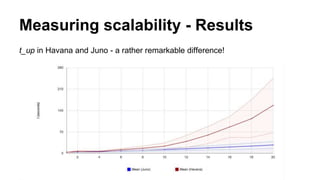
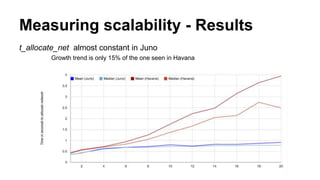
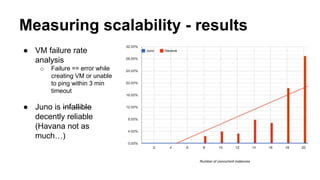
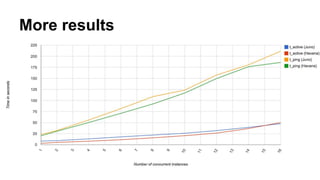
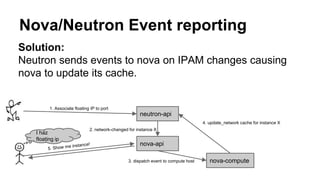
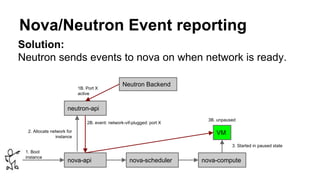
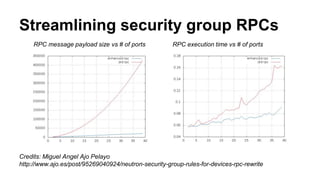
The document discusses improvements in scalability and reliability of OpenStack's Neutron service from the Havana to Juno releases, highlighting 1,672 commits made over 12 months. Key enhancements include better handling of instance creation, reduced failure rates, and more efficient processing of network interfaces and security groups. Despite notable progress, including a zero failure rate in Juno, challenges remain in tracking asynchronous operations and optimizing overall scalability.

























































![[OSS Upstream Training] 5 open stack liberty_recap](https://cdn.slidesharecdn.com/ss_thumbnails/5openstacklibertyrecap-151227095312-thumbnail.jpg?width=640&height=640&fit=bounds)


![[OpenStack Day in Korea 2015] Track 3-6 - Archiectural Overview of the Open S...](https://cdn.slidesharecdn.com/ss_thumbnails/36-150213070342-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)

























