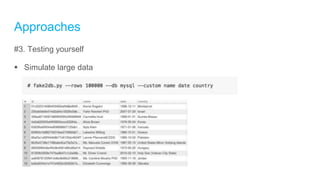
Downloaded 105 times


















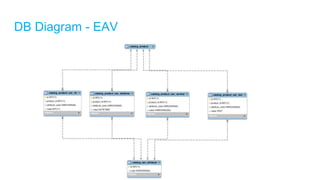
![Scaling Principles
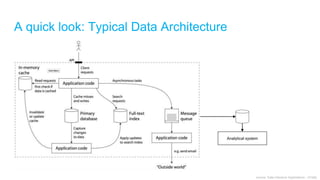
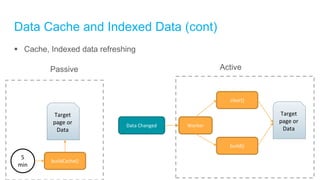
[Important] Speeding-up with Caching/Indexed Data
o High read performance
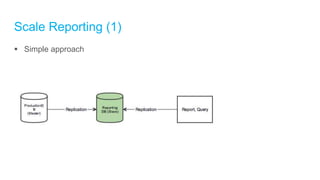
[Important] Separating Operational DB vs Reporting DB
o Different complexity
Other:
o Separating Read/Write: Different I/O
o Speeding-up with Pre-calculated Data: E.g: Statistics data
o Avoiding monolithics (everything in one DB): Hard to scale](https://image.slidesharecdn.com/topdev-highperformanceandscalabilitydatabasedesign-v2-170824012822/85/High-Performance-and-Scalability-Database-Design-24-320.jpg)


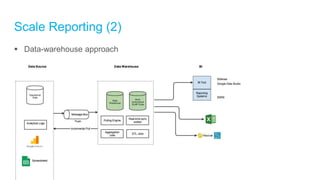










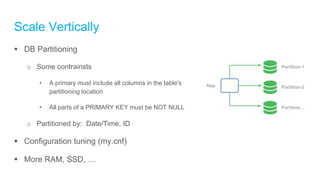

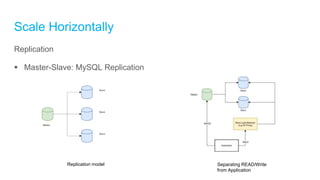
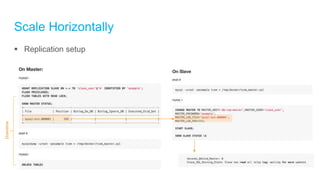
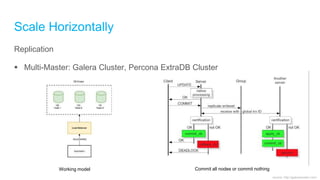


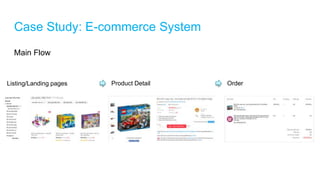
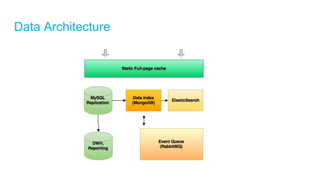
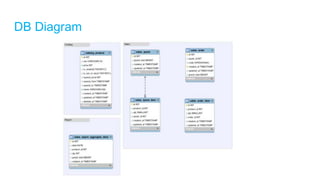



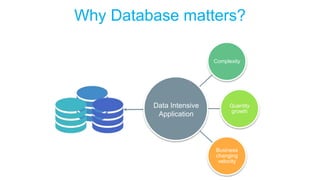
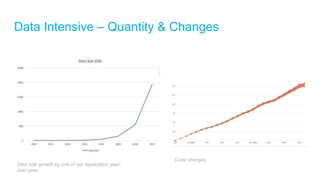
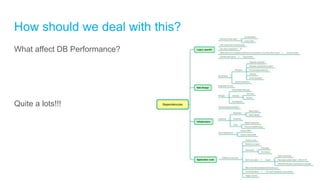
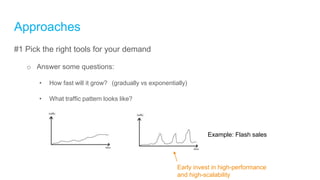
The document discusses high-performance and scalable database design principles presented by Nguyễn Sơn Tùng at a TopDev event. It covers various approaches to database performance and scaling, including choosing the right tools, the importance of precise data management, and methodologies for testing and improvement. Additionally, it presents a case study involving e-commerce systems to illustrate these concepts in practice.



































































