Download to read offline
![Container Management Platform
[K8S]
PaaS Journey
By Uladzimir Palkhouski
https://www.linkedin.com/in/uladzimirpalkhouski/](https://image.slidesharecdn.com/containermanagementplatform-paasjourney1-181024193223/75/Kubernetes-Container-Management-PaaS-Journey-1-2048.jpg)





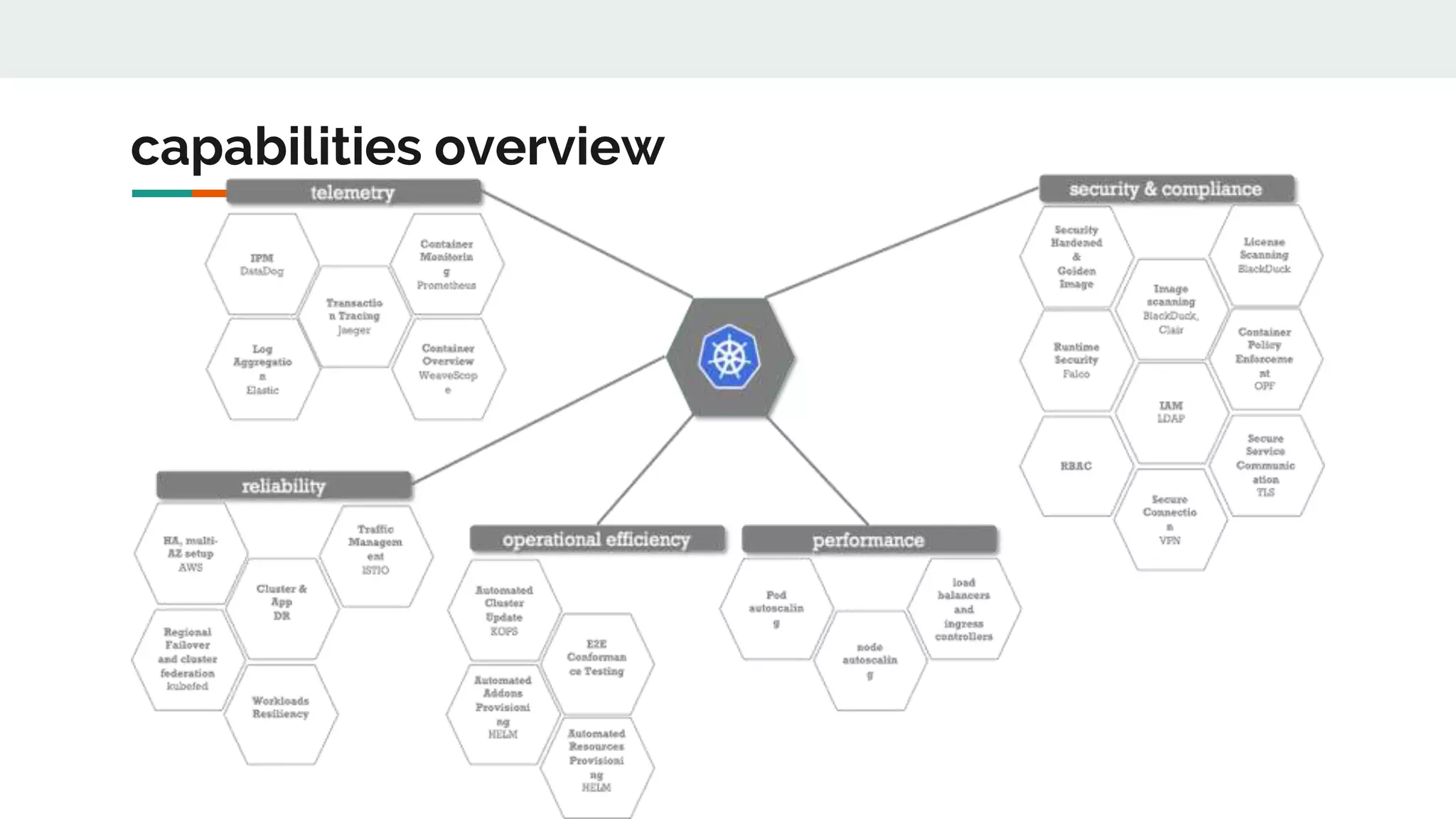



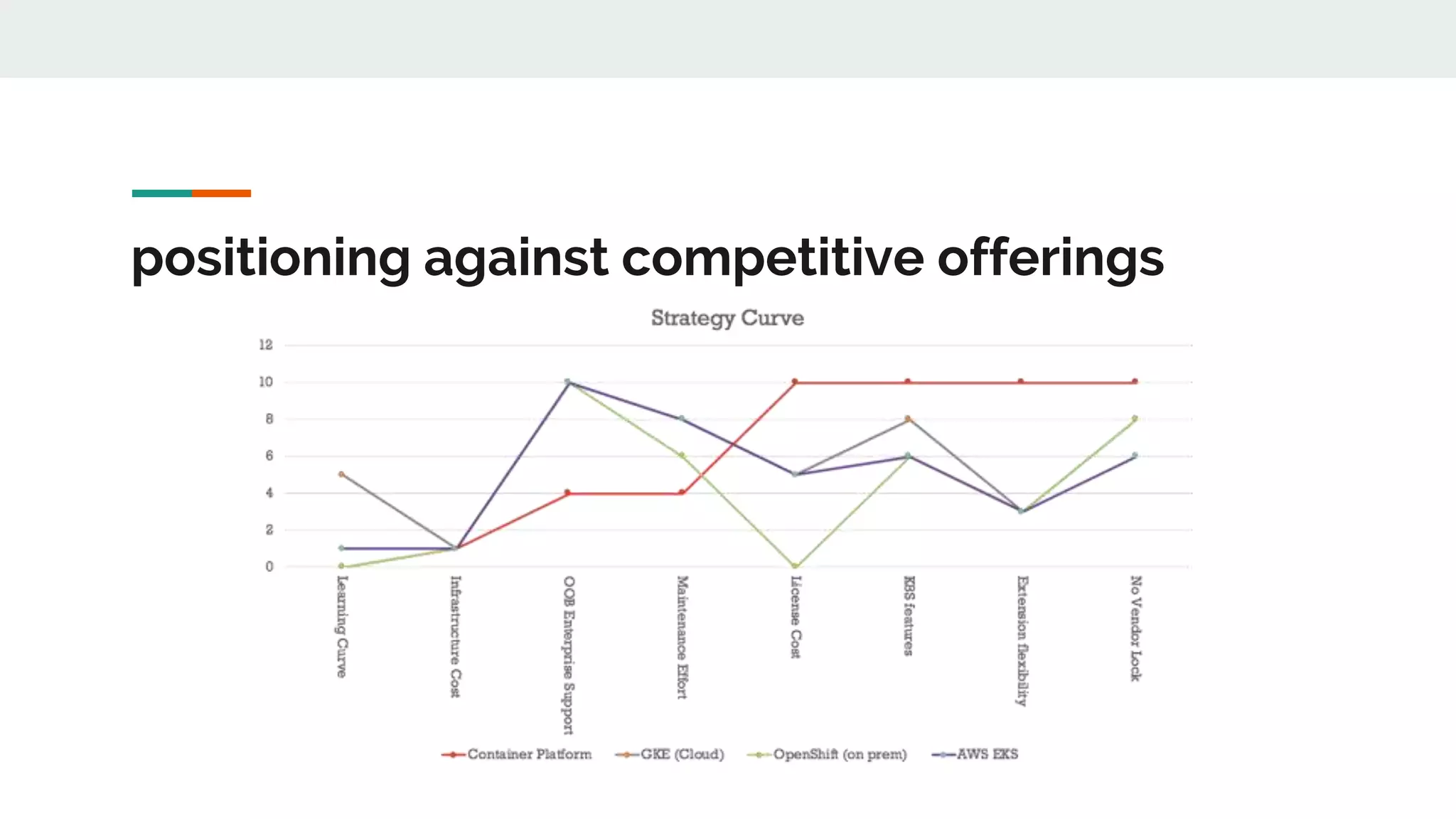
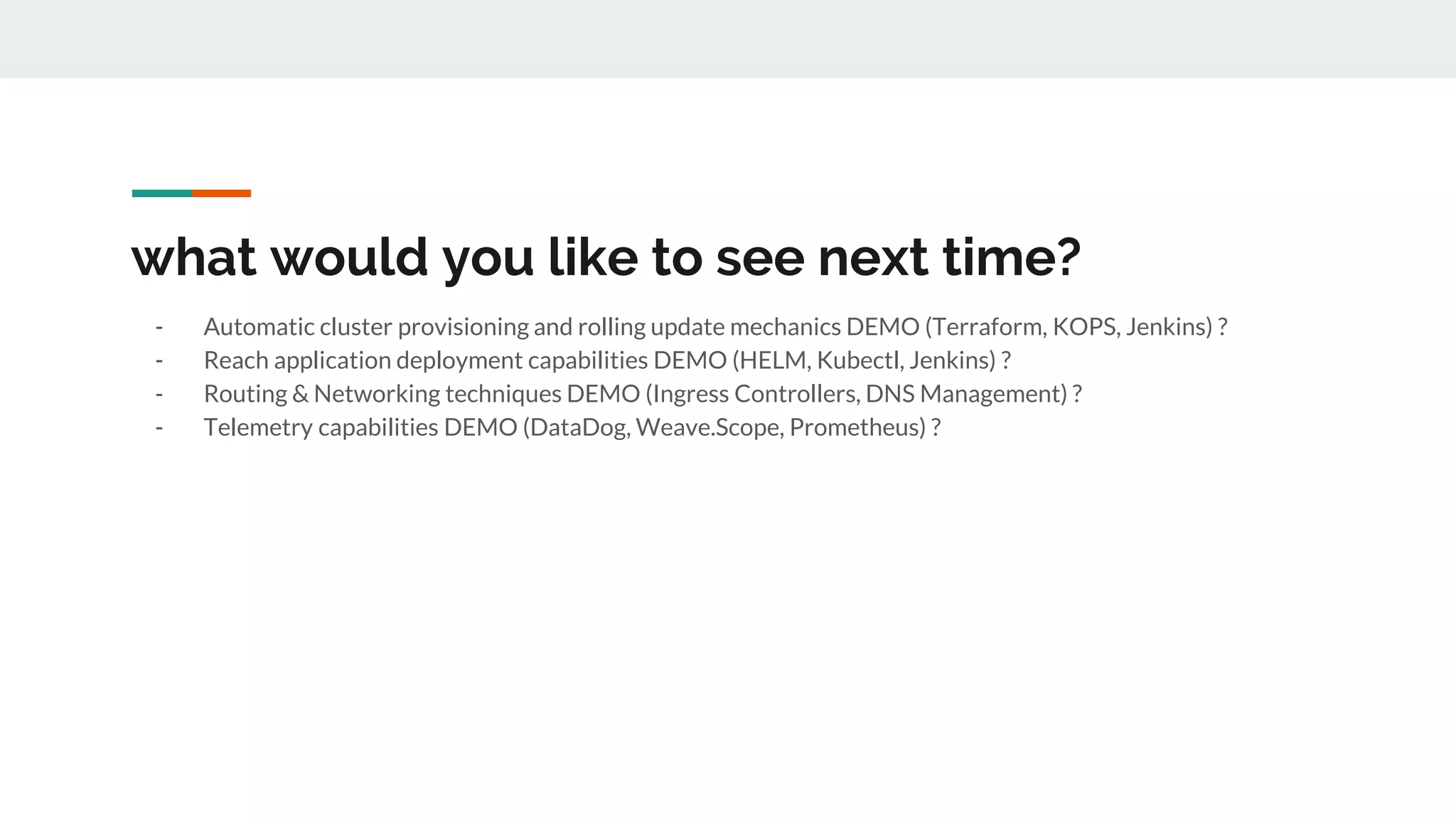

This document discusses the challenges of managing applications across different infrastructure layers without a unified platform. It introduces Kubernetes as a container management platform that can address these challenges by providing a unified way to deploy and manage applications and infrastructure. Key benefits include increased deployment speed and reliability, improved security, and allowing developers to focus on code while operations handles infrastructure concerns like resiliency and compliance. The document outlines the journey of adopting Kubernetes and lessons learned, and positions it against competitive offerings.



































































