4
• 배경 및문제점
§ Image-to-image translation 과정에서 conv process(conv → normalize → activation)가
흔히 사용되는데
§ 이때 normalization layer는 입력 이미지의 정보를 “유실”시킴
Ø Normalization layer tend to “wash away” information in input image
• 목표 및 기여점
§ Semantic(segmentation, mask) image → photorealistic image
§ 입력 이미지의 정보를 “유실”되게 하지 않는 새로운 normalize 방법 제안
Introduction
5.
5
• Deep GenerativeModel
• Conditional Image Synthesis
• Unconditional Normalization Layers
• Conditional Normalization Layers
Related Work
6.
6
• GAN의 구조를갖음
§ Generator, Discriminator
Related Work - Deep Generative Model
7.
7
• 특정 조건을제시하고 이를 만족하는 이미지를 만들어 내는 것
§ Given category labels
§ Given text
§ Given image
Ø Image-to-image translation
Ø Semantic mask image -> photo realistic image
Related Work – Conditional Image Synthesis
8.
8
• 외부 데이터에의존하지 않고 단순히 propagated layer 내부에서
normalize를 진행
§ Batch Norm
§ Weight Norm
§ Layer Norm
§ Instance Norm
§ Group Norm
§ etc.
Related Work – Unconditional Normalization Layers
사진 출처 : http://mlexplained.com/2018/11/30/an-overview-of-normalization-methods-in-deep-learning/
9.
9
• 외부 데이터에의존적임
§ Image synthesis 과정에서 주로 사용
§ Conditional Batch Norm
§ Adaptive Instance Norm(AdaIN)
• 방법
1. Normalize(0 mean, 1 sd) using internal dataset
2. De-normalize using external dataset’s mean and sd
Ø Affine transformation with parameters inferred from external data
Related Work – Conditional Normalization Layers
A
B
…
…
…
…
Normalize using data A
De-normalize using data B
10.
10
• Conditional(Mask) Image에서평균, 분산 (scalar)값을 구하는게 아니라
tensor의 형태로 element-wise affine transformation 연산을 진행
• 의의
§ 𝛾와 β의 각 x, y 위치는 input mask의 특정 공간에 해당하는 의미 있는 정보를 담고 있음
§ Why does SPADE work better ? “Better preserve semantic information”
• 다른 Conditional Normalization Layer의 일반적인 형태
§ Conditional Batch Norm
Ø Mask image 대신 class label
Ø 𝛾 tensor의 값이 모두 같고 β tensor의 값이 모두 같음 (spatially-invariant)
§ AdaIN
Ø Mask image 대신 class label
Ø 𝛾 tensor의 값이 모두 같고 β tensor의 값이 모두 같음 (spatially-invariant)
Ø Put mini batch size = 1
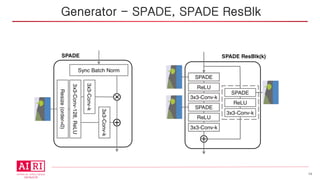
SPatially-Adaptive DEnormalization(SPADE)
11.
11
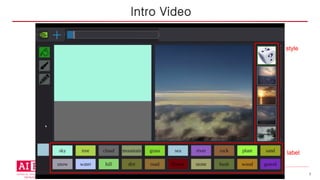
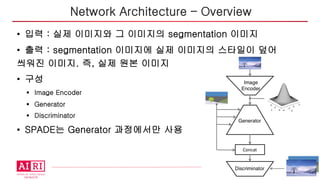
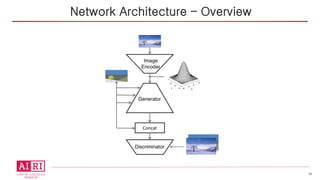
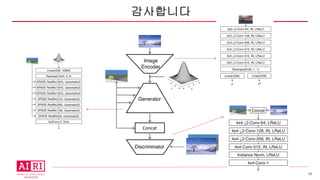
• 입력 :실제 이미지와 그 이미지의 segmentation 이미지
• 출력 : segmentation 이미지에 실제 이미지의 스타일이 덮어
씌워진 이미지. 즉, 실제 원본 이미지
• 구성
§ Image Encoder
§ Generator
§ Discriminator
• SPADE는 Generator 과정에서만 사용
Network Architecture – Overview
12.
12
• 실제 이미지를encoding하는 과정
• 입력 : 실제 이미지
• 출력 : 256차원 vector 2개(평균, 분산)
§ 이 값은 reparameterization trick으로 sampling 과정에 사용
• 출력값이 정규 분포를 따르도록 학습 진행
§ KL Divergence Loss 사용
§ Multi-Modal synthesis 가능
• 최종적으로 정상적으로 학습이 됐다면 출력값은
입력 이미지의 스타일 분포를 의미함
Network Architecture - Image Encoder
13.
13
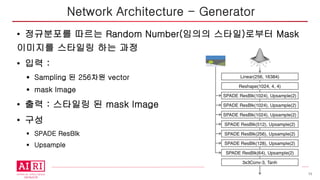
• 정규분포를 따르는Random Number(임의의 스타일)로부터 Mask
이미지를 스타일링 하는 과정
• 입력 :
§ Sampling 된 256차원 vector
§ mask Image
• 출력 : 스타일링 된 mask Image
• 구성
§ SPADE ResBlk
§ Upsample
Network Architecture - Generator
21
• Segmentation Accuracy
§잘 생성된 이미지의 segmentation map은 원래 segmentation map과 비슷!
§ mIoU(mean Intersection over Union)
§ Pixel accuracy
• Frechet Inception Distance(FID)
§ 생선된 이미지의 분포와 실제 이미지 분포 사이의 거리
Performance Metrics
22.
22
• Baselines
§ pix2pixHDModel
§ Cascaded Refinement Network(CRN)
§ Semi-parametric IMage Synthesis model (SIMS)
Experiments – Comparison SPADE with other baselines
SIMS
23.
23
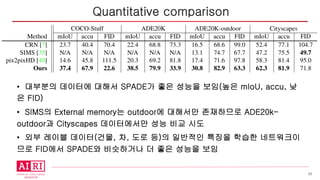
• 대부분의 데이터에대해서 SPADE가 좋은 성능을 보임(높은 mIoU, accu, 낮
은 FID)
• SIMS의 External memory는 outdoor에 대해서만 존재하므로 ADE20k-
outdoor과 Cityscapes 데이터에서만 성능 비교 시도
• 외부 레이블 데이터(건물, 차, 도로 등)의 일반적인 특징을 학습한 네트워크이
므로 FID에서 SPADE와 비슷하거나 더 좋은 성능을 보임
Quantitative comparison
24.
24
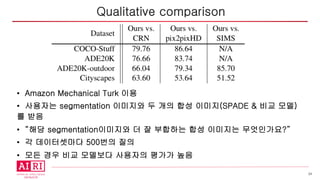
• Amazon MechanicalTurk 이용
• 사용자는 segmentation 이미지와 두 개의 합성 이미지(SPADE & 비교 모델)
를 받음
• “해당 segmentation이미지와 더 잘 부합하는 합성 이미지는 무엇인가요?”
• 각 데이터셋마다 500번의 질의
• 모든 경우 비교 모델보다 사용자의 평가가 높음
Qualitative comparison
25.
25
①
②
• 모델에서 SPADE의유무에 따른 성능 비교
• pix2pixHD++ : baseline 이었던 pix2pix모델을 강화
• ① : decoder(generator) part
§ Concatenate보다 SPADE가 더 semantic의미를 잘 전달
§ Compact 모델이 concat 뿐 아니라 ②의 다른 모델들보다 대부분 좋은 성능을 보임
• ② : pix2pixHD 모델에 적용
§ SPADE를 쓴 모델이 기존 모델의 성능을 더 끌어올림
Effectiveness of SPADE
26.
26
• 잘 학습된Image Encoder의 결과는 정규 분포를 따르므로
정규 분포를 따르는 임의의 data point를 입력으로 넣어주면
segmentation map에 다양한 스타일을 입힐 수 있음
Multi-modal Synthesis
27.
27
• Image-to-image translation과정 중 Normalization layer를 통과하면서 발생
하는 input image information 유실 문제를 해결하고자 새로운 Normalize 방법
(SPADE)을 제시
• 이는 Semantic synthesis task에서 기존 모델보다 좋은 성능을 양적/질적 실
험을 통해 보여줌
Conclusion

























































![[부스트캠프 Tech Talk] 배지연_Structure of Model and Task](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkbaejiyeon-211210113740-thumbnail.jpg?width=640&height=640&fit=bounds)








