Downloaded 53 times





![© 2019 IBM Corporation
Getting started with Kafka Connect
$ ls libs
connect-api-2.1.1.jar
connect-basic-auth-extension-2.1.1.jar
connect-file-2.1.1.jar
connect-json-2.1.1.jar
connect-runtime-2.1.1.jar
connect-transforms-2.1.1.jar
$ ls bin
connect-distributed.sh
connect-standalone.sh
$ bin/connect-standalone.sh config/connect-standalone.properties
connector1.properties [connector2.properties]
$ bin/connect-distributed.sh config/connect-distributed.properties --
bootstrap.servers localhost:9092 --group.id connect](https://image.slidesharecdn.com/katherinestanleyibmlessonslearnedbuildingaconnectorfinalfinal3-190405163107/75/Lessons-Learned-Building-a-Connector-Using-Kafka-Connect-Katherine-Stanley-Andrew-Schofield-IBM-United-Kingdom-Kafka-Summit-NYC-2019-10-2048.jpg)

![© 2019 IBM Corporation
Getting started with Kafka Connect
$ curl http://localhost:8083/connector-plugins
[
{
"class":"org.apache.kafka.connect.file.FileStreamSinkConnector",
"type":"sink",
"version":"2.1.1”
},
{
"class":"org.apache.kafka.connect.file.FileStreamSourceConnector",
"type":"source",
"version":"2.1.1”
}
]](https://image.slidesharecdn.com/katherinestanleyibmlessonslearnedbuildingaconnectorfinalfinal3-190405163107/75/Lessons-Learned-Building-a-Connector-Using-Kafka-Connect-Katherine-Stanley-Andrew-Schofield-IBM-United-Kingdom-Kafka-Summit-NYC-2019-14-2048.jpg)
![© 2019 IBM Corporation
Getting started with Kafka Connect
$ echo ‘{
"name":"kate-file-load",
"config":{"connector.class":"FileStreamSource",
"file":"config/server.properties",
"topic":"kafka-config-topic"}}’ |
curl -X POST -d @- http://localhost:8083/connectors
--header "content-Type:application/json"
$ curl http://localhost:8083/connectors
["kate-file-load"]](https://image.slidesharecdn.com/katherinestanleyibmlessonslearnedbuildingaconnectorfinalfinal3-190405163107/75/Lessons-Learned-Building-a-Connector-Using-Kafka-Connect-Katherine-Stanley-Andrew-Schofield-IBM-United-Kingdom-Kafka-Summit-NYC-2019-15-2048.jpg)







![© 2019 IBM Corporation
Connector config
@Override
public ConfigDef config() {
ConfigDef configDef = new ConfigDef();
configDef.define(”config_option", Type.STRING, Importance.HIGH, ”Config option.") ;
return configDef;
}
$ curl -X PUT -d '{"connector.class":”MyConnector"}’
http://localhost:8083/connector-plugins/MyConnector/config/validate
{“configs”: [{
“definition”: {“name”: “config_option”, “importance”: “HIGH”, “default_value”: null, …},
”value”: {
“errors”: [“Missing required configuration ”config_option” which has no default value.”],
…
}](https://image.slidesharecdn.com/katherinestanleyibmlessonslearnedbuildingaconnectorfinalfinal3-190405163107/75/Lessons-Learned-Building-a-Connector-Using-Kafka-Connect-Katherine-Stanley-Andrew-Schofield-IBM-United-Kingdom-Kafka-Summit-NYC-2019-28-2048.jpg)



![© 2019 IBM Corporation
MQ sink connector
Converter MessageBuilder
TO.MQ.TOPIC
SinkRecord
Value
(may be complex)
Schema
Kafka Record
Value
byte[]
Key
MQ Message
Payload
MQMD
(MQRFH2)
MQ SINK
CONNECTOR
FROM.KAFKA.Q](https://image.slidesharecdn.com/katherinestanleyibmlessonslearnedbuildingaconnectorfinalfinal3-190405163107/75/Lessons-Learned-Building-a-Connector-Using-Kafka-Connect-Katherine-Stanley-Andrew-Schofield-IBM-United-Kingdom-Kafka-Summit-NYC-2019-37-2048.jpg)


![© 2019 IBM Corporation
MQ source connector
RecordBuilder Converter
TO.MQ.TOPIC
Source Record
Value
(may be complex)
Schema
MQ Message Kafka Record
Null Record
MQ SOURCE
CONNECTOR
TO.KAFKA.Q
Value
byte[]
Payload
MQMD
(MQRFH2)](https://image.slidesharecdn.com/katherinestanleyibmlessonslearnedbuildingaconnectorfinalfinal3-190405163107/75/Lessons-Learned-Building-a-Connector-Using-Kafka-Connect-Katherine-Stanley-Andrew-Schofield-IBM-United-Kingdom-Kafka-Summit-NYC-2019-40-2048.jpg)



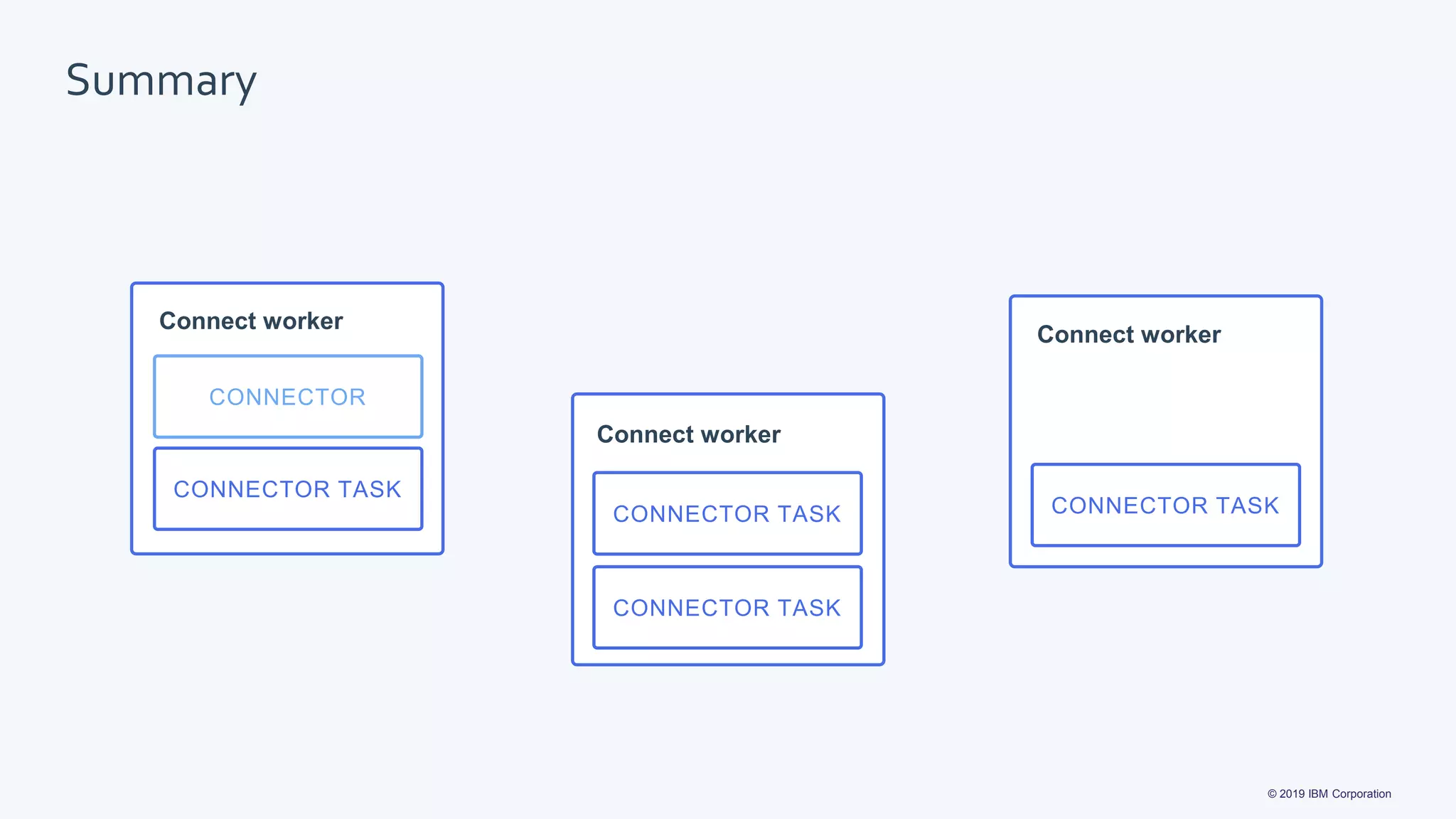





The document discusses the implementation of Kafka Connect for integrating IBM MQ with Apache Kafka, outlining the process for creating and managing connectors. It details key considerations for connector design, including data formats and lifecycle management, while also covering specific connector functionalities for both source and sink connections. Additionally, it highlights the availability and support for IBM's connectors, including their deployment on various systems.























































































