Downloaded 19 times





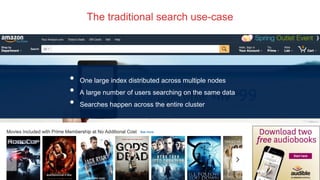











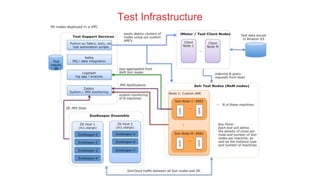
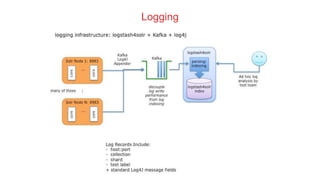
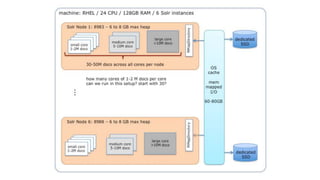










Anshum Gupta presented on scaling SolrCloud to support thousands of collections. Some challenges included limitations on the cluster state size, overseer performance issues under high load, and difficulties moving or exporting large amounts of data. Solutions involved splitting the cluster state, improving overseer performance through optimizations and dedicated nodes, enabling finer-grained shard splitting and data migration between collections, and implementing distributed deep paging for large result sets. Testing was performed on an AWS infrastructure to validate scaling to billions of documents and thousands of queries/updates per second. Ongoing work continues to optimize and benchmark SolrCloud performance at large scales.


















































![[Hic2011] using hadoop lucene-solr-for-large-scale-search by systex](https://cdn.slidesharecdn.com/ss_thumbnails/hic2011usinghadoop-lucene-solr-for-large-scale-searchbysystex-111205021544-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)
