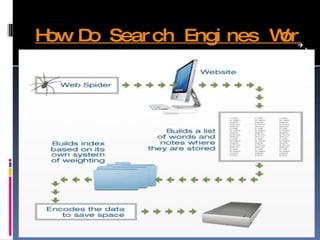
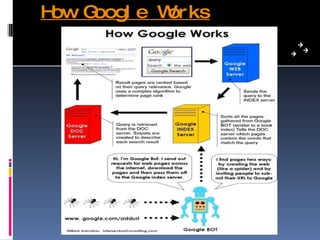
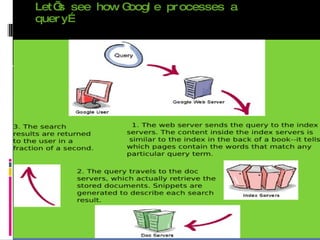
The document discusses how search engines like Google work. It explains that search engines use web crawlers or spiders to index websites by following links and reading content. The spiders send this indexed information back to be stored in a central database. When a user searches, the search engine compares the query to this index to find relevant results. Google in particular runs on thousands of computers to allow parallel processing for fast searching of its large index. It uses Googlebot to crawl and fetch pages which are then indexed and stored for query processing. PageRank and other factors are used to determine the most relevant results.






























![[US] 2014 Ranking Factors Webinar - Jordan Koene](https://cdn.slidesharecdn.com/ss_thumbnails/ranking-factors-webinar-141105162614-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)


























































