Downloaded 73 times







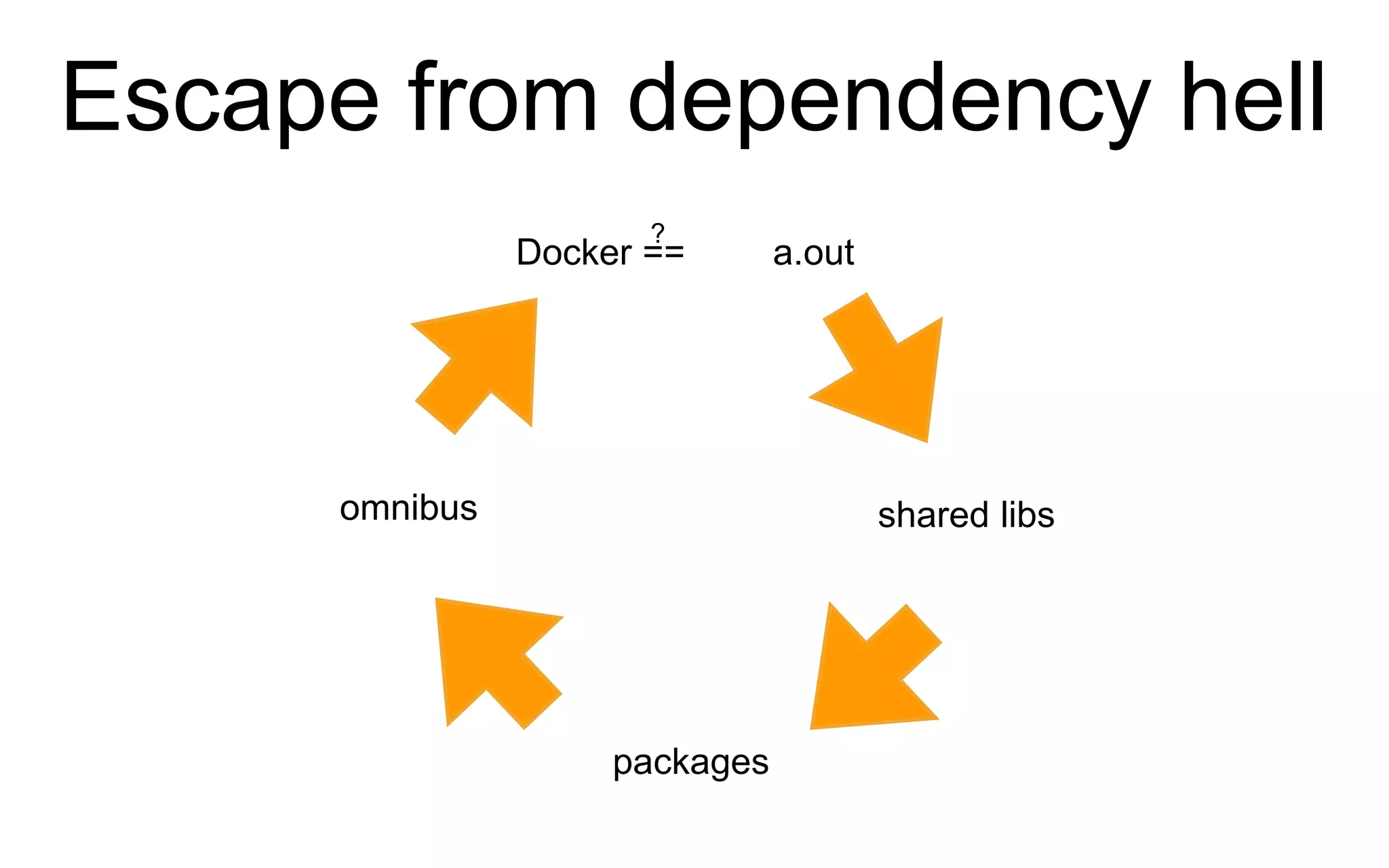
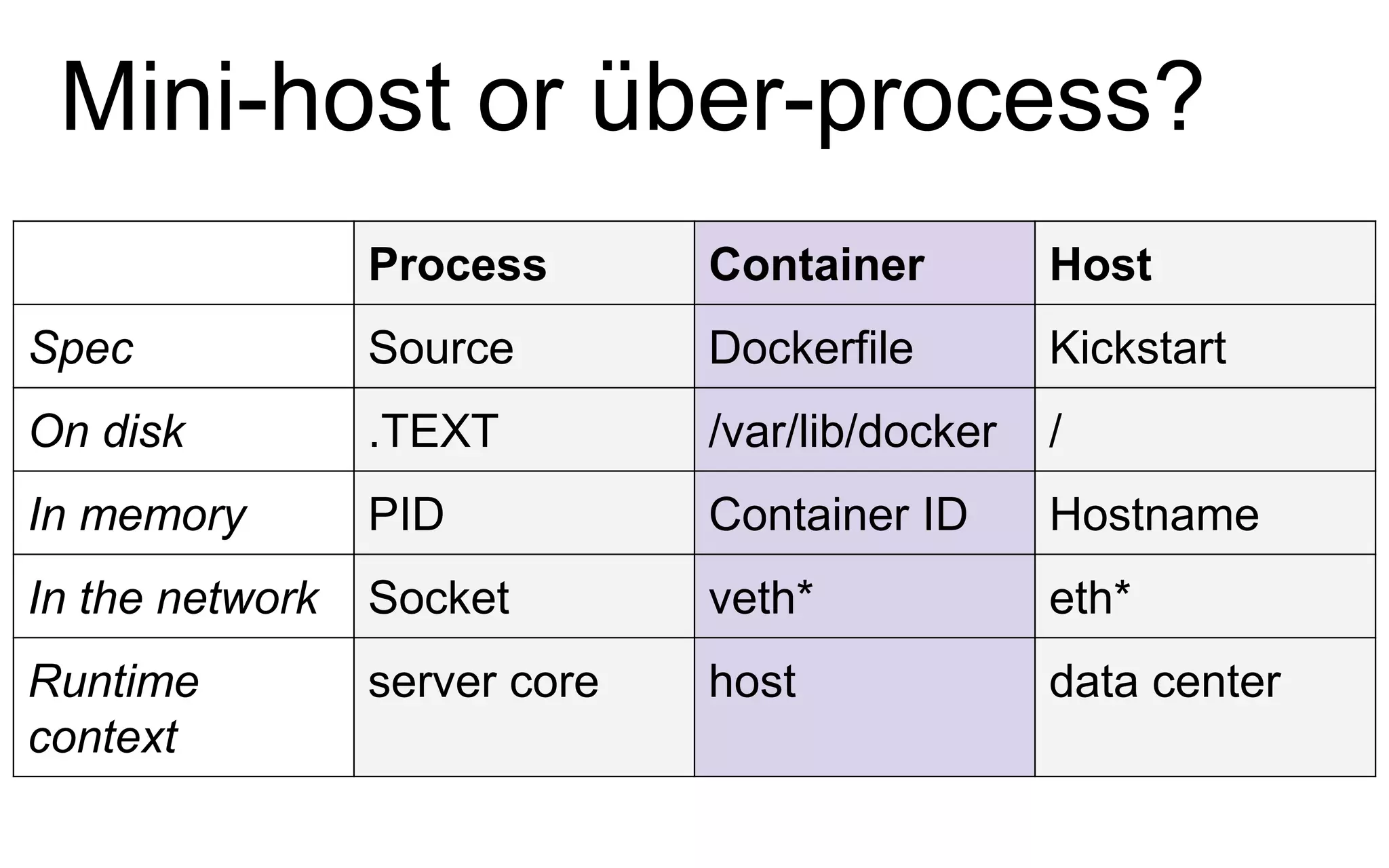


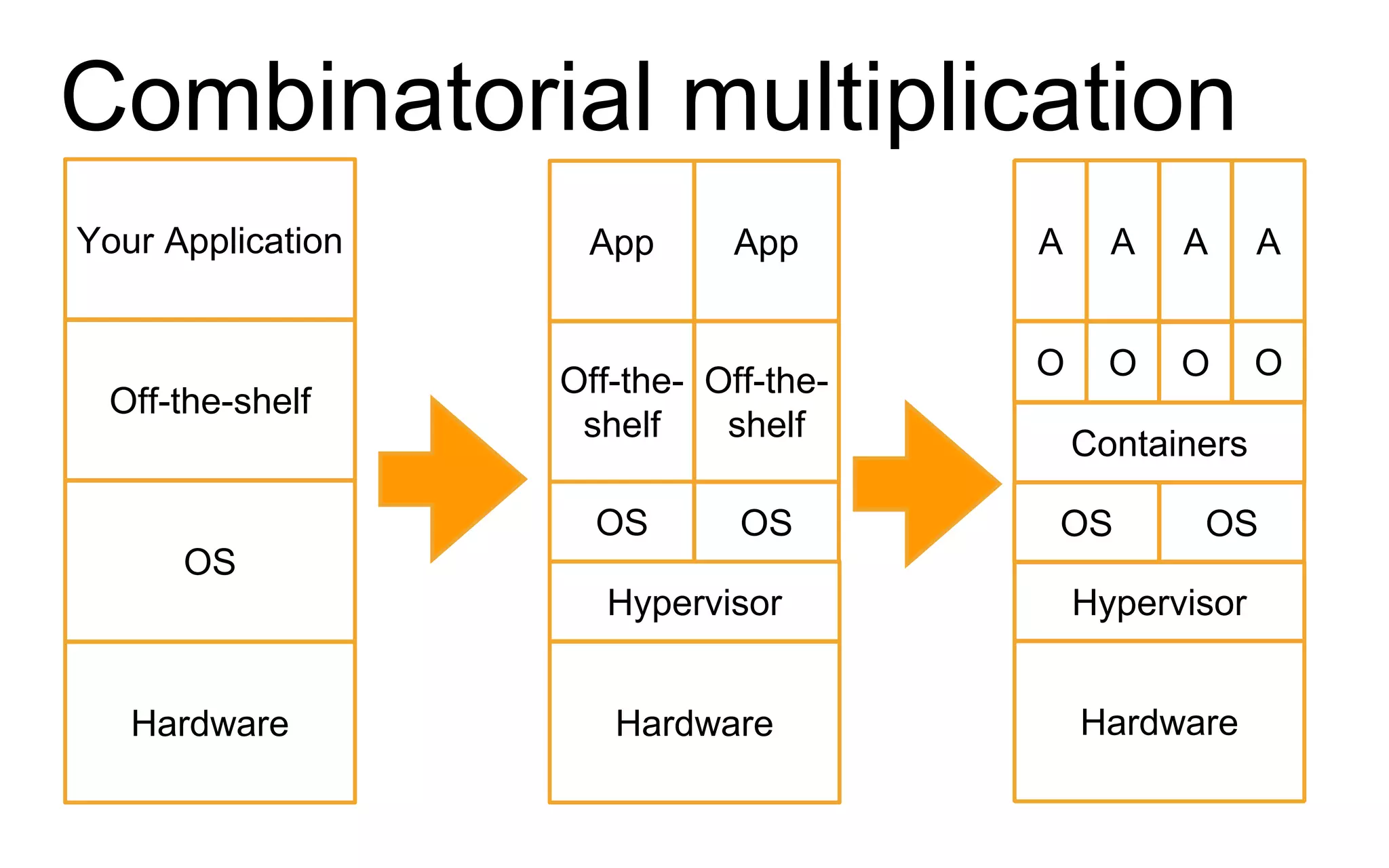





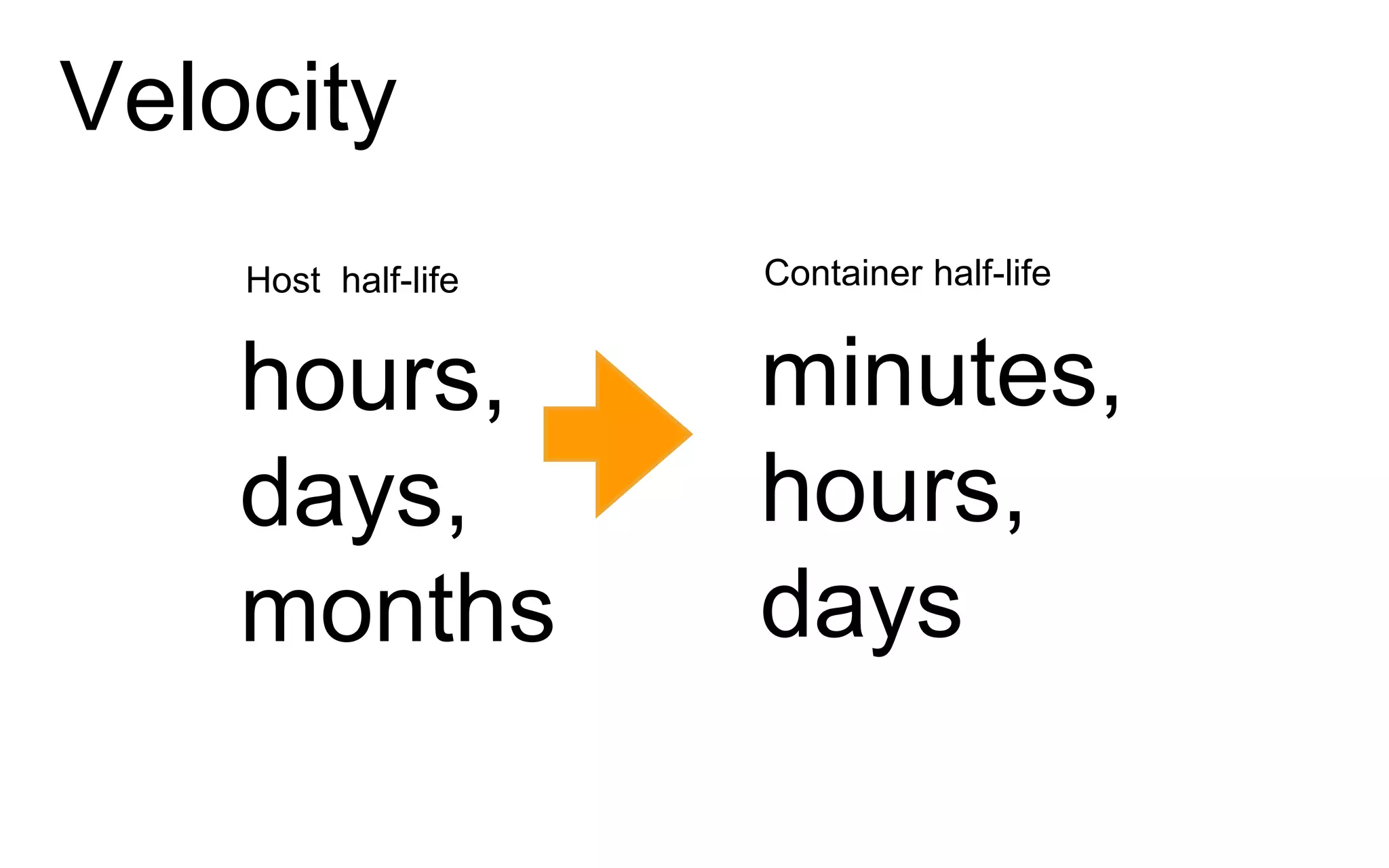


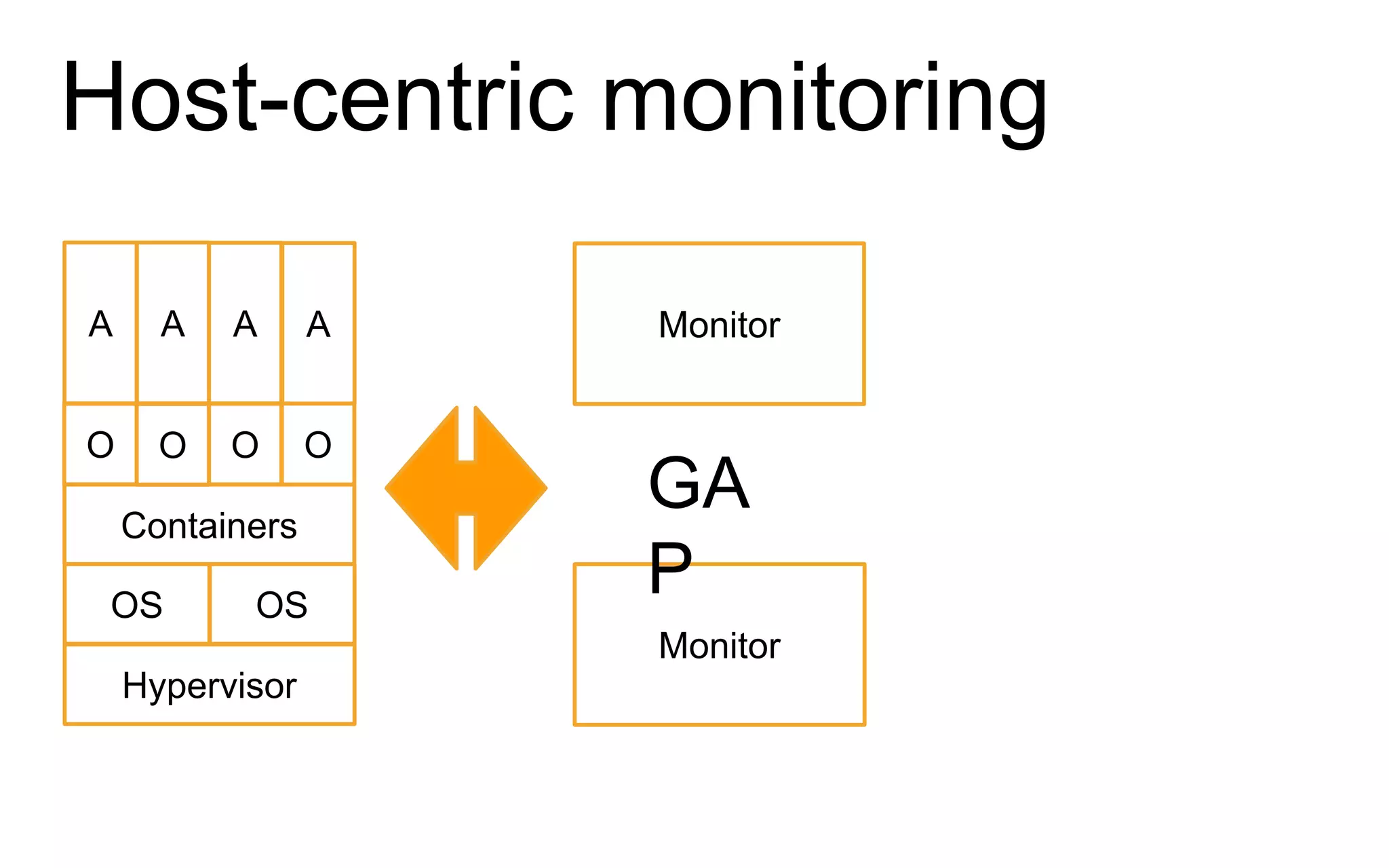




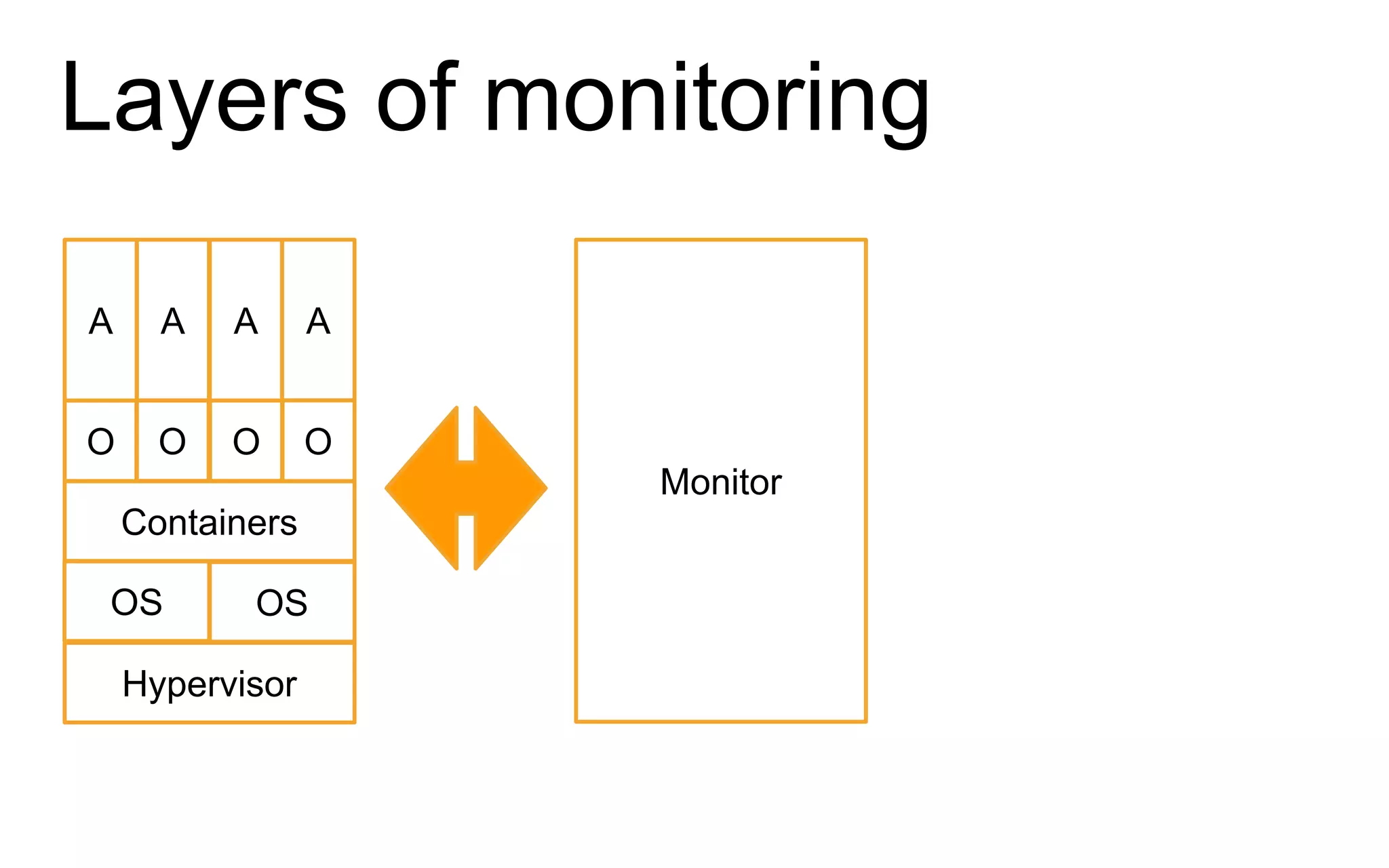
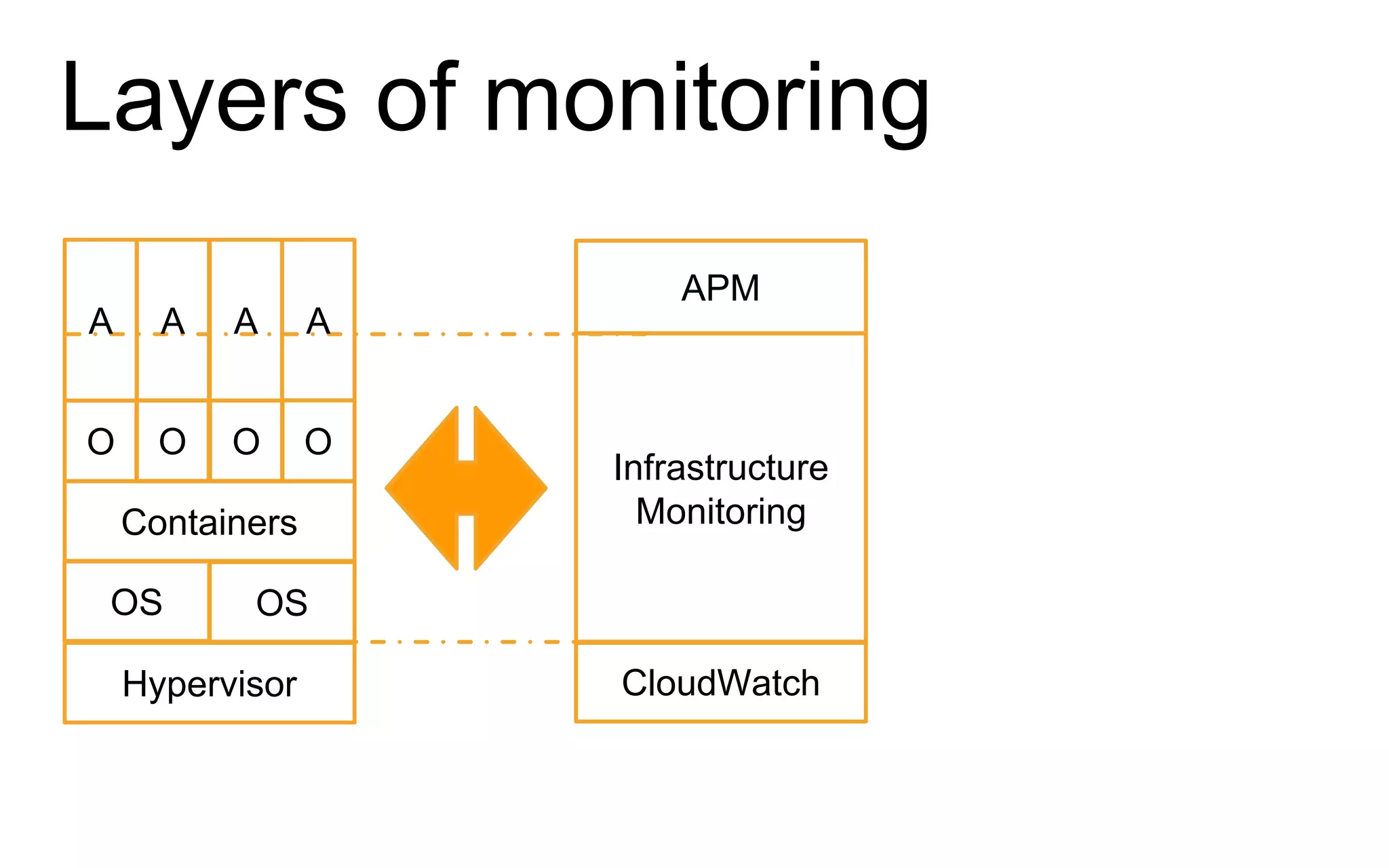
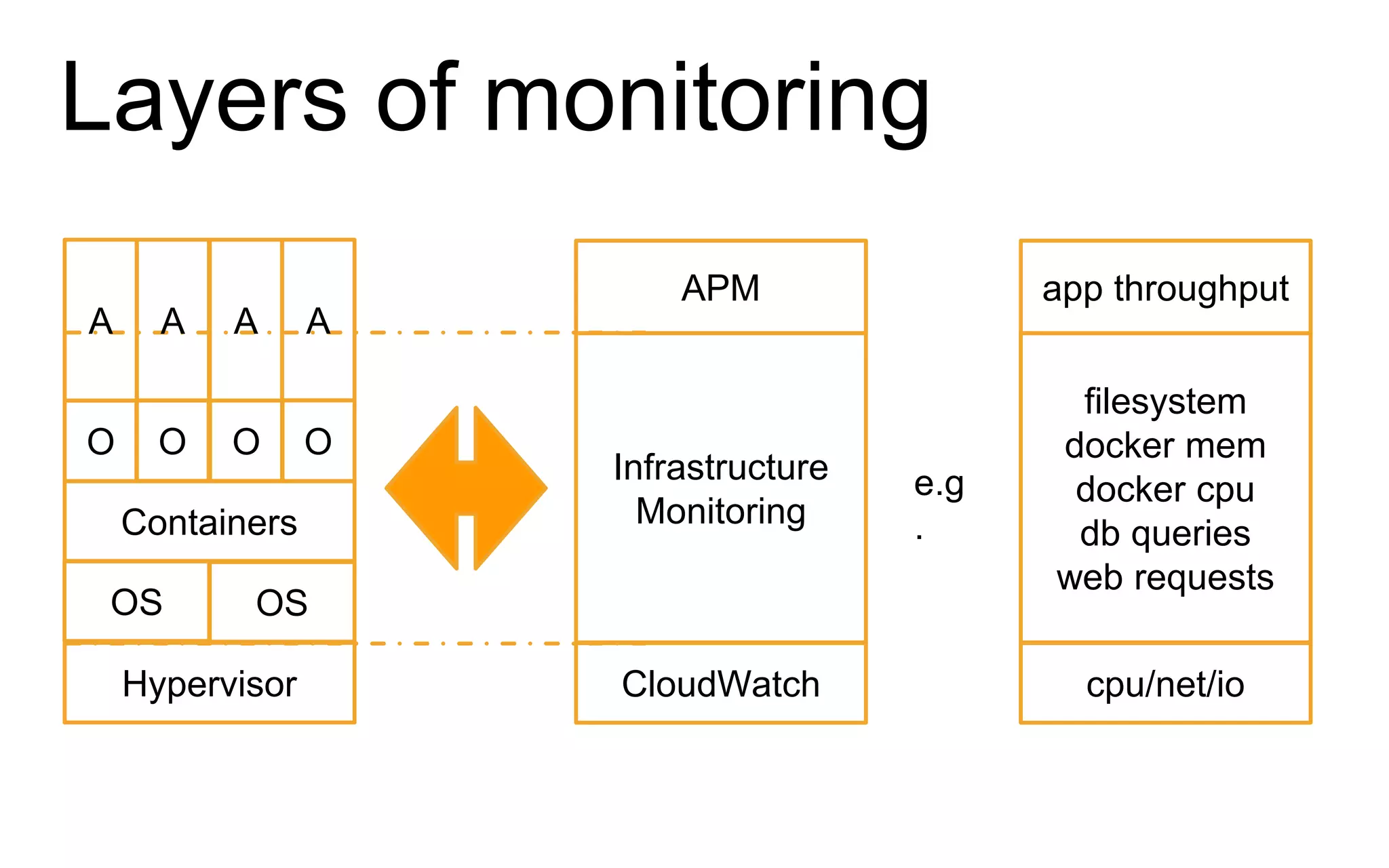










The document discusses the complexities of monitoring Docker containers at scale, highlighting the evolution of containers, their operational challenges, and the necessity for effective monitoring strategies. It emphasizes the importance of layered monitoring and using tags and queries for efficient oversight of container metrics. Key takeaways include the increased operational complexity introduced by Docker and the need for a structured approach to manage it effectively.