Download as PDF, PPTX





![6
• Can not flatten, need to retain context
• Relationship between documents
• Get all 'positive comments' to 'posts about
Trump' -- IMPOSSIBLE!!!
Nested Documents
EXAMPLE: Data Flattening
Title: Peter Navarro outlines the Trump economic plan
Author: Tyler Cowen
Date: September 27, 2016 at 3:07am
Body: Trump proposes eliminating America’s $500 billion
trade deficit through a combination of increased exports and
reduced imports.
Comment_authors: [Ray Lopez, Brian Donohue]
Comment_dates: [September 27, 2016 at 3:21 am,
September 27, 2016 at 9:20 am]
Comment_texts: ["I’ll be the first to say this, but the analysis is
flawed.", "The math checks out. Solid."]
Comment_sentiments: [negative, positive]](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-6-2048.jpg)





![12
• Add _childDocument_ tags for all children
• Pre-process field names to FQNs
• Lose information, or add that as meta-data during pre-processing
solr-6.2.1$ bin/post -c demo-solr-json ./data/small-example-data-solr.json -format solr
Sending Documents to Solr: JSON Documents
[{ "path": "1.posts",
"id": "28711",
"author": "Alex Tabarrok",
"title": "The Irony of Hillary Clinton’s Data Analytics",
"body": "Barack Obama’s campaign adopted data but Hillary Clinton’s campaign
has been molded by data from birth.",
"_childDocuments_": [
{
"path": "2.posts.comments",
"id": "28711-19237",
"author": "Todd",
"text": "Clinton got out data-ed and out organized in 2008 by Obama. She
seems at least to learn over time, and apply the lessons learned to the real world.",
"sentiment": "positive",
"_childDocuments_": [
{
"path": "3.posts.comments.replies",
"author": "The Other Jim",
"id": "28711-12444",
"sentiment": "negative",
"text": "No, she lost because (1) she is thoroughly detested person and
(2) the DNC decided Obama should therefore win."
}]}]}]](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-12-2048.jpg)





![18
{
"path":["4.posts.comments.replies.keywords"],
"text":["Trump"]},
{
"path":["3.posts.comments.keywords"],
"text":["Trump"]},
{
"path":["2.posts.keywords"],
"text":["Trump"]},
{
"text":["LOL. I enjoyed Trump during last night’s stand-up bit, but this is funnier."],
"path":["3.posts.comments.replies"]},
{
"text":["Trump proposes eliminating America’s $500 billion trade deficit through a combination of increased exports and reduced imports."],
"path":["1.posts"]},
{
"text":["Hillary was impressive, for sure, and Trump spent time spluttering and floundering, but he was actually able to find his feet and score some points."],
"path":["2.posts.comments"]}
Easy question first
Find all documents that mention Trump
q=text:Trump](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-18-2048.jpg)
![19
{
"text":["LOL. I enjoyed Trump during last night’s stand-up bit, but this is funnier."],
"path":["3.posts.comments.replies"]},
{
"text":["Hillary was impressive, for sure, and Trump spent time spluttering and floundering, but he was actually able to find his feet and score some points."],
"path":["2.posts.comments"]},
{
"text":["No one goes to Clinton rallies while tens of thousands line up to see Trump, data-mining leads to a fantasy view of the World."],
"path":["2.posts.comments"]}
Returning certain types of documents
Find all comments and replies that mention Trump
q=(path:2.posts.comments OR path:3.posts.comments.replies) AND text:Trump
Recipe:
At the data pre-processing stage, add a field that indicates document type
and also its path in the hierarchy (-- stay tuned):](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-19-2048.jpg)
![20
{
"path":["3.posts.comments.keywords"],
"sentiment":["positive"],
"text":["Hillary"]},
{
"path":["4.posts.comments.replies.keywords"],
"sentiment":["negative"],
"text":["Hillary"]},
{
"path":["2.posts.keywords"],
"text":["Hillary"]}
Returning similar type from different level
Find all keywords that are Hillary
q=path:*.keywords AND text:Hillary
Recipe:
Use wild-cards in the field that stores the hierarchy path](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-20-2048.jpg)

![22
{
"path":["3.posts.comments.keywords"],
"sentiment":["positive"],
"text":["Hillary"]},
{
"path":["4.posts.comments.replies.keywords"],
"sentiment":["negative"],
"text":["Hillary"]},
{
"path":["2.posts.keywords"],
"text":["Hillary"]}
Recap so far...
Find all keywords that are Hillary
q=path:*.keywords AND text:Hillary
We're querying precisely for documents
which we provide a search condition for
Query
Level 3
Result
Level 3
Query
Level 4
Result
Level 4
Query
Level 2
Result
Level 2](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-22-2048.jpg)
![23
Returning parents by querying children:
Block Join Parent Query
Find all comments whose keywords detected positive sentiment towards Hillary
q={!parent which="path:2.posts.comments"}path:3.posts.comments.keywords AND text:Hillary AND sentiment:positive
Query
Level 3
Result
Level 2
{
"author":["Brian Donohue"],
"text":["Hillary was impressive, for sure, and Trump spent time spluttering and floundering,
but he was actually able to find his feet and score some points."],
"path":["2.posts.comments"]},
{
"author":["Todd"],
"text":["Clinton got out data-ed and out organized in 2008 by Obama. She seems at least to
learn over time, and apply the lessons learned to the real world."],
"path":["2.posts.comments"]}](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-23-2048.jpg)
![24
{
"sentiment":["negative"],
"text":["LOL. I enjoyed Trump during last night’s stand-up bit, but this is funnier."],
"path":["3.posts.comments.replies"]},
{
"sentiment":["neutral"],
"text":["So then I guess he will also eliminate the current account surplus? What will happen to U.S.
asset values?"],
"path":["3.posts.comments.replies"]},
{
"sentiment":["positive"],
"text":["Agreed why spend time data-mining for a fantasy view of the world , when instead you can see
a fantasy in person?"],
"path":["3.posts.comments.replies"]}
Returning children by querying parents:
Block Join Child Query
Find replies to negative comments
q={!child of="path:2.posts.comments"}path:2.posts.comments AND sentiment:negative&fq=path:3.posts.comments.replies
Query
Level 2
Result
Level 3
Block Join Child Query + Filter Query
A bit counterintuitive and non-symmetrical to the BJPQ](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-24-2048.jpg)
![25
Returning all document's descendants
Block Join Child Query
Find all descendants of negative comments
q={!child of="path:2.posts.comments"}path:2.posts.comments AND sentiment:negative
Query
Level 2
Results
Level 3
Results
Level 4
{
"path":["4.posts.comments.replies.keywords"],
"id":"17413-13550",
"text":["Trump"]},
{
"text":["LOL. I enjoyed Trump during last night’s stand-up bit, but this is funnier."],
"path":["3.posts.comments.replies"],
"id":"17413-66188"},
{
"path":["3.posts.comments.keywords"],
"id":"12413-12487",
"text":["Hillary"]},
{
"text":["Agreed why spend time data-mining for a fantasy view of the world , when instead you can see
a fantasy in person?"],
"path":["3.posts.comments.replies"],
"id":"12413-10998"}
Issue: no grouping by parent
What if we want to bring the whole sub-structure?](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-25-2048.jpg)
![26
Find all negative comments and return them with all their descendants
q=path:2.posts.comments AND sentiment:negative&fl=*,[child parentFilter=path:2.*]
Query
Level 2
Result
Level 2
sub-
hierarchy
Returning document with all descendants:
ChildDocTransformer
{
"sentiment":["negative"],
"text":["I’ll be the first to say this, but the analysis is flawed."],
"path":["2.posts.comments"],
"_childDocuments_":[
{
"path":["4.posts.comments.replies.keywords"],
"text":["Trump"]},
{
"text":["LOL. I enjoyed Trump during last night’s stand-up bit, but this is funnier."],
"path":["3.posts.comments.replies"]},
{
"path":["4.posts.comments.replies.keywords"],
"text":["U.S."]},
{
"text":["So then I guess he will also eliminate the current account surplus? What
will happen to U.S. asset values?"],
"path":["3.posts.comments.replies"]}
]
},
...
Issue: the "sub-hierarchy" is flat](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-26-2048.jpg)
![• Returns all descendant documents along with the queried document
• flattens the sub-hierarchy
• Workarounds:
• Reconstruct the document using path ("path":["3.posts.comments.replies"])
information in case you want the entire subtree (result post-processing)
• use childFilter in case you want a specific level
27
“This transformer returns all descendant documents of each parent document matching your query in
a flat list nested inside the matching parent document." (ChildDocTransformer cwiki)
Returning document with all descendants:
ChildDocTransformer](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-27-2048.jpg)
![28
Find all negative comments and return them with all replies to them
q=path:2.posts.comments AND sentiment:negative&fl=*,[child parentFilter=path:2.*
childFilter=path:3.posts.comments.replies]
{
"sentiment":["negative"],
"text":["I’ll be the first to say this, but the analysis is flawed."],
"path":["2.posts.comments"],
"_childDocuments_":[
{
"text":["LOL. I enjoyed Trump during last night’s stand-up bit, but this is
funnier."],
"path":["3.posts.comments.replies"]},
{
"text":["So then I guess he will also eliminate the current account surplus? What
will happen to U.S. asset values?"],
"path":["3.posts.comments.replies"]}
]
},
...
Returning document with specific descendants:
ChildDocTransformer + childFilter
Query
Level 2:comments
Result
Level 2:comments
+ Level 3:replies](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-28-2048.jpg)
![29
Find all negative comments and return them with all their descendants that mention Trump
q=path:2.posts.comments AND sentiment:negative&fl=*,[child parentFilter=path:2.* childFilter=text:Trump]
{
"sentiment":["negative"],
"text":["I’ll be the first to say this, but the analysis is flawed."],
"path":["2.posts.comments"],
"_childDocuments_":[
{
"path":["4.posts.comments.replies.keywords"],
"text":["Trump"]},
{
"text":["LOL. I enjoyed Trump during last night’s stand-up bit, but this is
funnier."],
"path":["3.posts.comments.replies"]}
]
},
...
Returning document with queried descendants:
ChildDocTransformer + childFilter
Query
Level 2:comments
Result
Level 2:comments
+ sub-levels
Issue: cannot use boolean expressions in childFilter query](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-29-2048.jpg)



![33
q=path:2.posts.comments AND sentiment:positive&
json.facet={
most_liked_authors : {
type: terms,
field: author,
domain: { blockParent : "path:1.posts"}
}}
Faceting on parents by descendants
JSON Facet API: Parent Domain
Count authors of the posts that received positive comments
"most_liked_authors":{
"buckets":[
{
"val":"Alex Tabarrok",
"count":1},
{
"val":"Tyler Cowen",
"count":1}
]
}
Query
Level 2
Facet
Level 1](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-33-2048.jpg)
![34
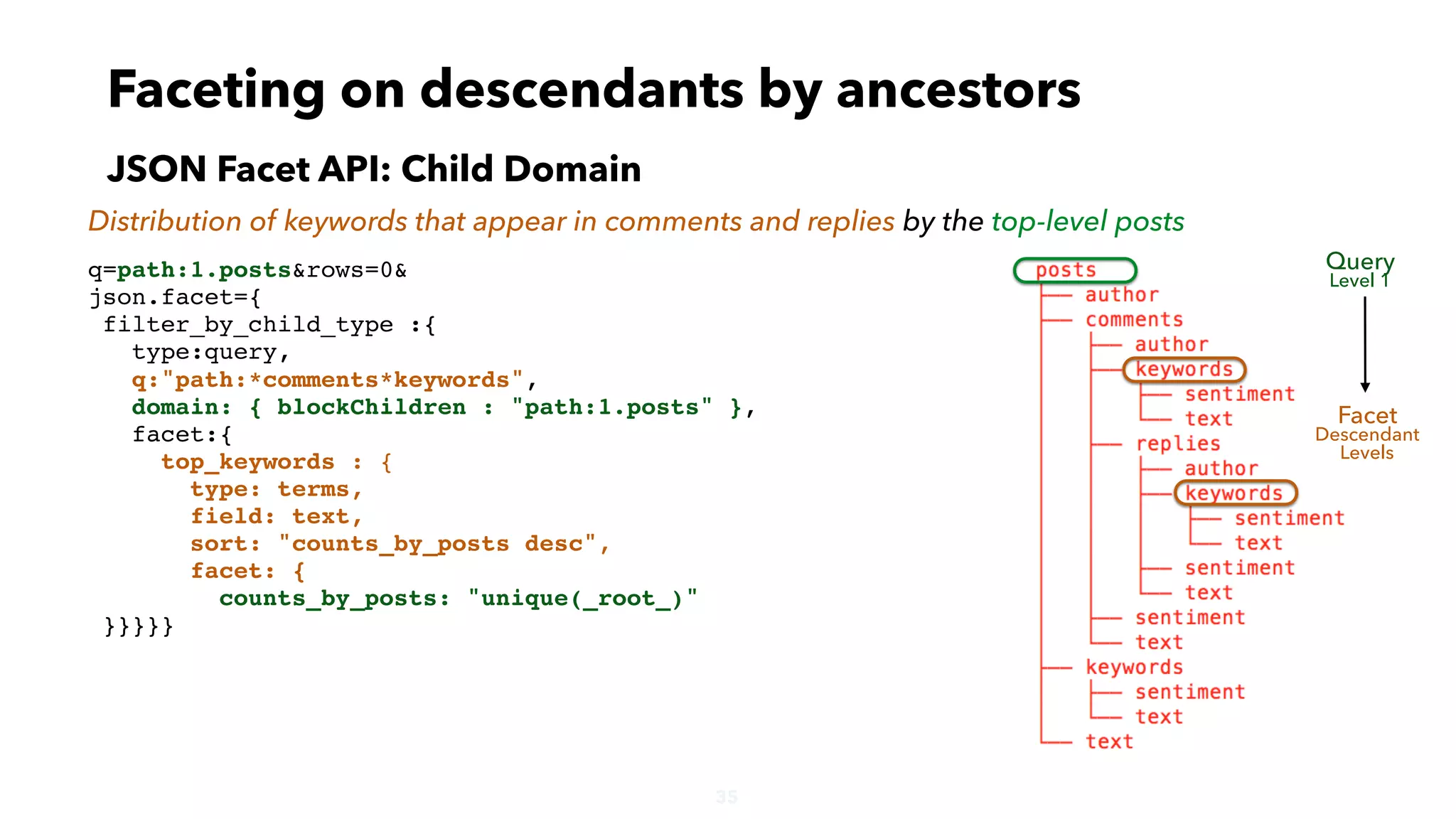
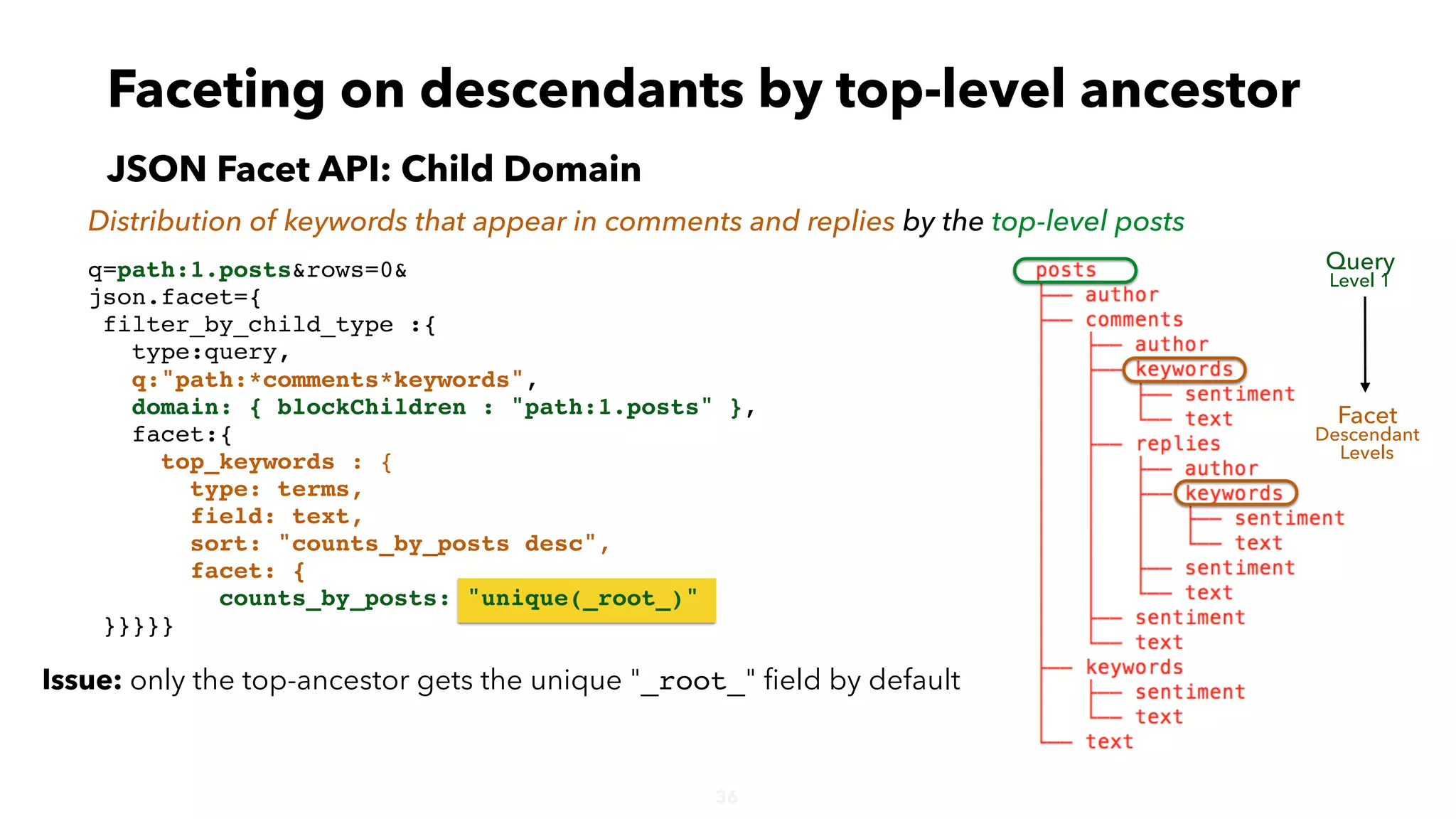
Faceting on descendants by ancestors
JSON Facet API: Child Domain
Distribution of keywords that appear in comments and replies by the top-level posts
Query
Level 1
Facet
Descendant
Levels
"top_keywords":{
"buckets":[{
"val":"hillary",
"count":4,
"counts_by_posts":2},
{
"val":"trump",
"count":3,
"counts_by_posts":2},
{
"val":"dnc",
"count":1,
"counts_by_posts":1},
{
"val":"obama",
"count":2,
"counts_by_posts":1},
{
"val":"u.s",
"count":1,
"counts_by_posts":1}
]}](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-34-2048.jpg)
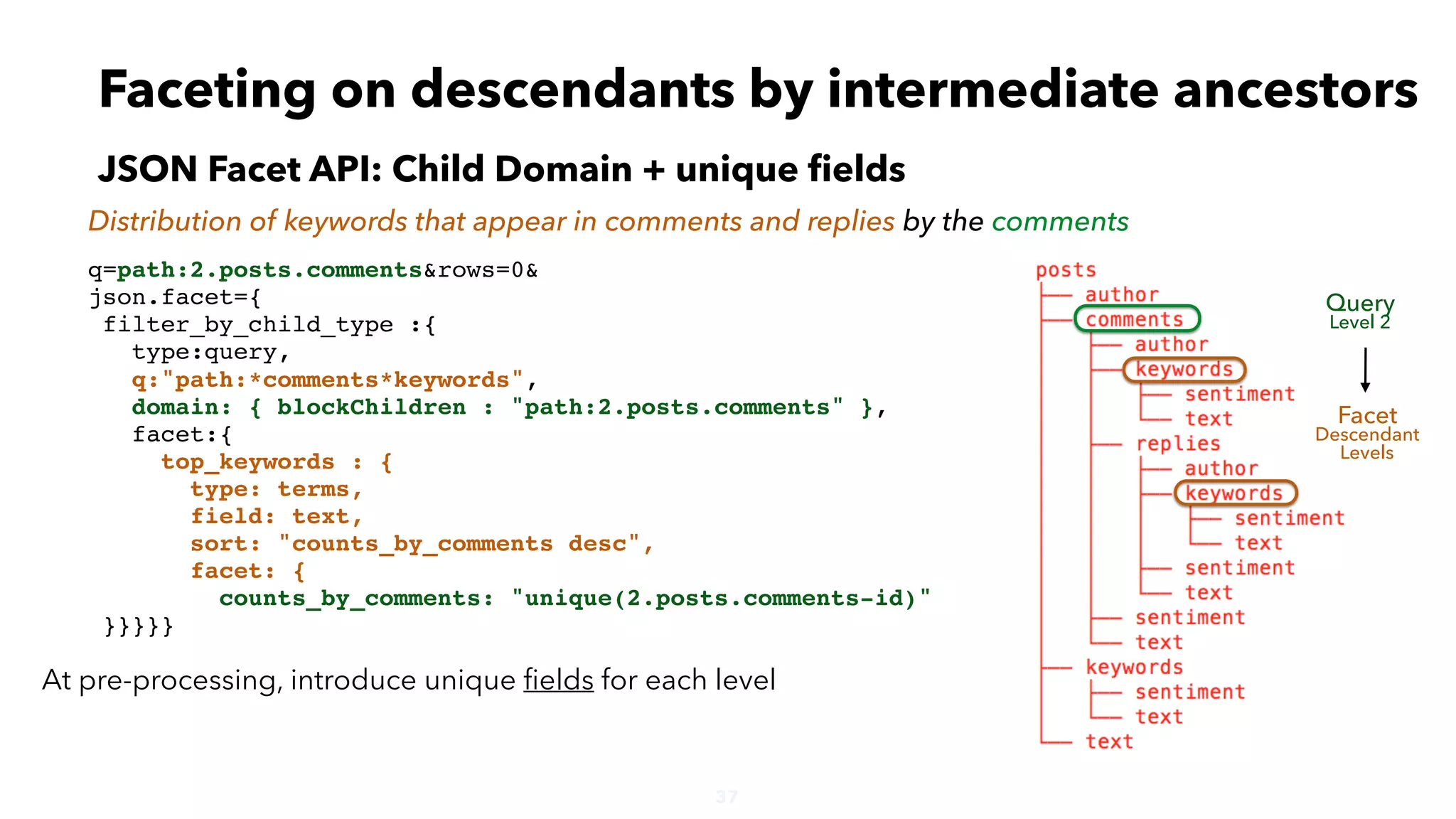
![38
Faceting on descendants by intermediate ancestors
JSON Facet API: Child Domain + unique fields
Distribution of keywords that appear in comments and replies by the comments
Query
Level 2
Facet
Descendant
Levels
"top_keywords":{
"buckets":[{
"val":"Hillary",
"count":4,
"counts_by_comments":3},
{
"val":"Trump",
"count":3,
"counts_by_comments":3},
{
"val":"DNC",
"count":1,
"counts_by_comments":1},
{
"val":"Obama",
"count":2,
"counts_by_comments":1},
{
"val":"U.S.",
"count":1,
"counts_by_comments":1}
]}](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-38-2048.jpg)


![41
bjqfacet?q={!parent which=path:2.posts.comments}
path:*.comments*keywords&rows=0&facet=true&child.facet.field=text
Faceting on descendants by ancestors #2:
Block Join Faceting on Children Domain
Distribution of keywords that appear in comments and replies by the comments
"facet_fields":{
"text":[
"dnc",1,
"hillary",3,
"obama",1,
"trump",3,
"u.s",1
]
}
Query
Level 2
Facet
Descendant
Levels
bjqfacet request handler instead of query](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-41-2048.jpg)
![42
Output Comparison
Block Join Facet JSON Facet API
"facet_fields":{
"text":[
"dnc",1,
"hillary",3,
"obama",1,
"trump",3,
"u.s",1
]
}
"top_keywords":{
"buckets":[{
"val":"Hillary",
"count":4,
"counts_by_comments":3},
{
"val":"Trump",
"count":3,
"counts_by_comments":3},
{
"val":"DNC",
"count":1,
"counts_by_comments":1},
{
"val":"Obama",
"count":2,
"counts_by_comments":1},
{
"val":"U.S.",
"count":1,
"counts_by_comments":1}
]}
Distribution of keywords that appear in comments and replies by the comments](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-42-2048.jpg)
![43
Output Comparison
Block Join Facet JSON Facet API
"facet_fields":{
"text":[
"dnc",1,
"hillary",3,
"obama",1,
"trump",3,
"u.s",1
]
}
"top_keywords":{
"buckets":[{
"val":"Hillary",
"count":4,
"counts_by_comments":3},
{
"val":"Trump",
"count":3,
"counts_by_comments":3},
{
"val":"DNC",
"count":1,
"counts_by_comments":1},
...
Distribution of keywords that appear in comments and replies by the comments
Output is sorted in alphabetical
order. It cannot be changed
facet:{
top_keywords : {
...
sort: "counts_by_comments desc"
}}}](https://image.slidesharecdn.com/hierarchicaldatainsolr-apachebigdataseville-161121085651/75/Working-with-deeply-nested-documents-in-Apache-Solr-43-2048.jpg)




The document discusses the challenges and techniques related to working with deeply nested documents in Apache Solr, including their indexing, querying, and faceting. It emphasizes the importance of retaining the hierarchical context of data, using examples such as blog posts and comments to illustrate the necessity of nested structures. Additionally, the document outlines various methods for indexing and querying these nested documents, highlighting specific commands and considerations for effective data management.























































































