Download as PDF, PPTX














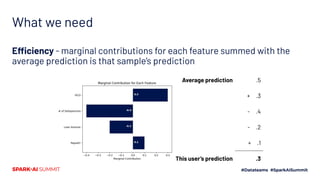



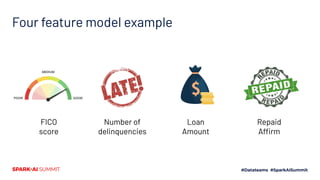
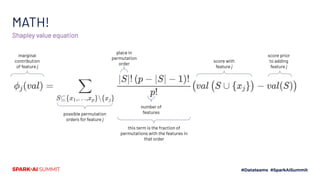











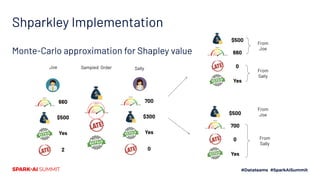
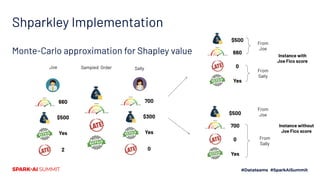
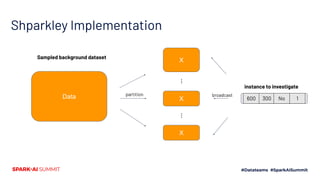
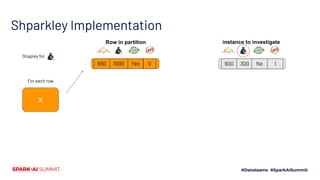
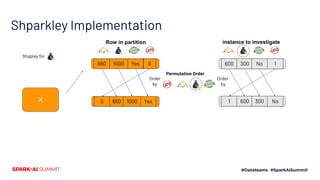
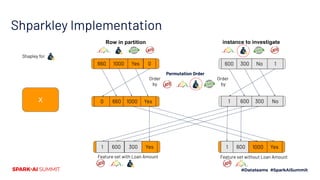
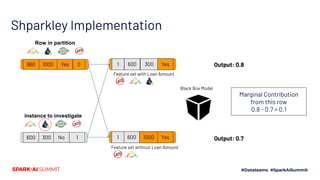
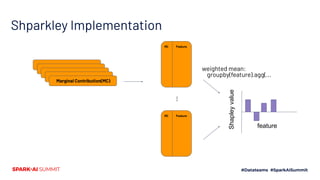

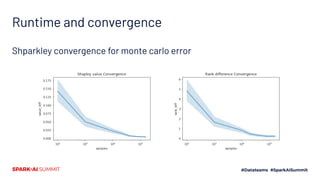
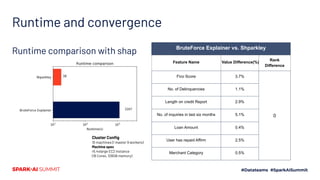




The document discusses the implementation of Shapley values in Apache Spark by Cristine Dewar and Xiang Huang to enhance interpretability and fairness in machine learning models at Affirm. It highlights the need for a scalable and efficient method to allocate marginal contributions of features, employing Monte Carlo approximation for performance enhancement. The Shparkley framework demonstrates significant runtime improvements over brute force explanations while maintaining accuracy in feature contribution values.




























![[Paper reading] L-SHAPLEY AND C-SHAPLEY: EFFICIENT MODEL INTERPRETATION FOR S...](https://cdn.slidesharecdn.com/ss_thumbnails/l-shapley-190705085327-thumbnail.jpg?width=640&height=640&fit=bounds)


















































