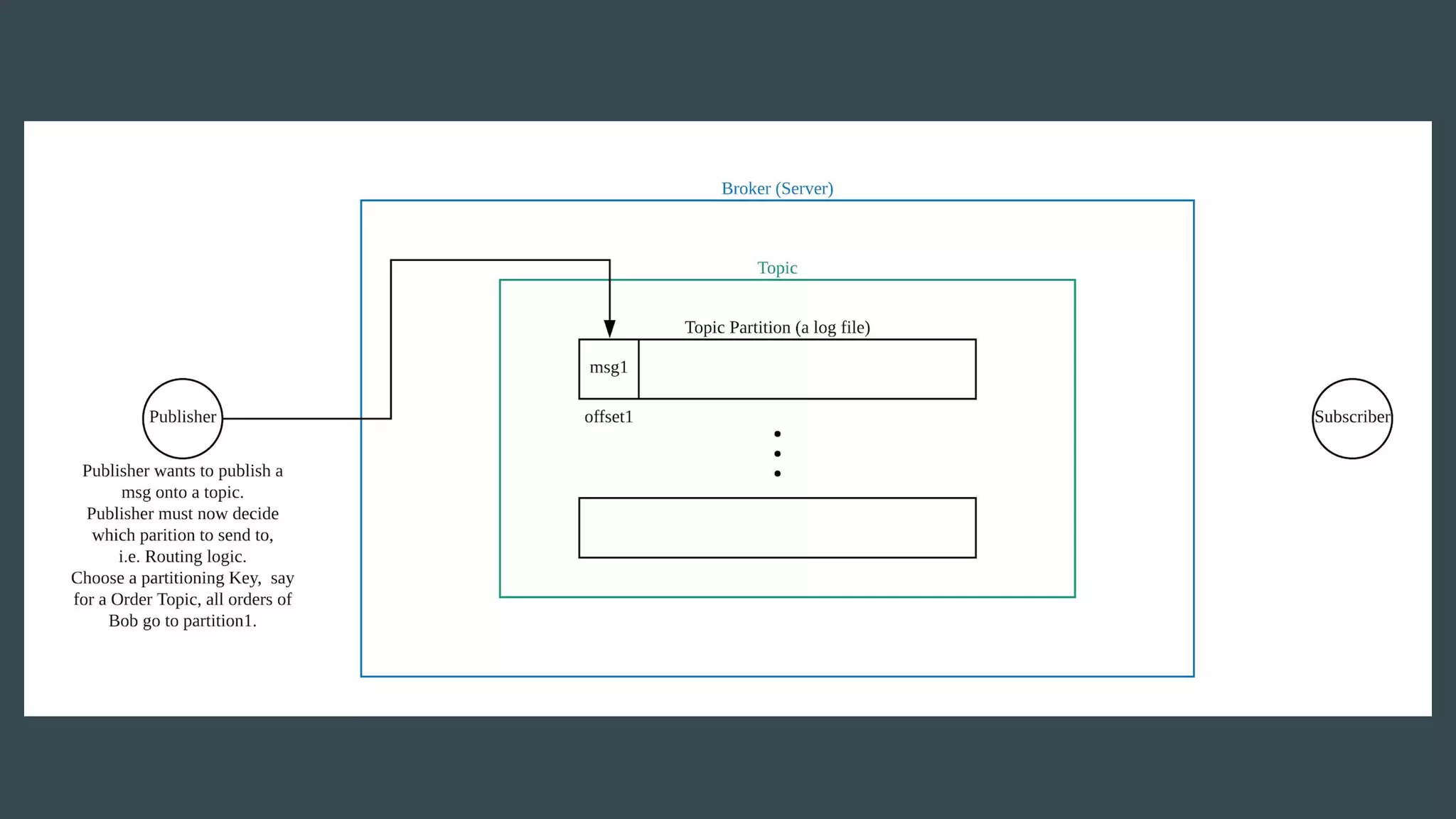
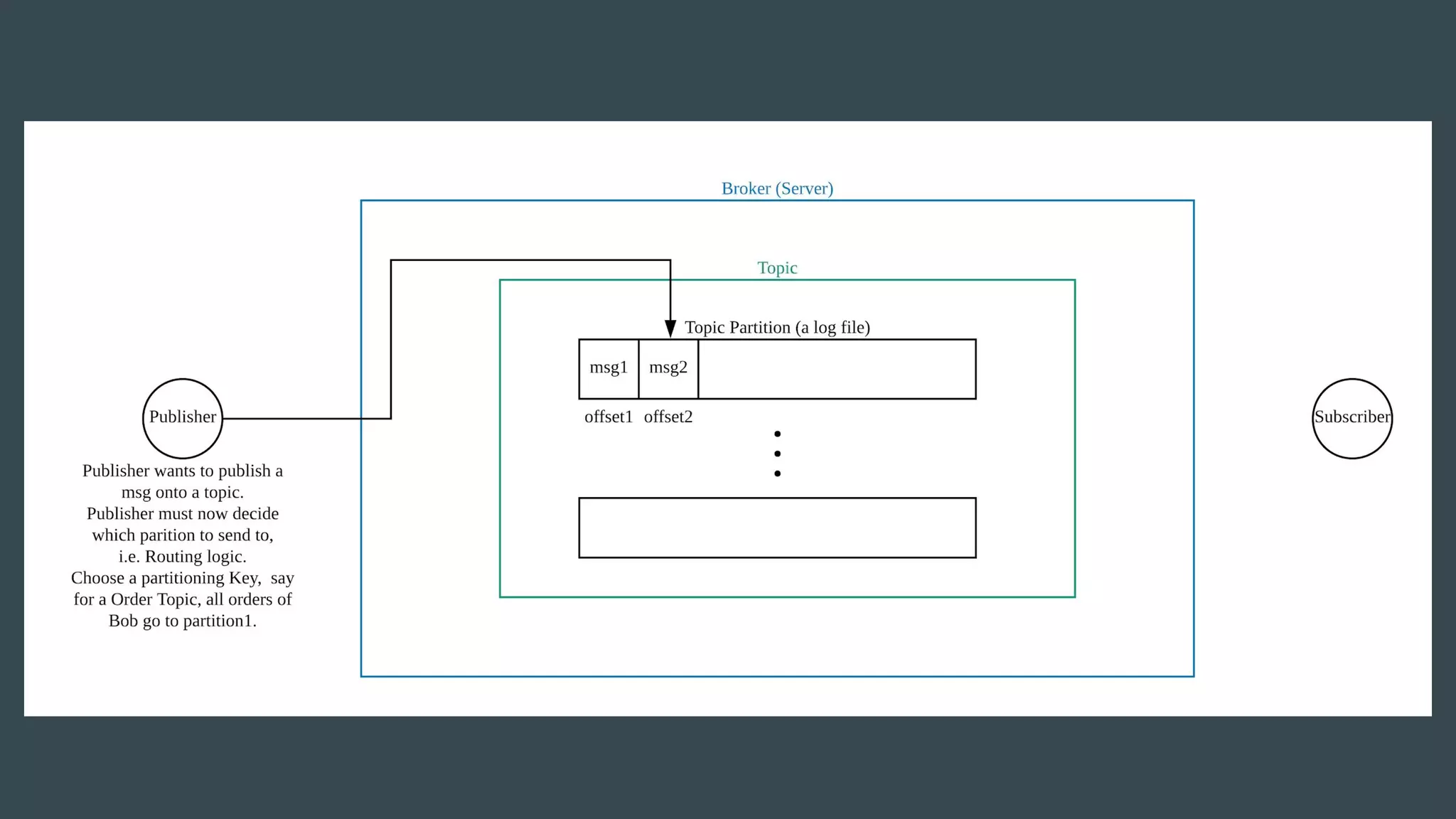
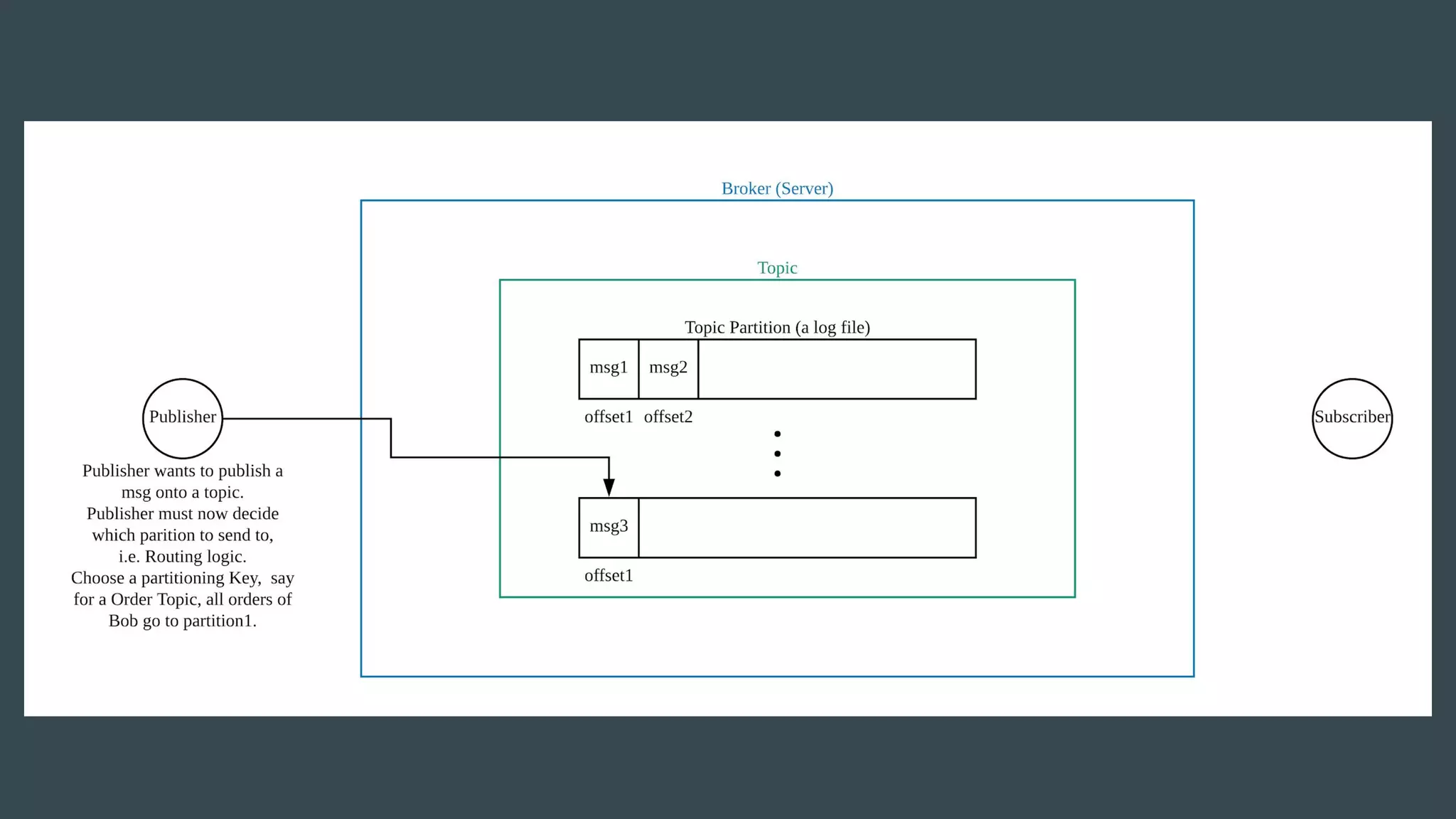
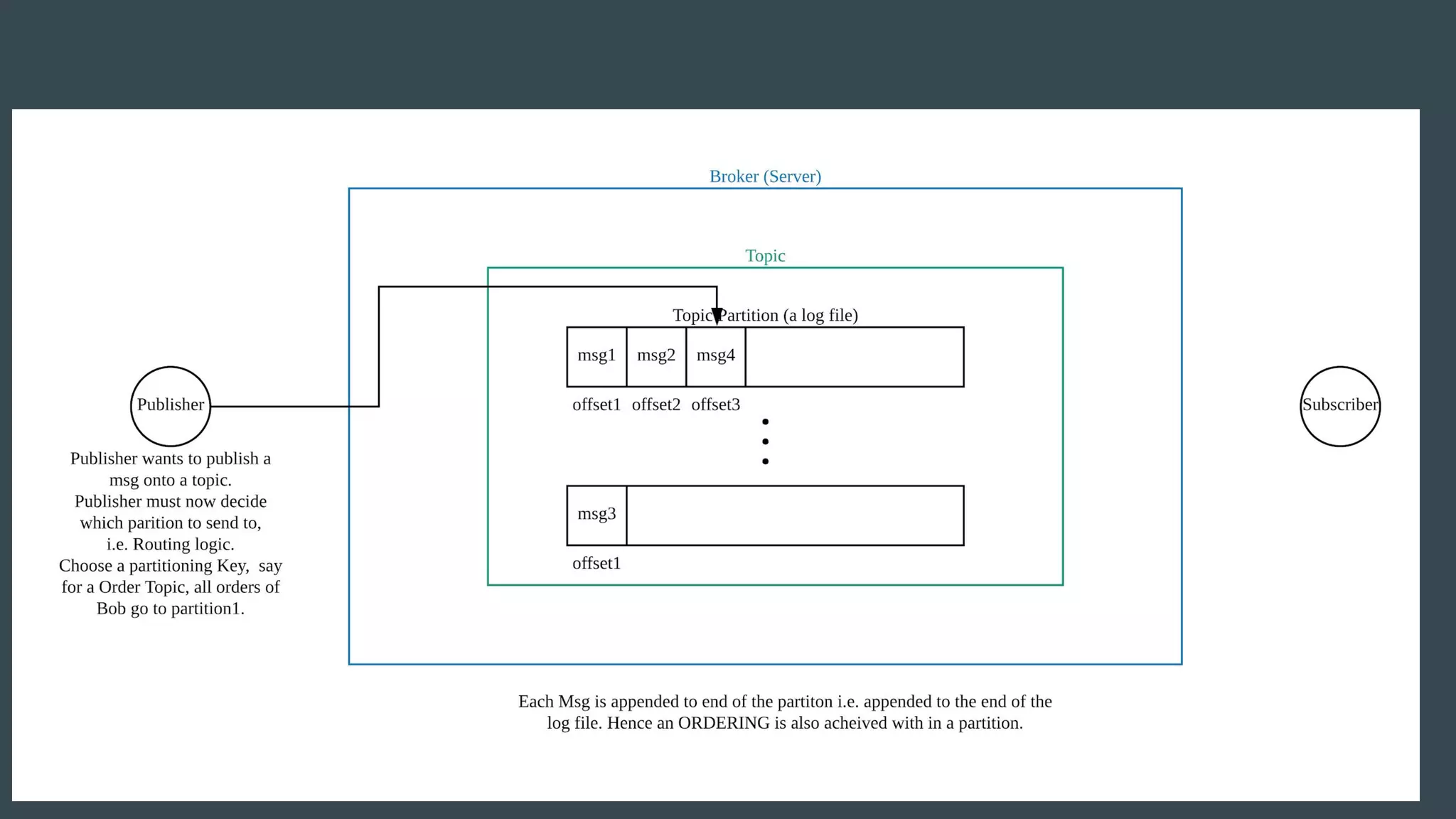
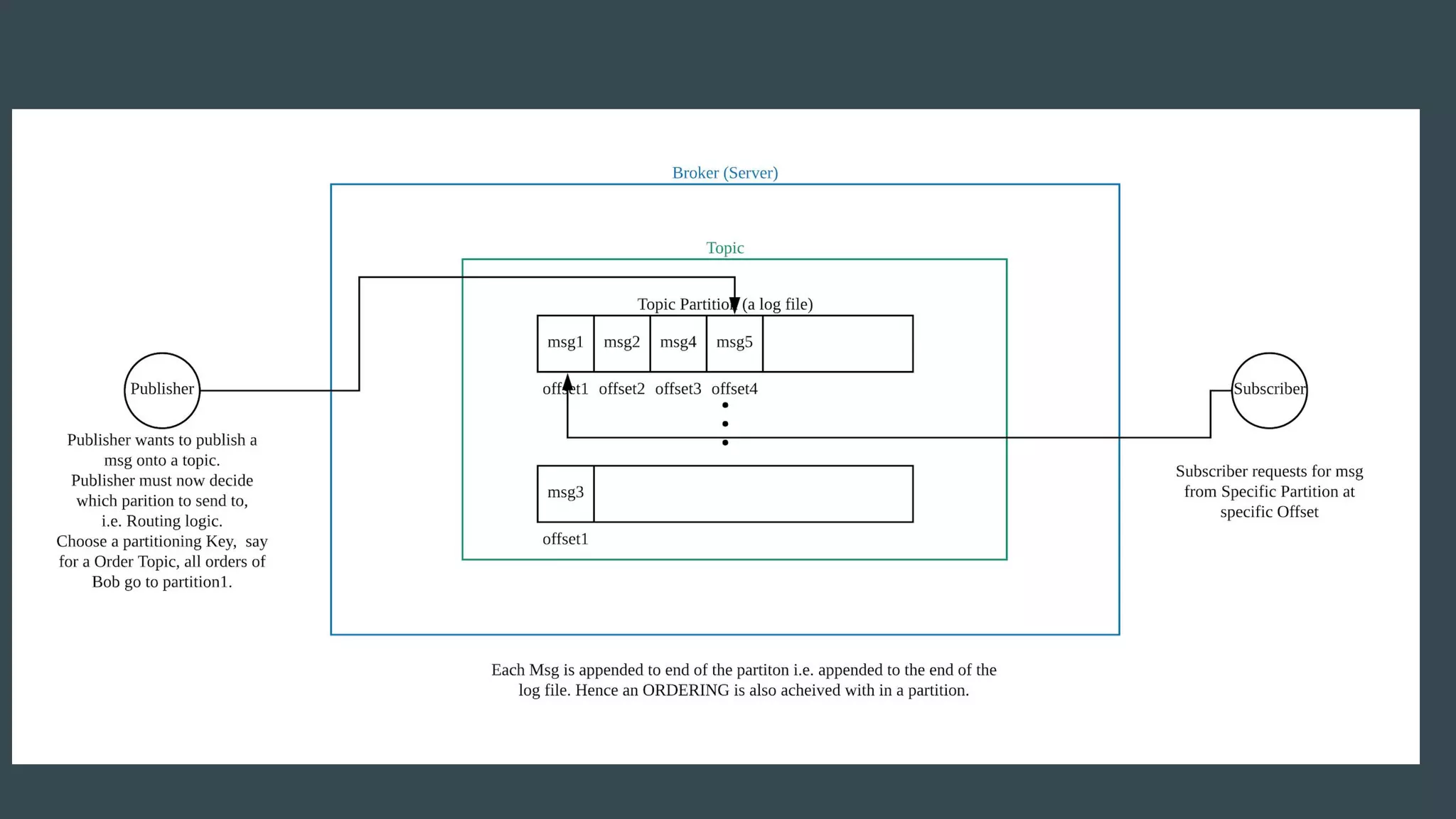
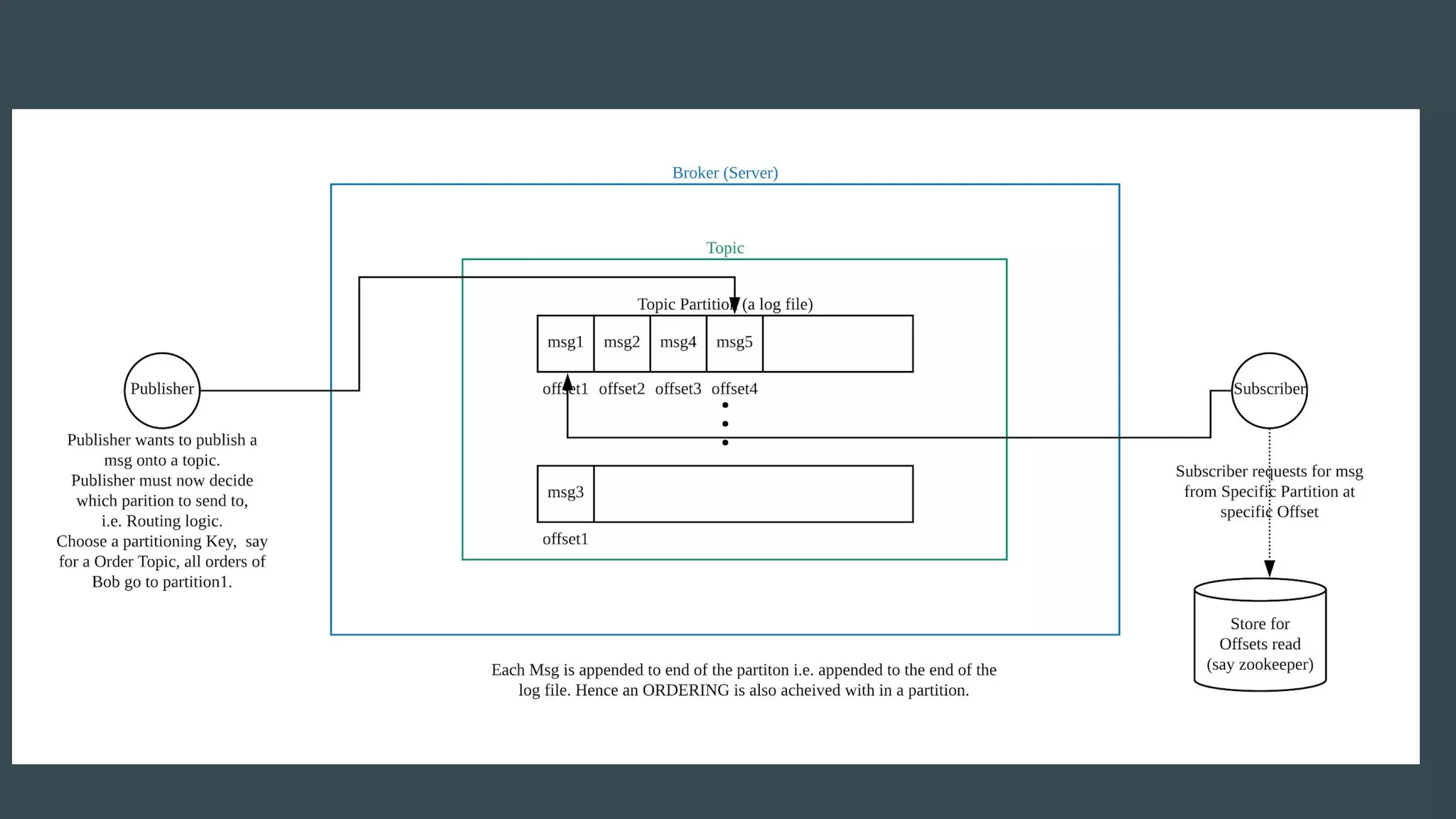







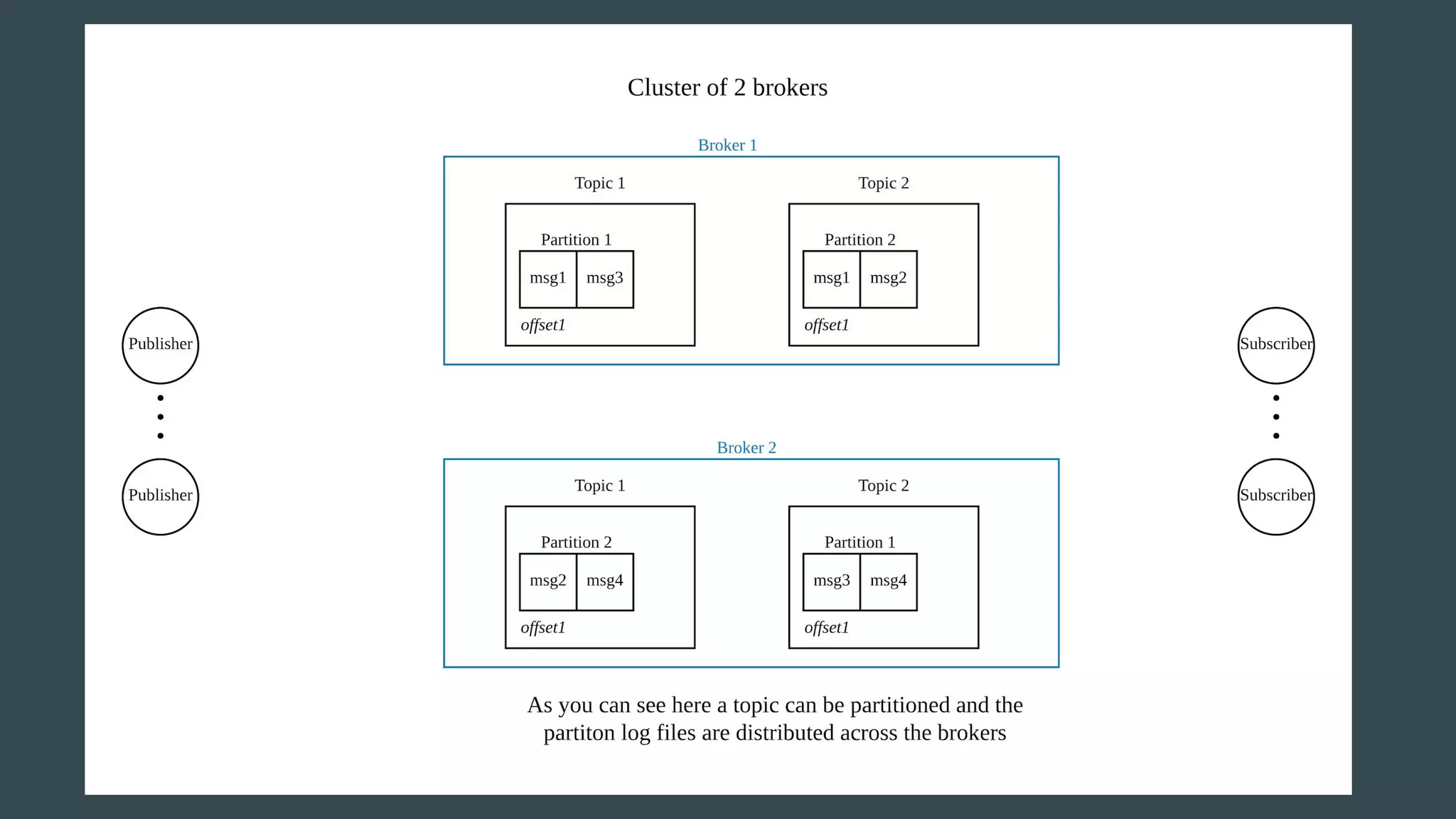
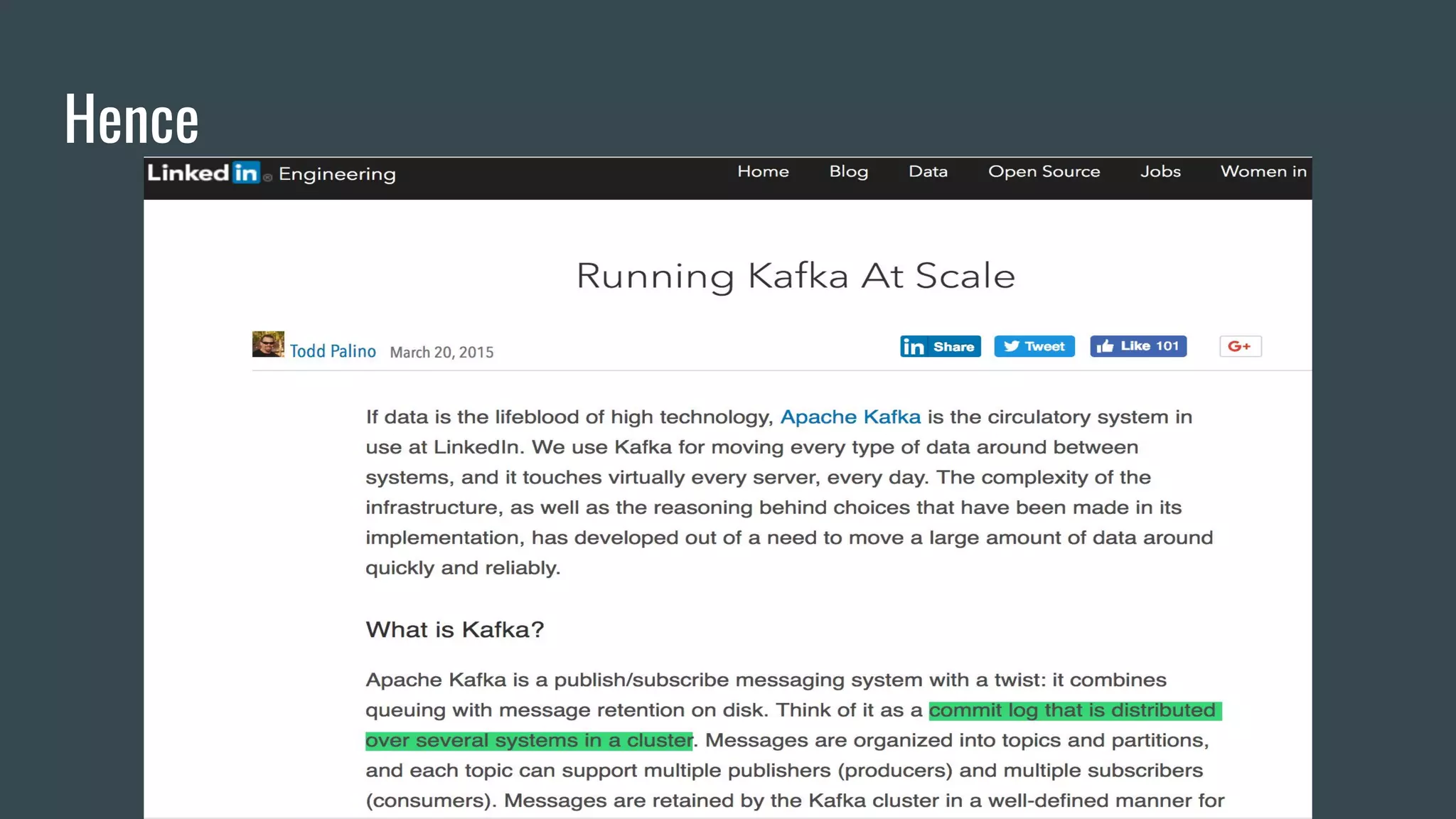

















- Publishers send messages to topics in Apache Kafka which are partitioned across brokers - Brokers append messages to the ends of partitions and subscribers can request messages from specific offsets in partitions - This allows subscribers to replay processing from any point in time as they request messages based on offset rather than relying on brokers to deliver messages
























![[@NaukriEngineering] Messaging Queues](https://cdn.slidesharecdn.com/ss_thumbnails/queueprocessing-161111064335-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)






![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)




