Downloaded 17 times





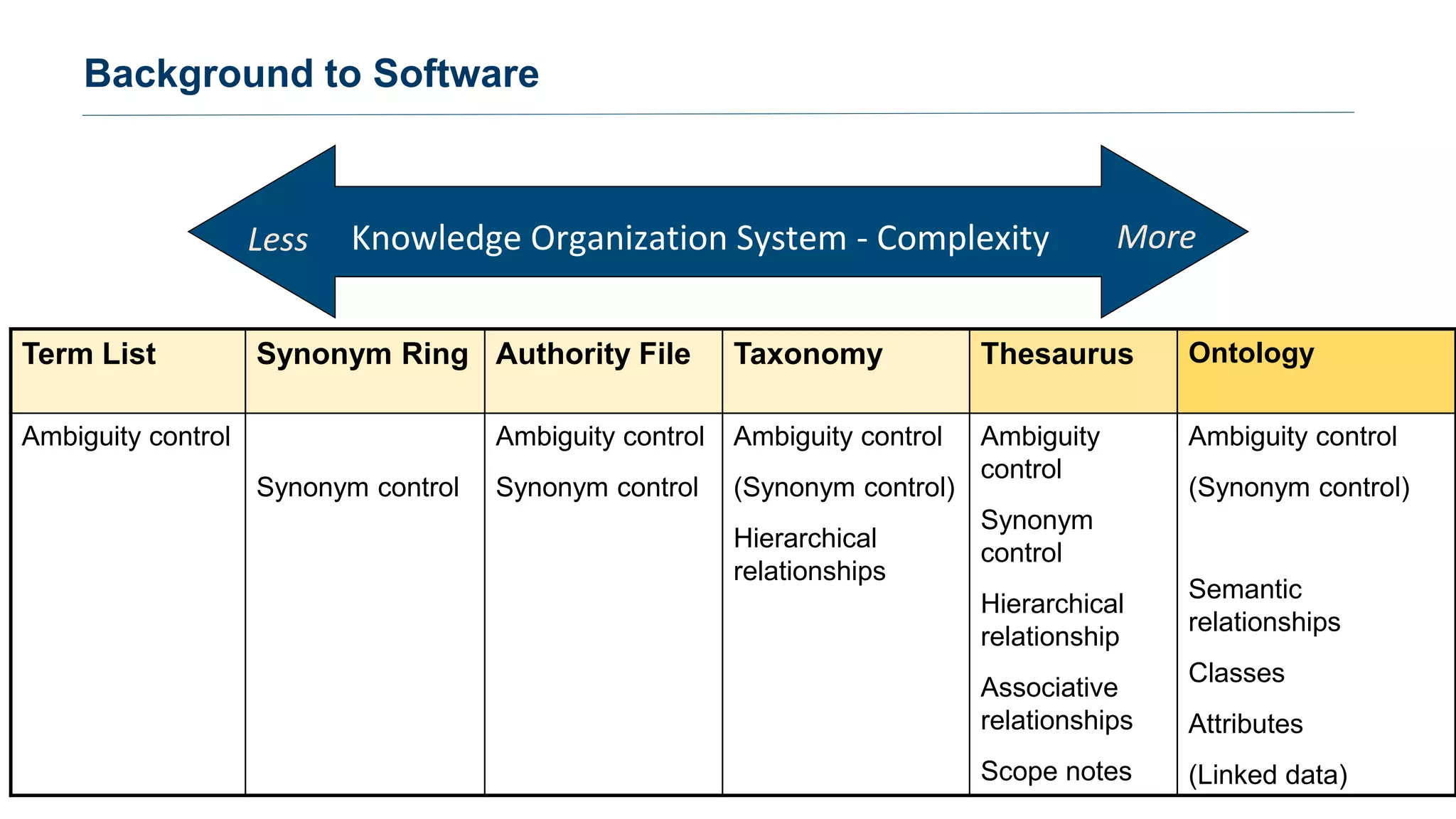





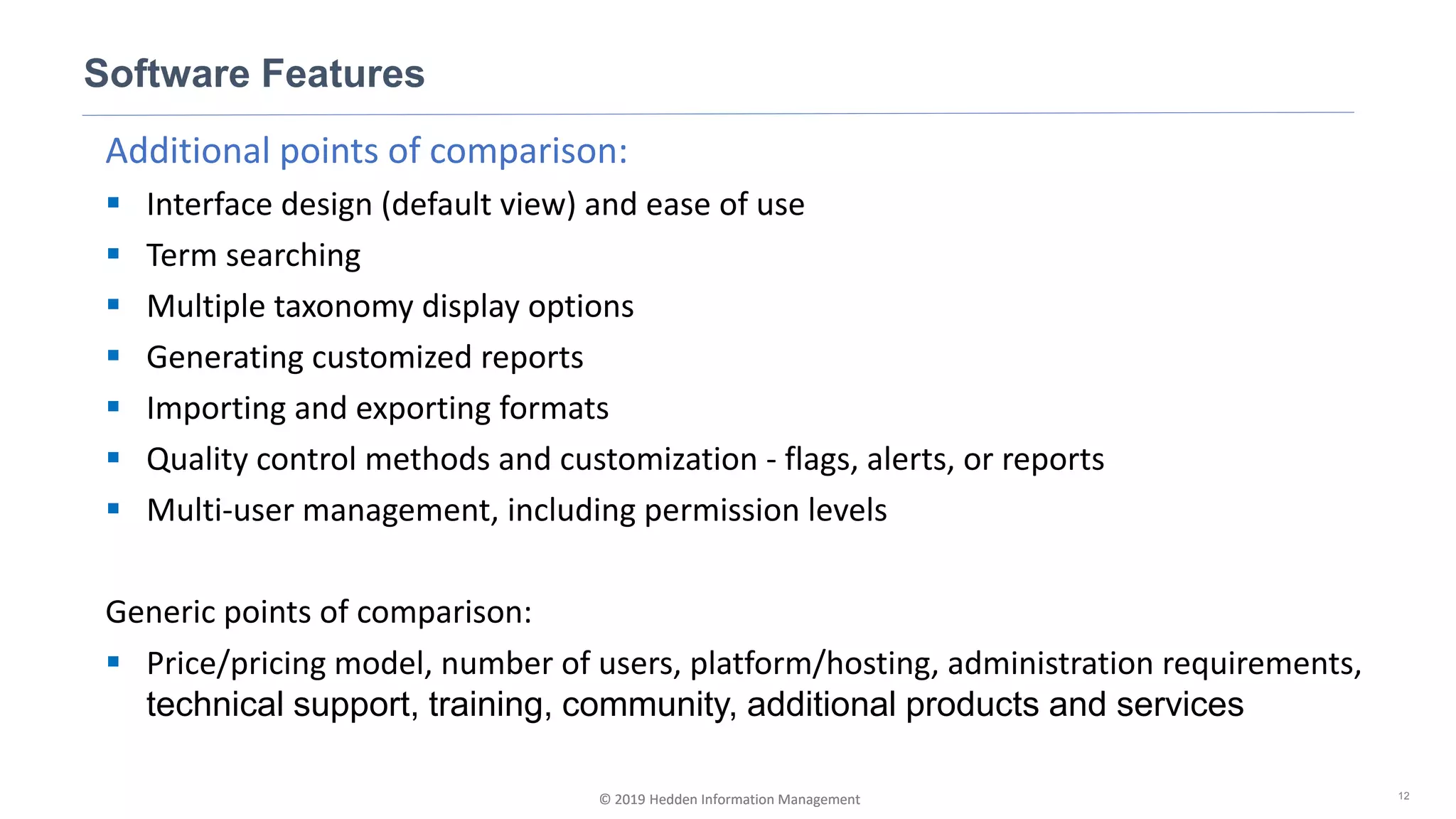



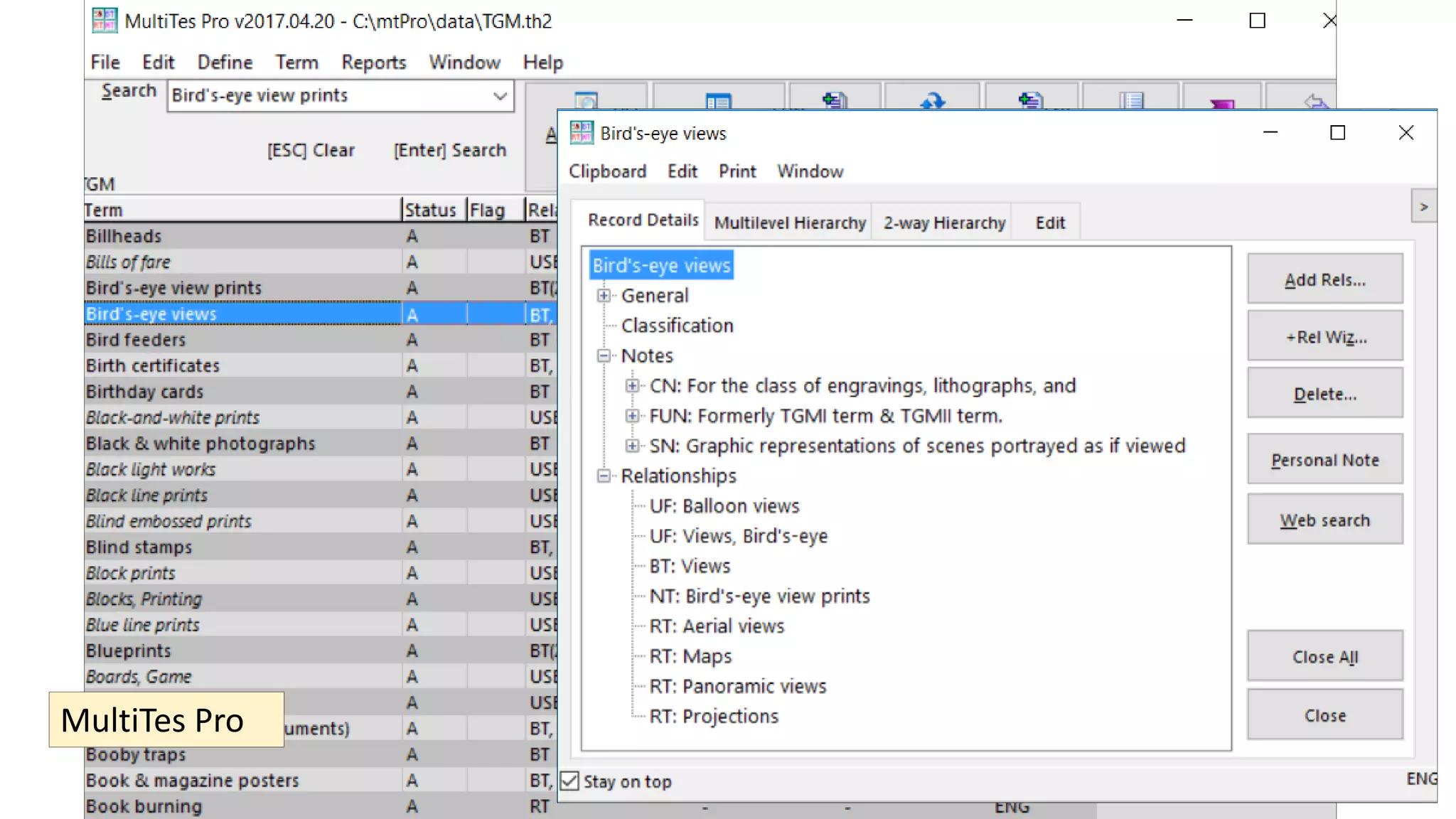

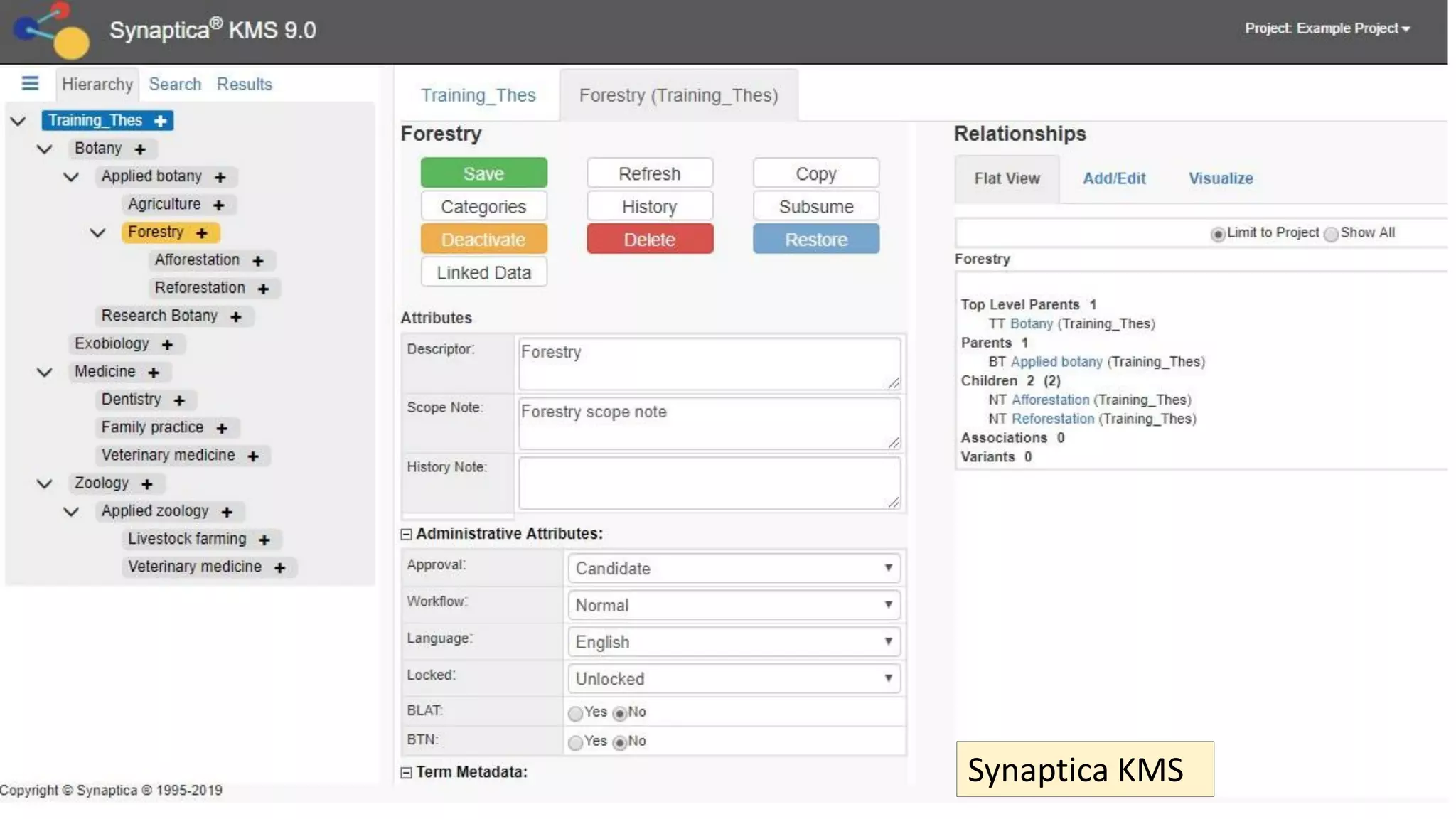
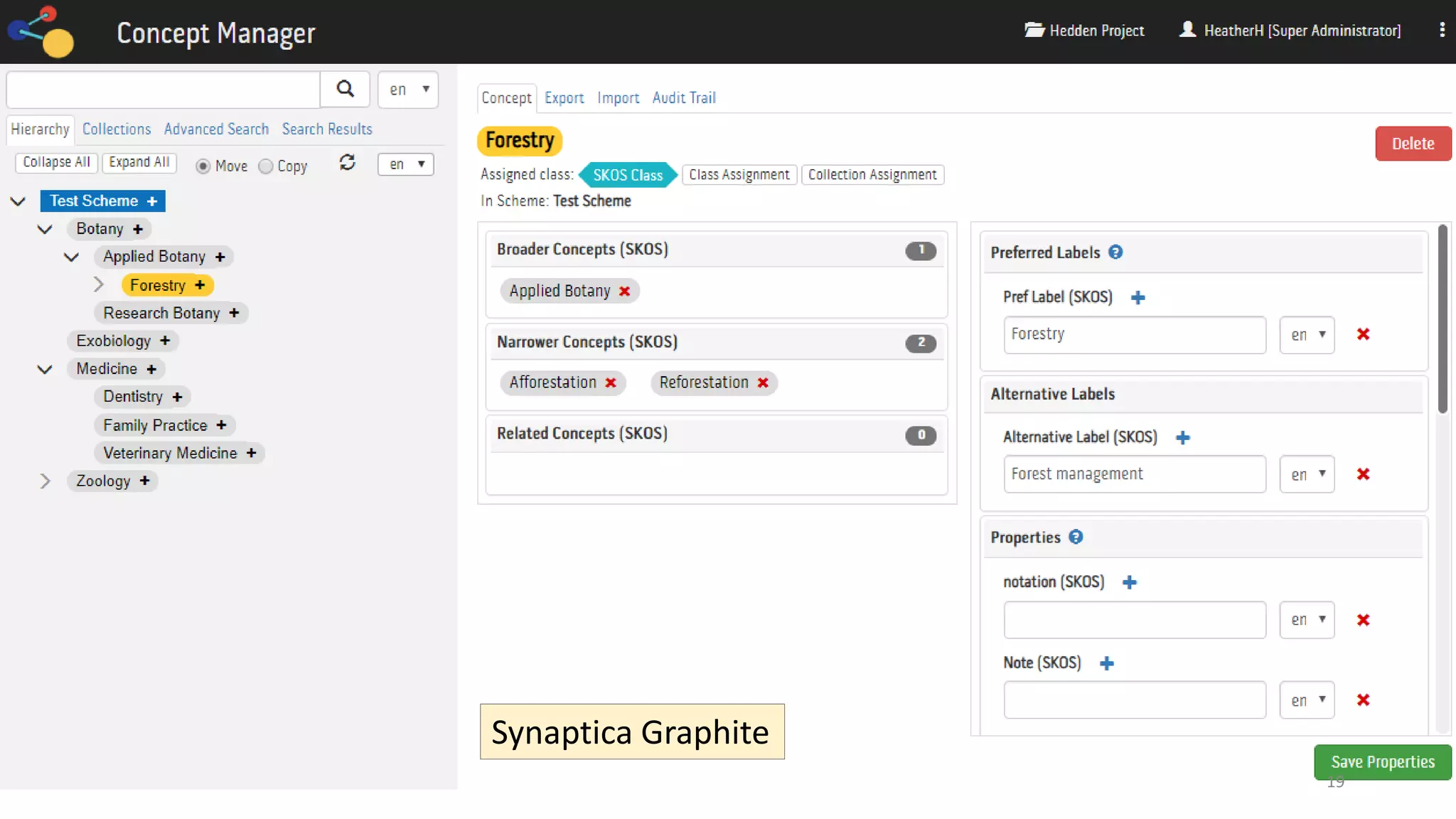

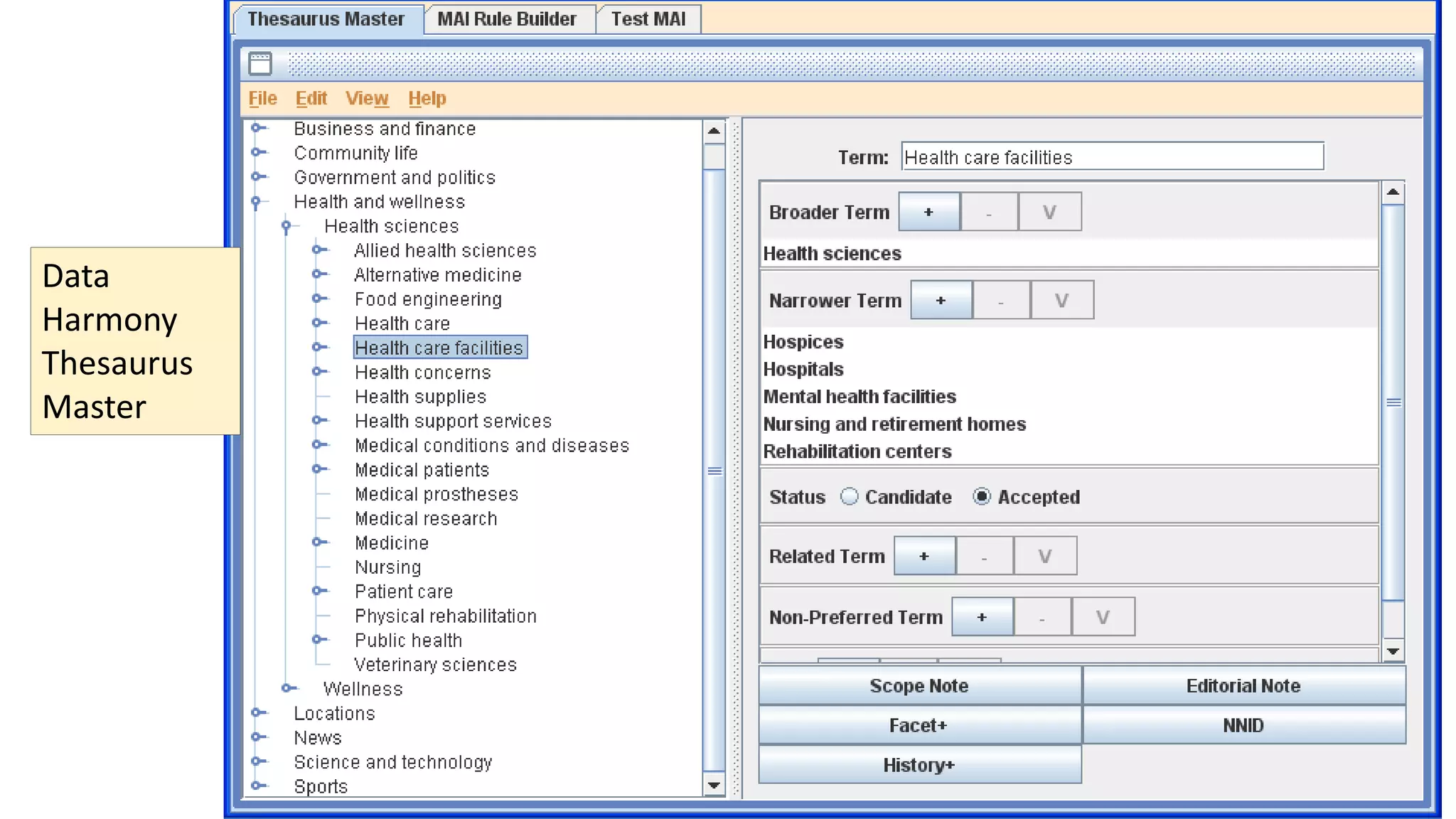

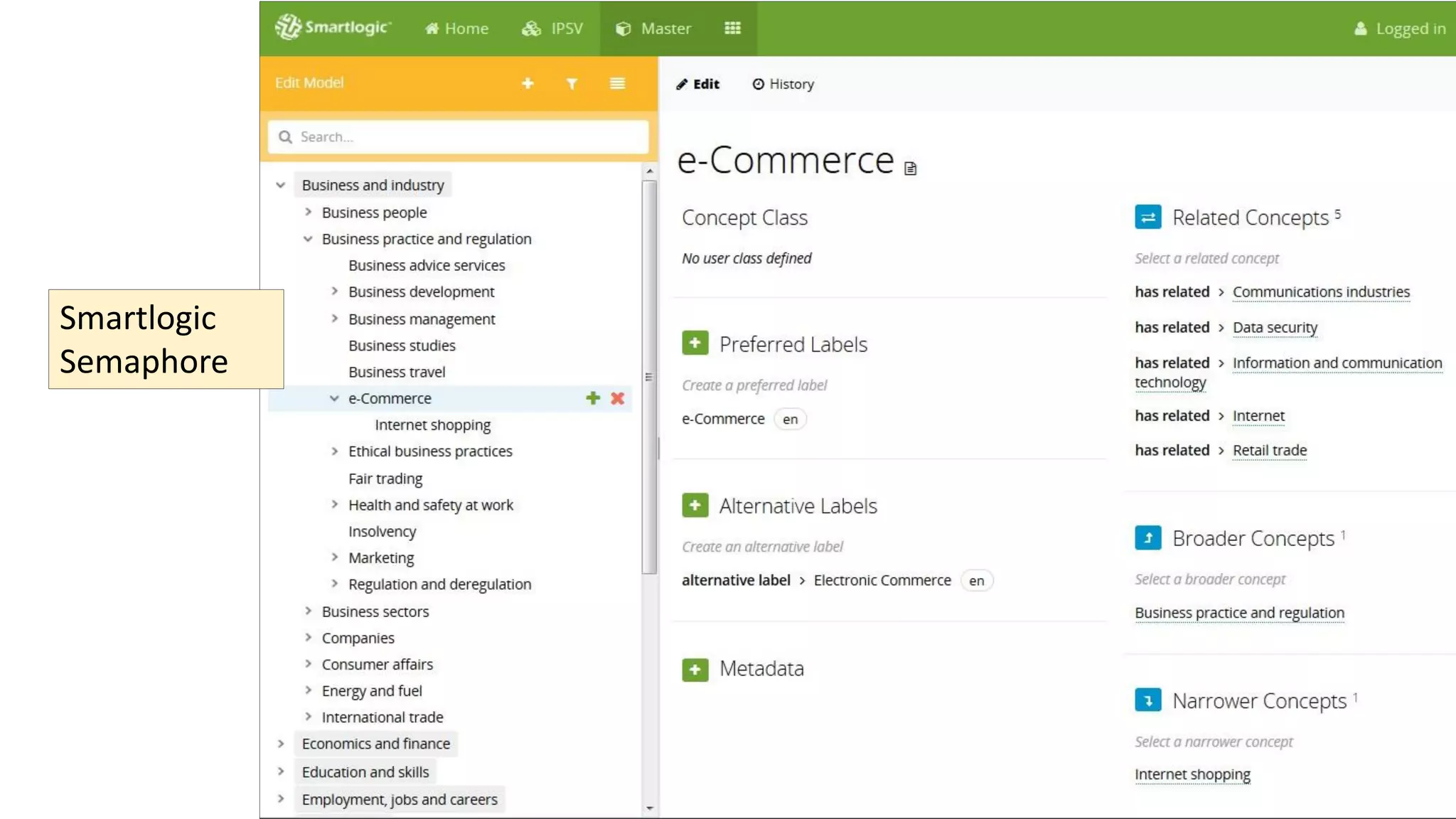

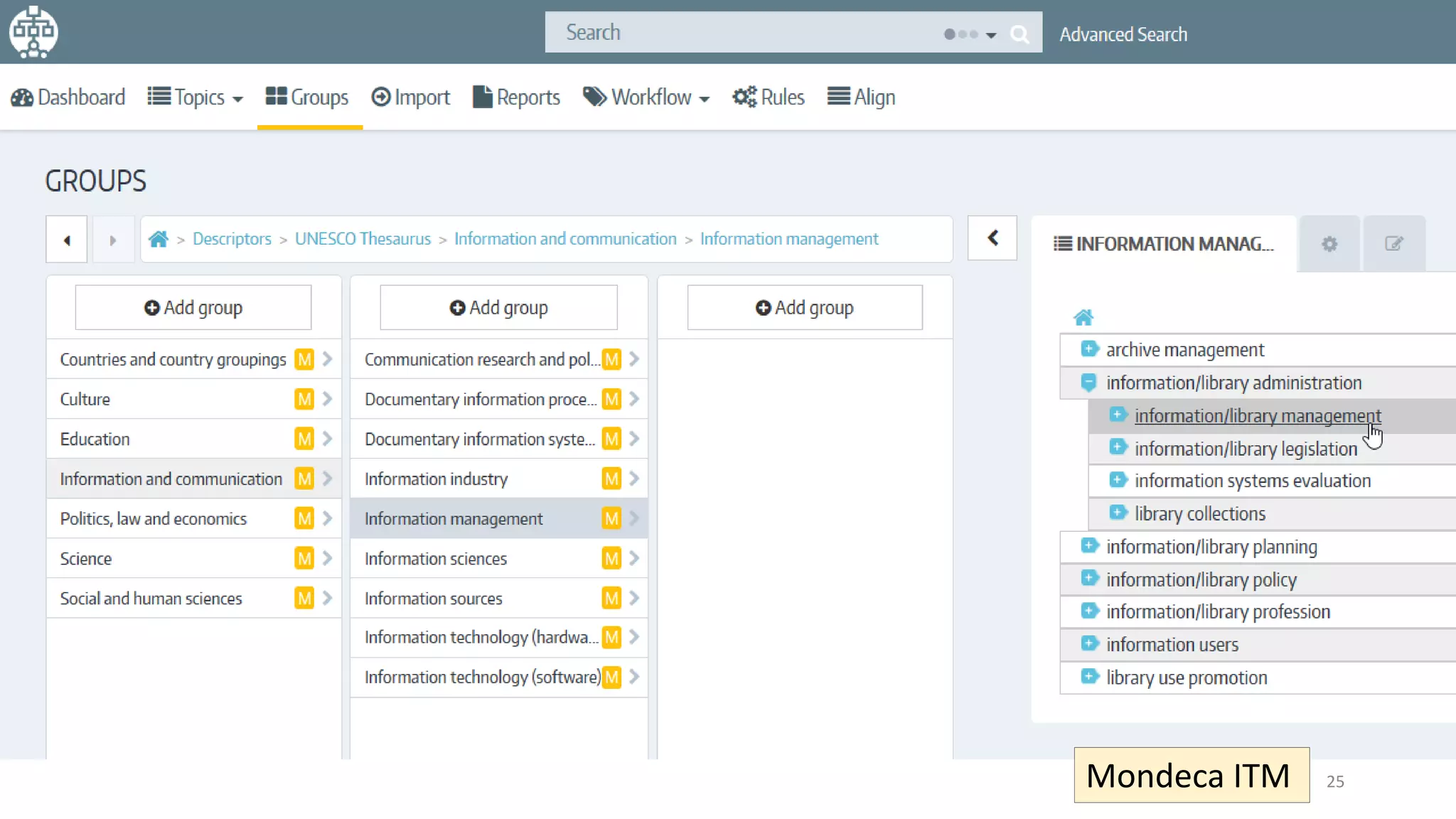





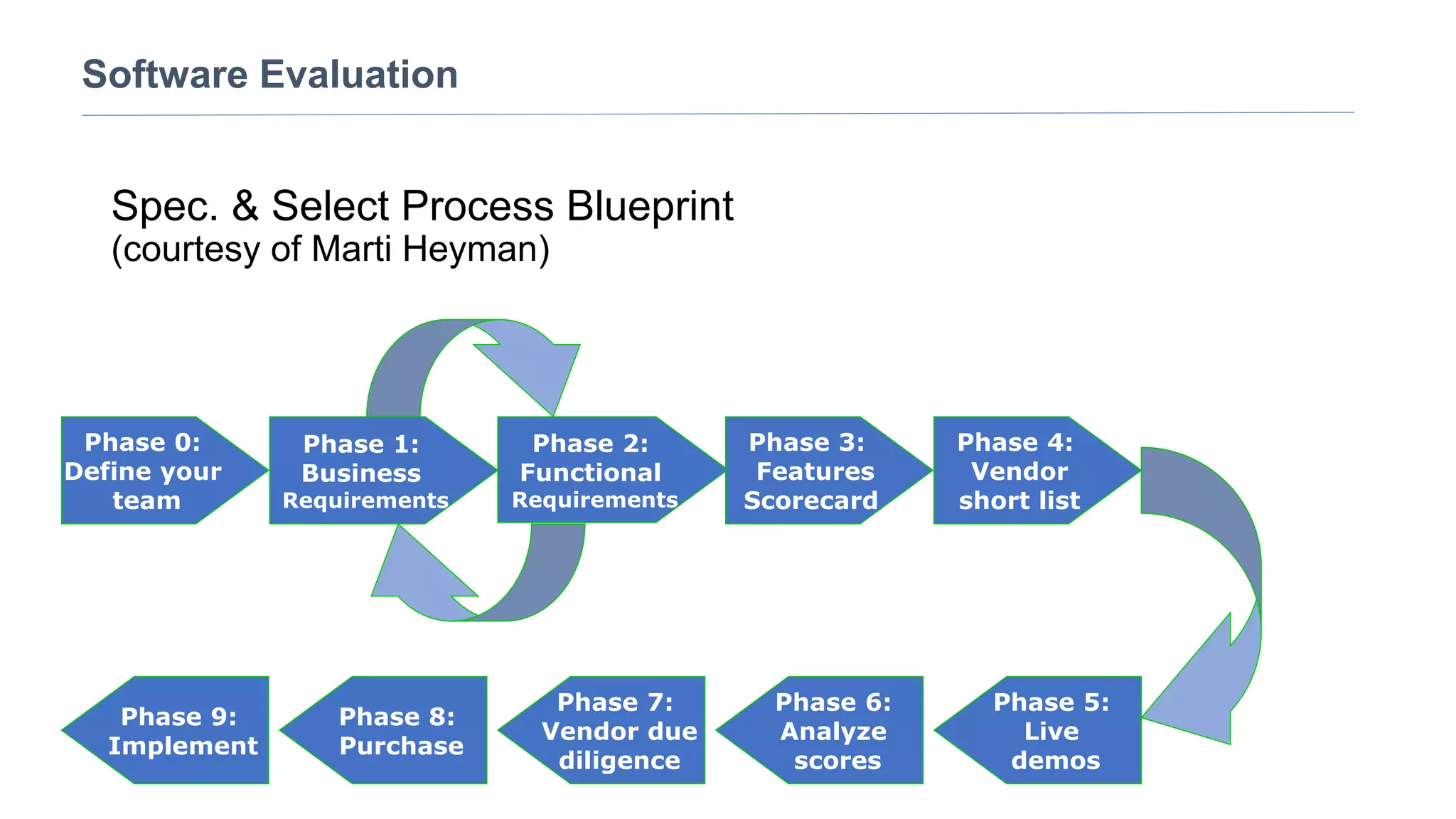

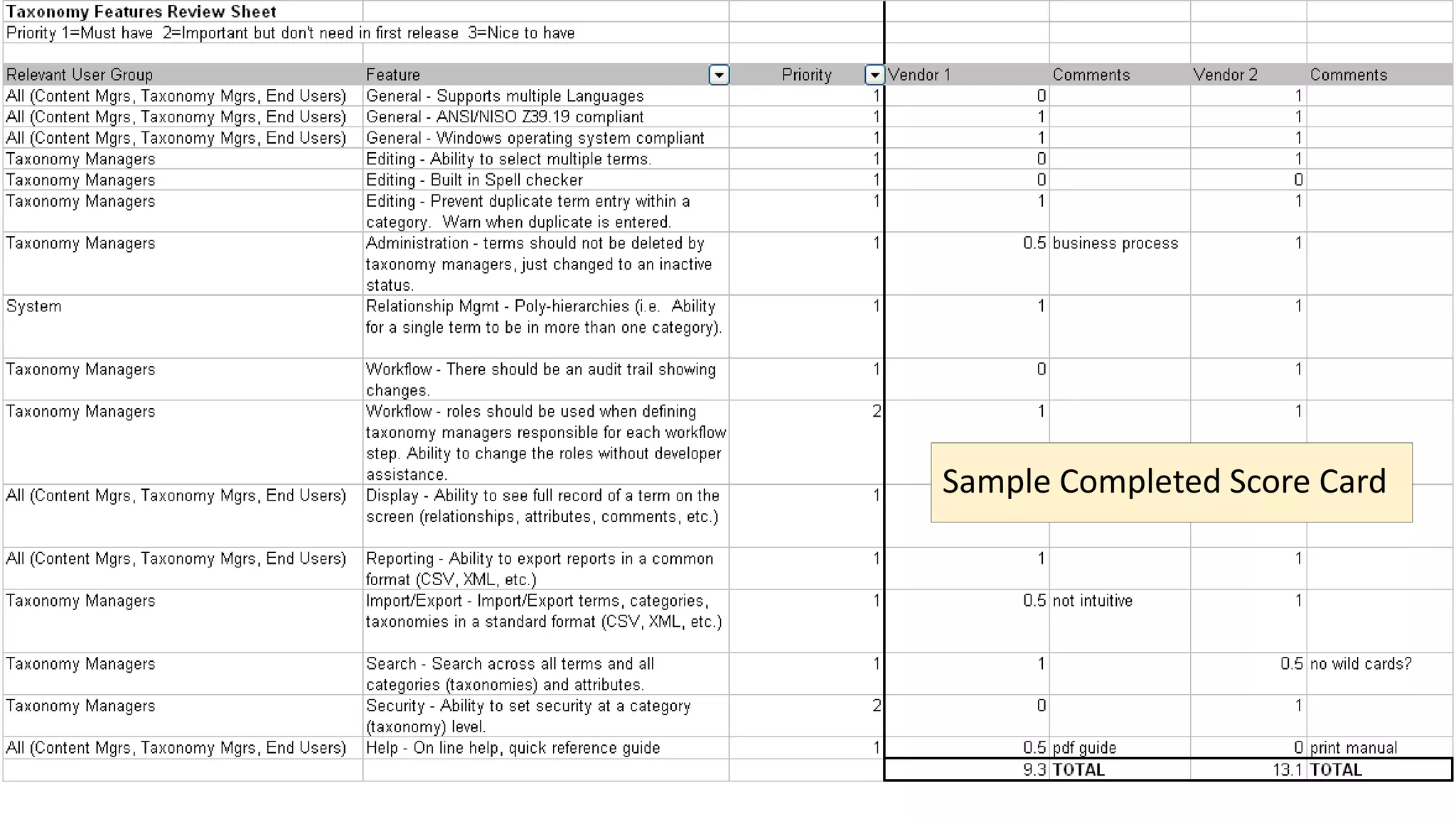



The document discusses selecting software for managing taxonomies, thesauri, and ontologies, emphasizing the blurred lines between these concepts. It covers the types of software available, key standards for design, and additional features to consider when evaluating software options. The document provides a comprehensive overview of various software products, their functionalities, and evaluation processes, highlighting the importance of aligning software features with business requirements.















































































