Downloaded 26 times

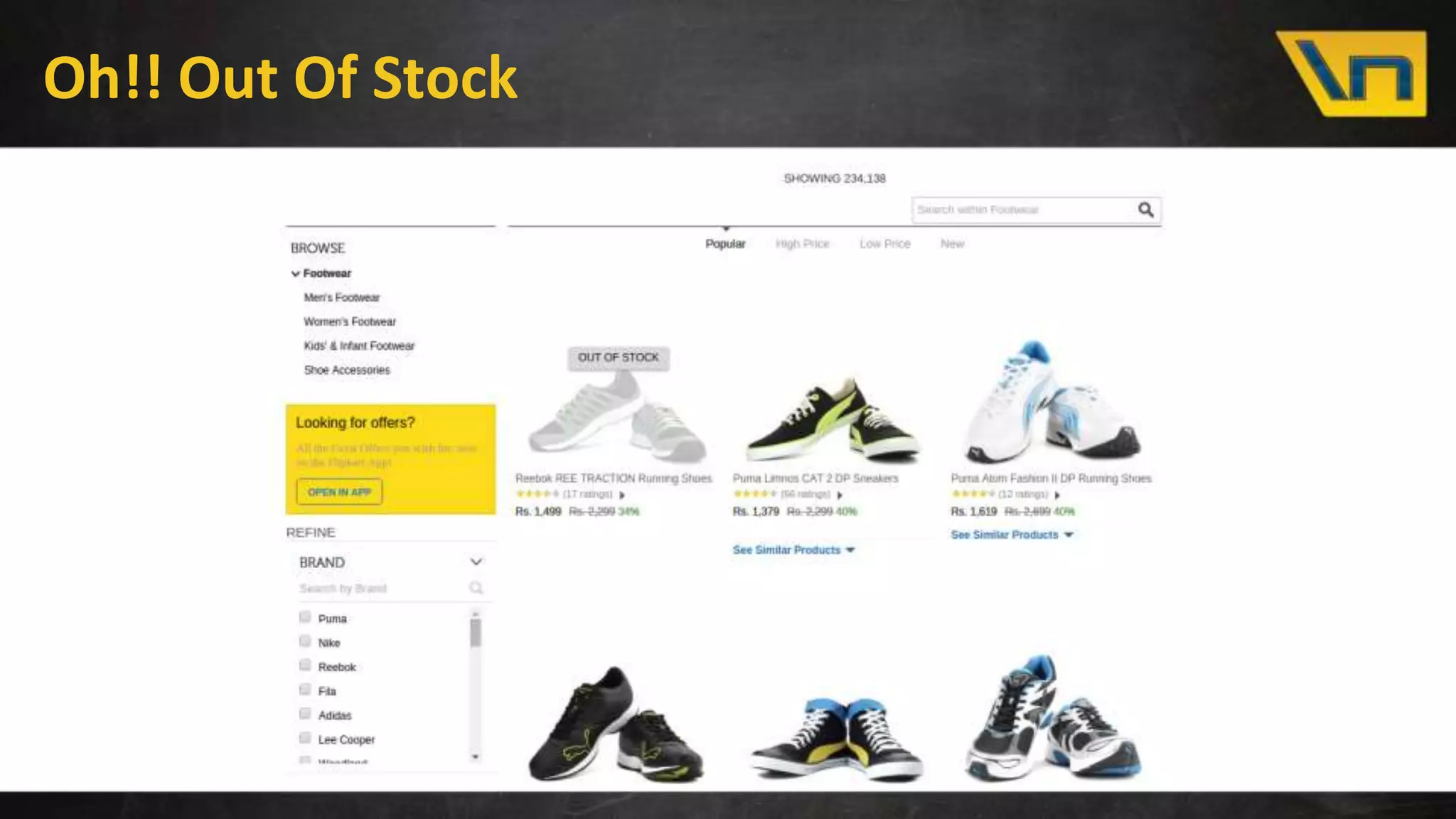
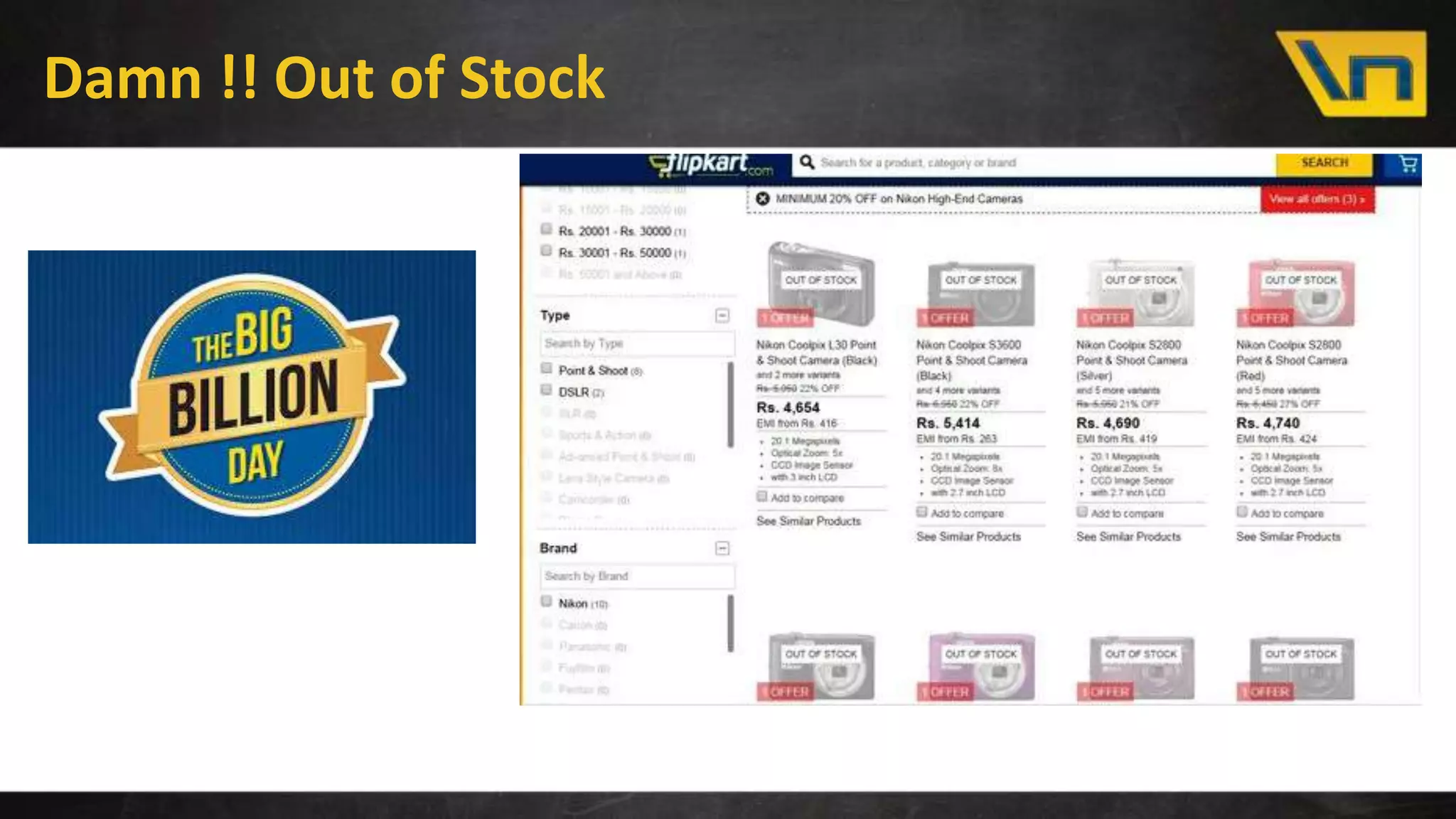



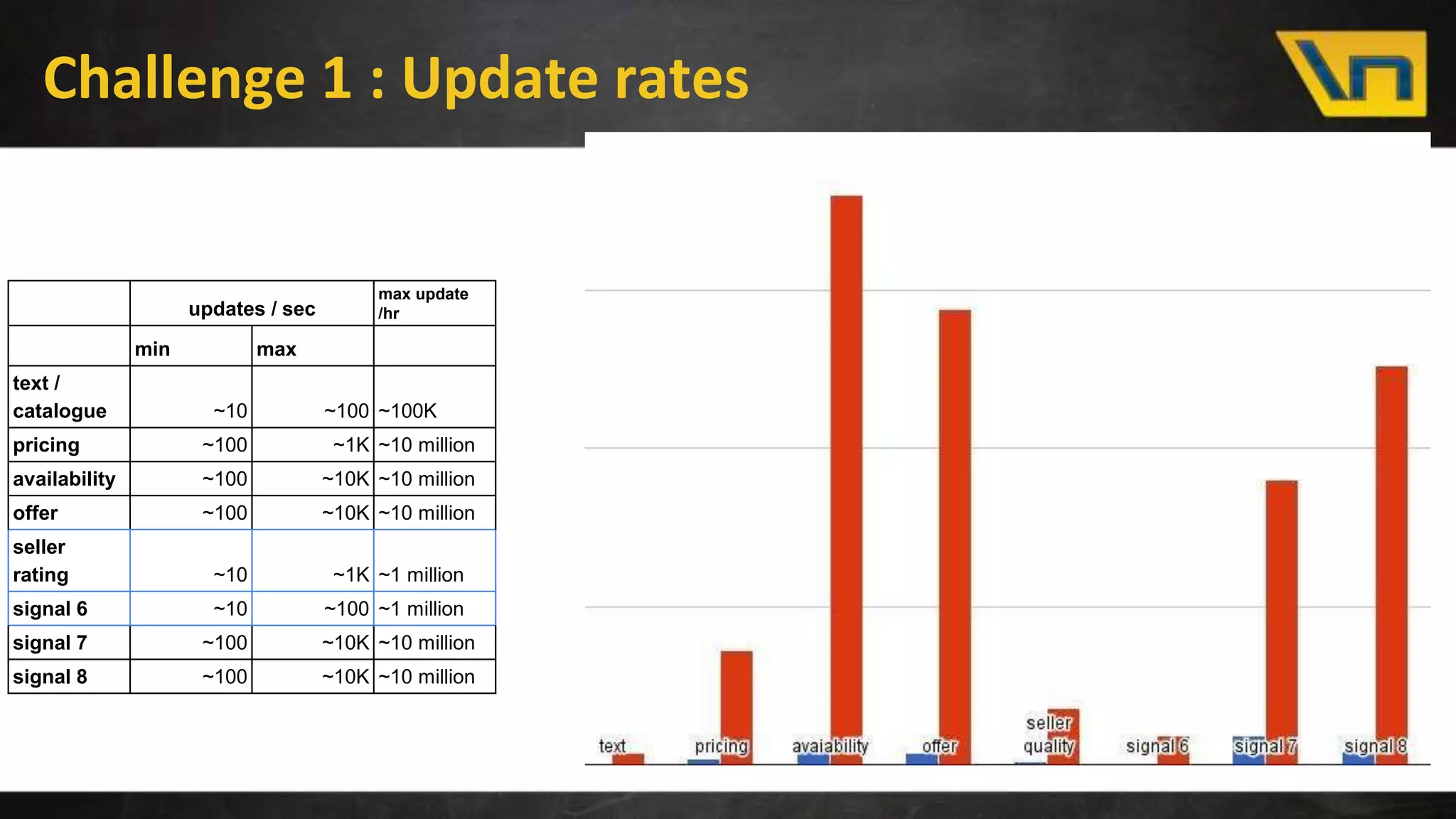

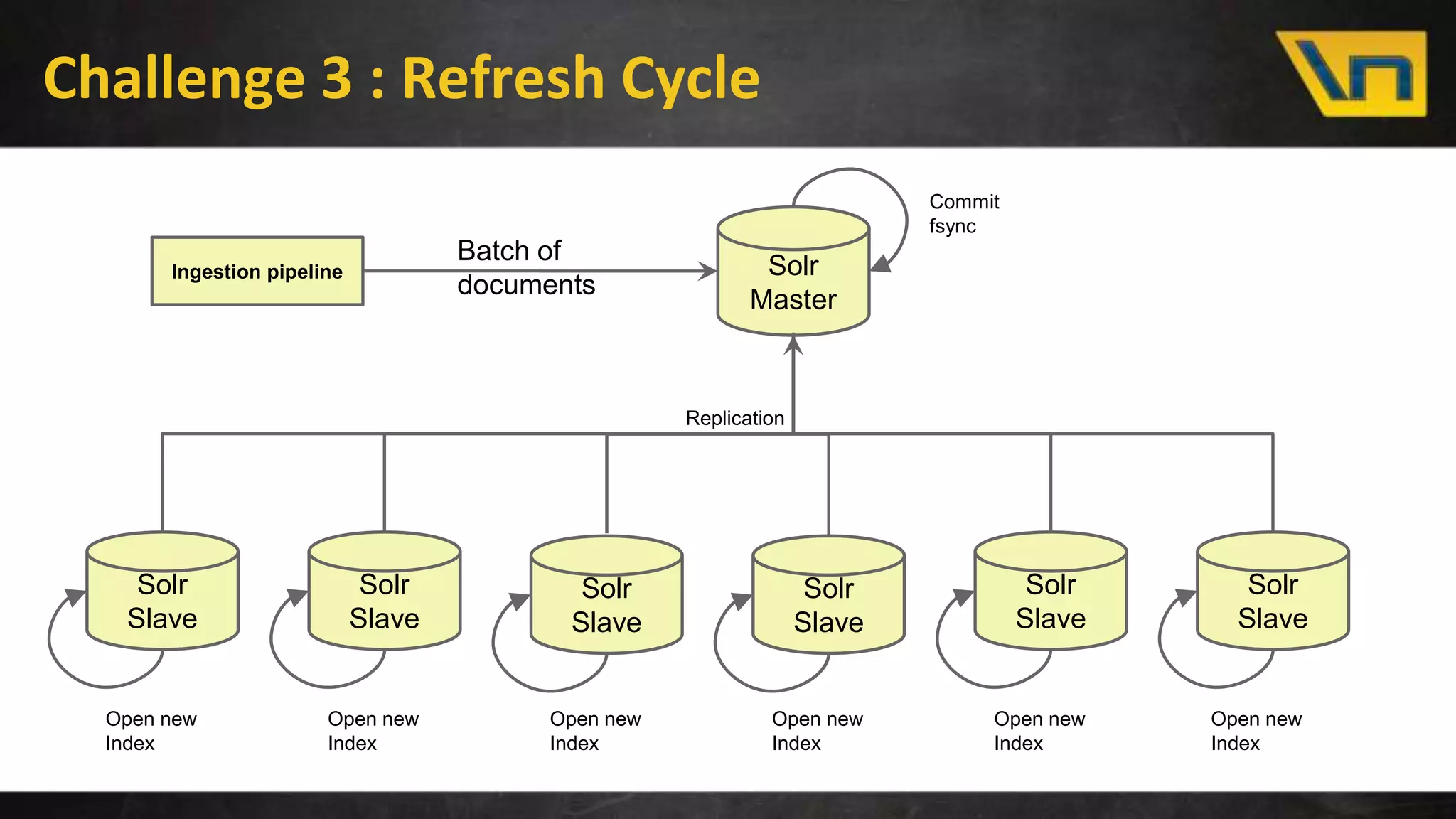
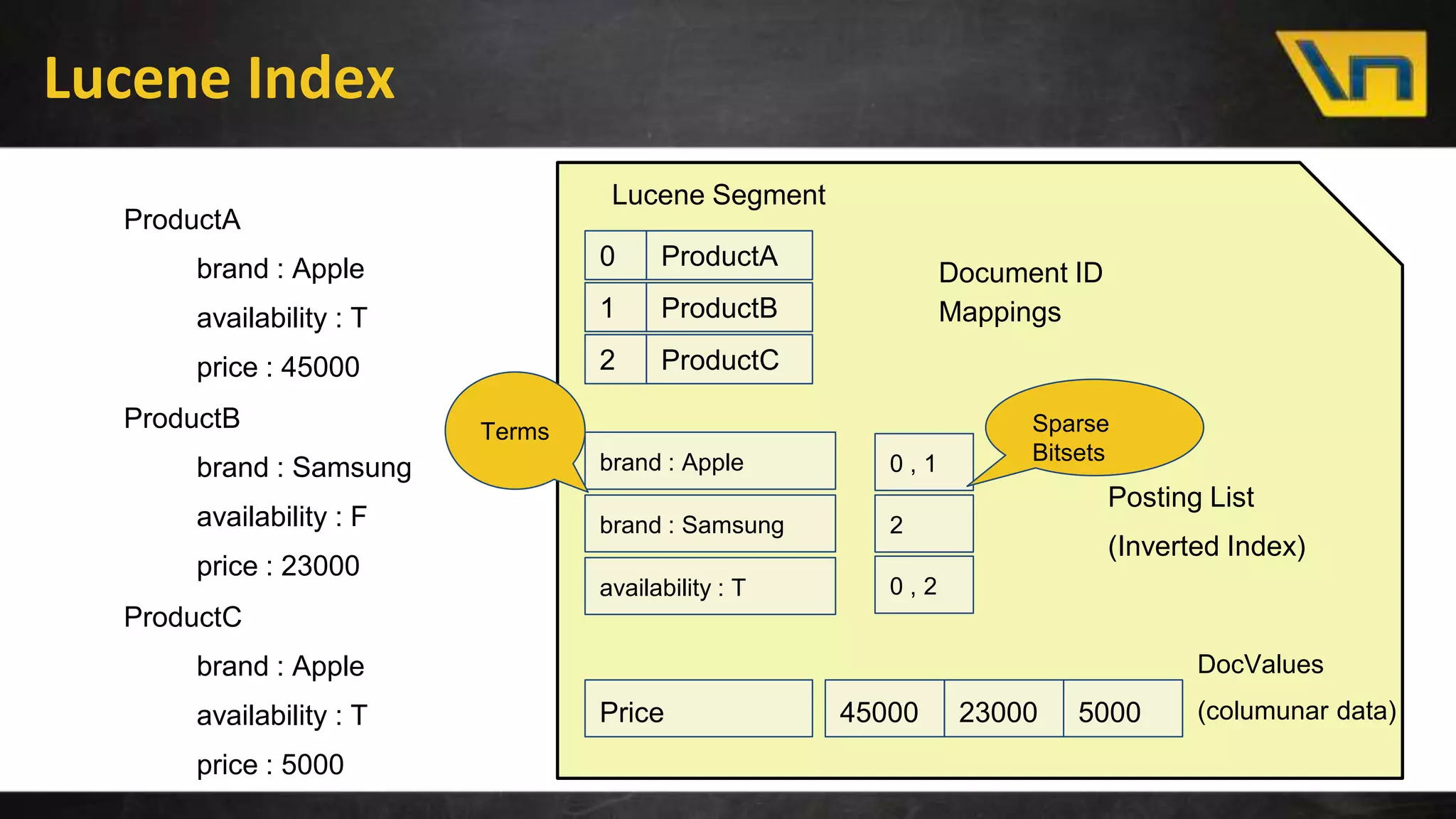
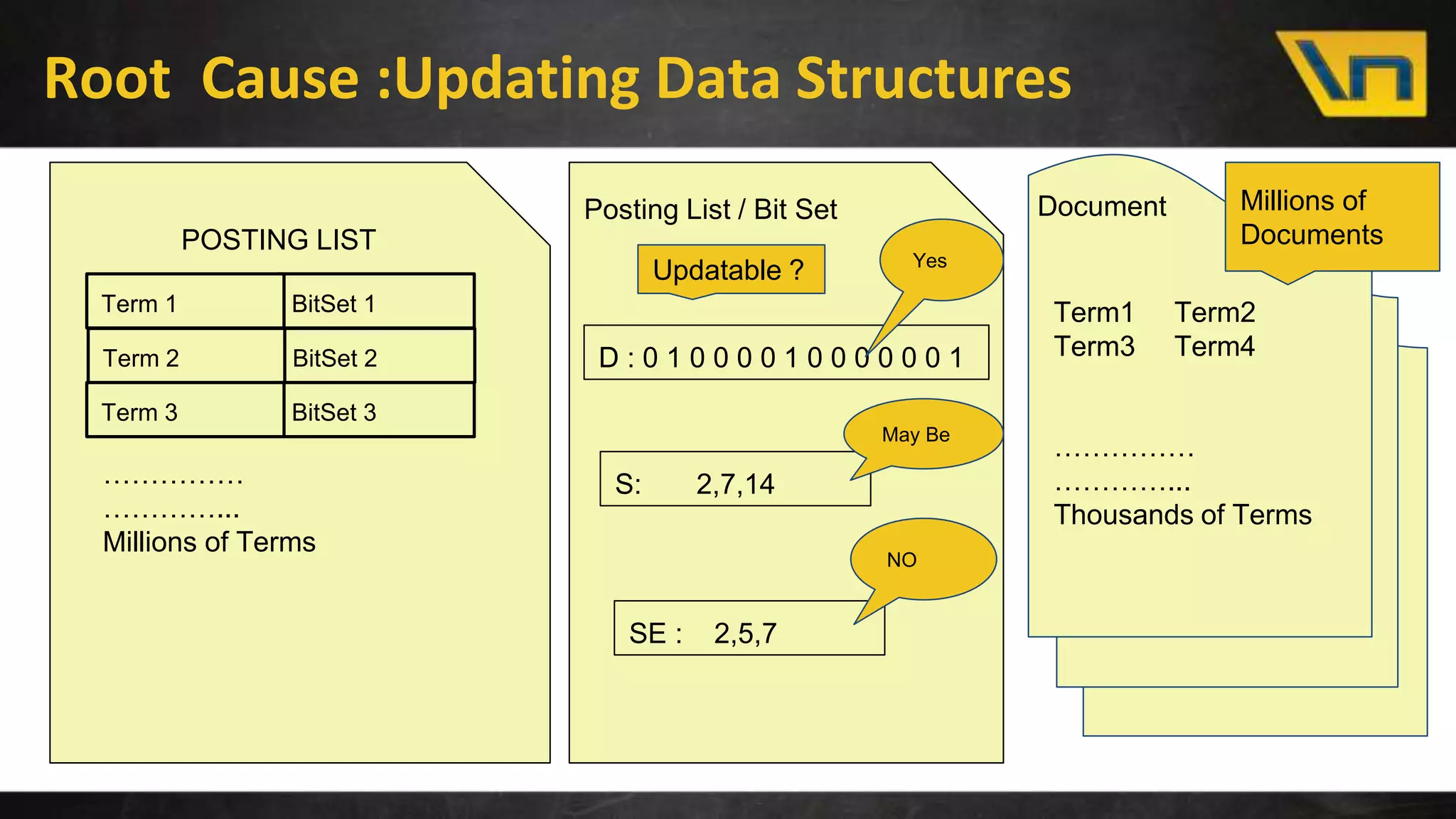
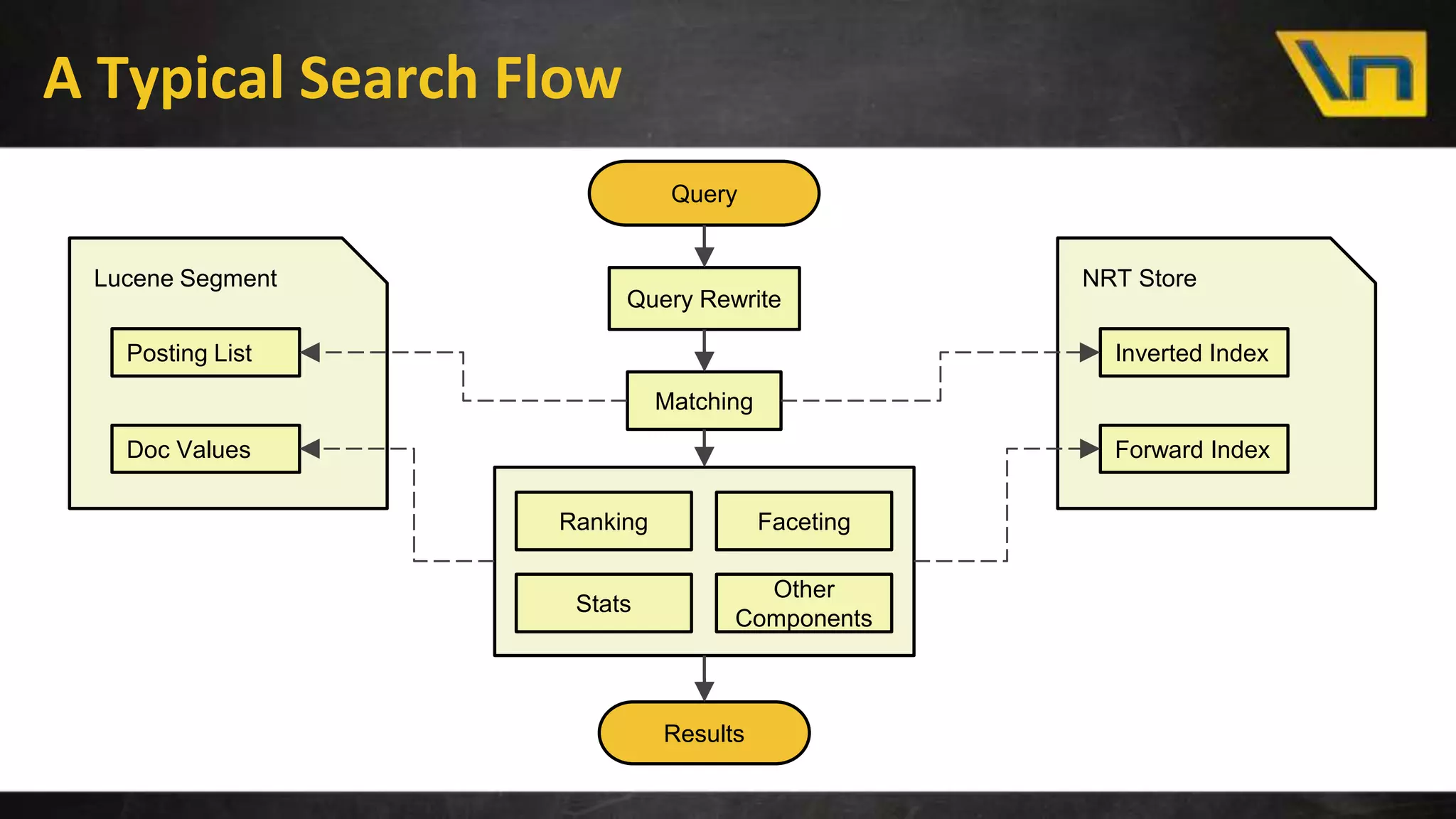

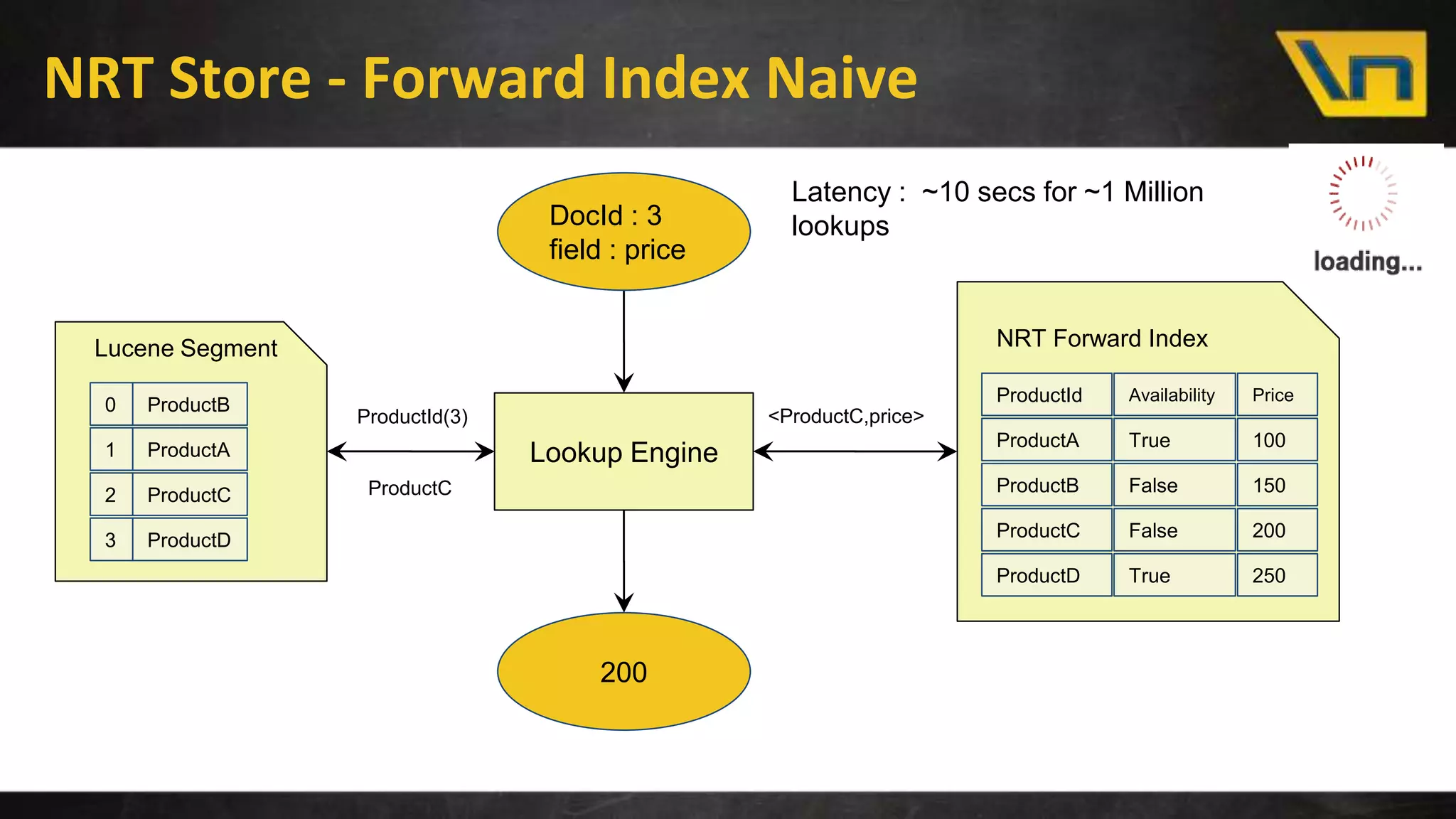
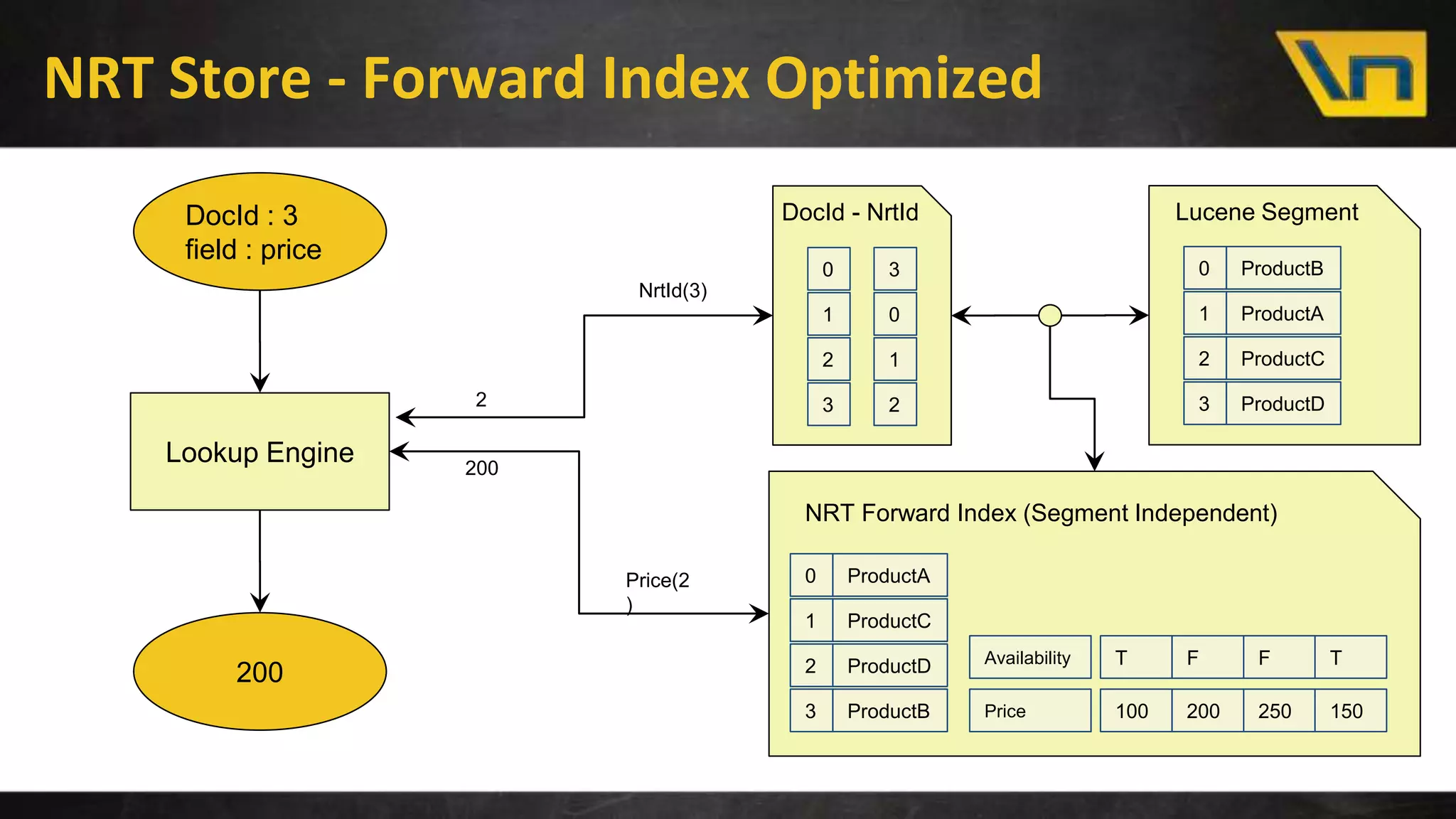
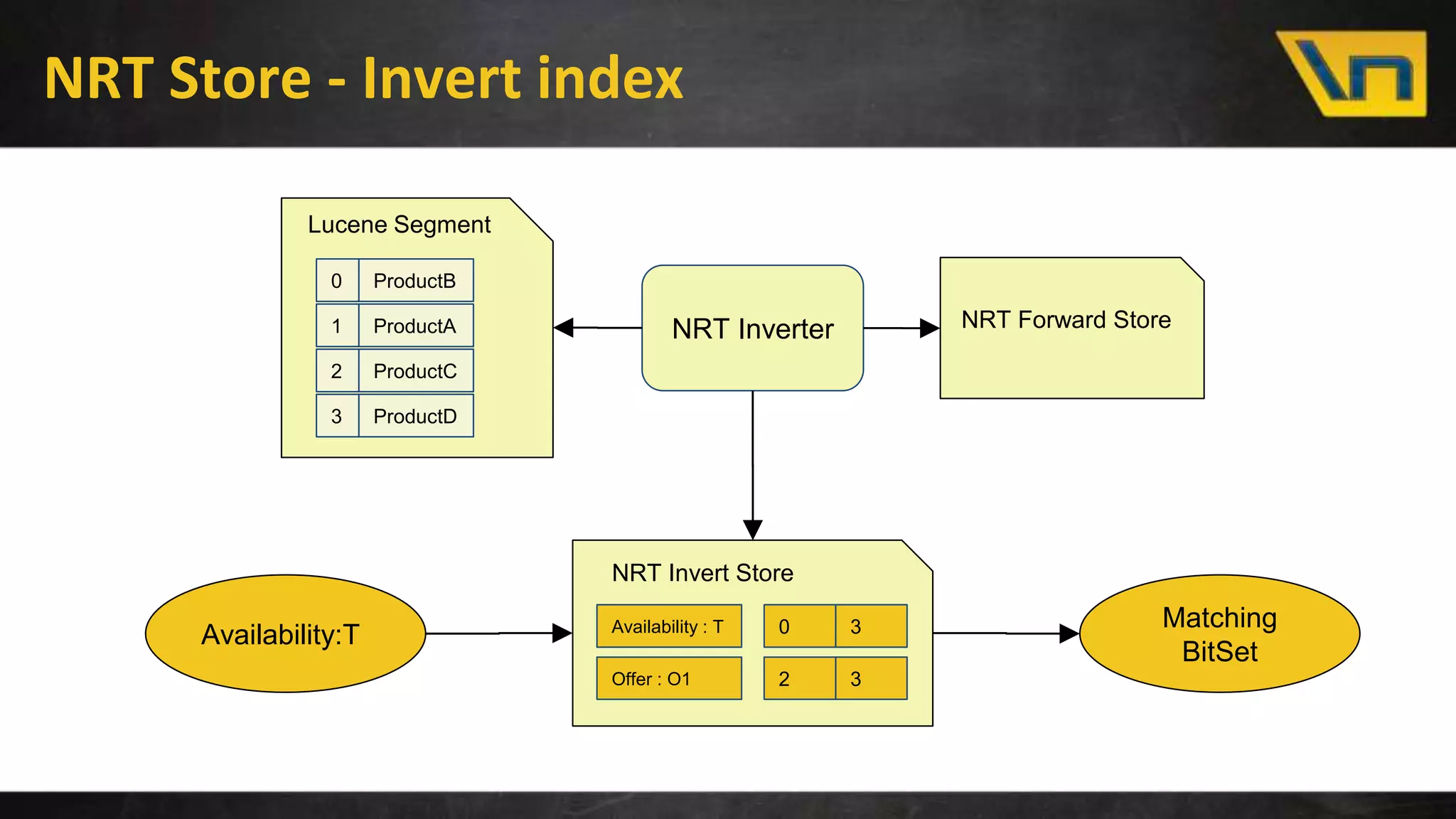
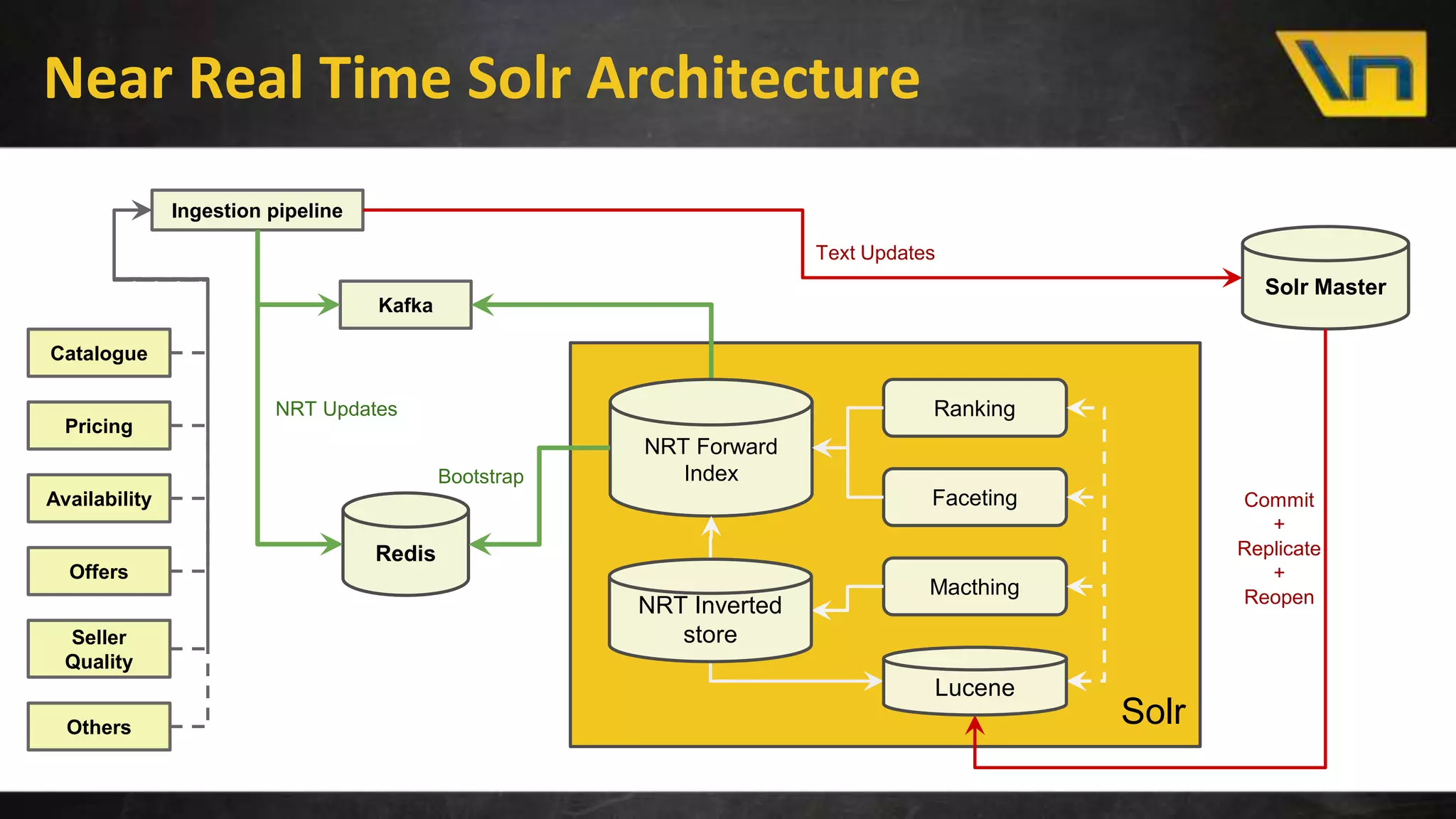


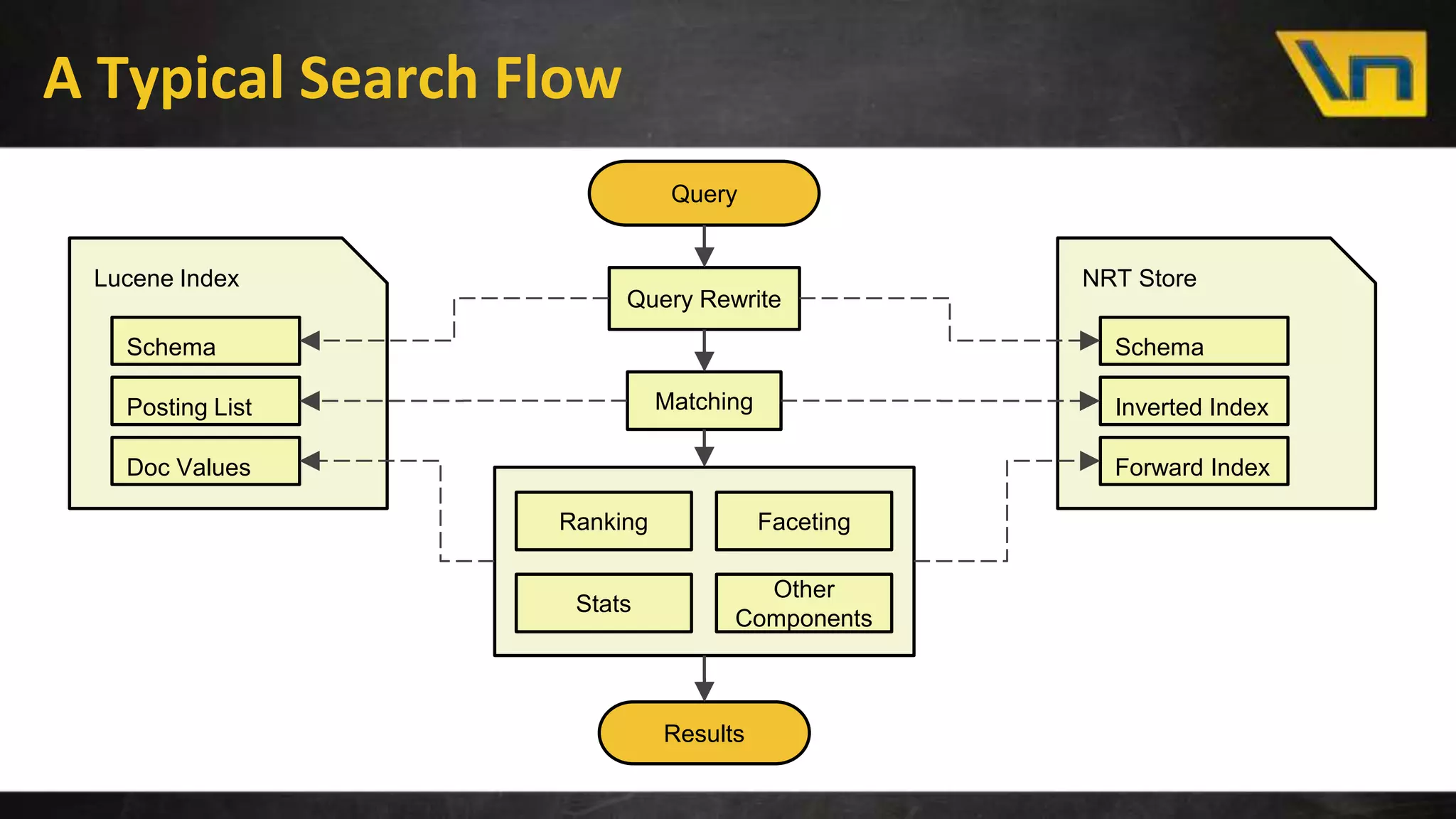
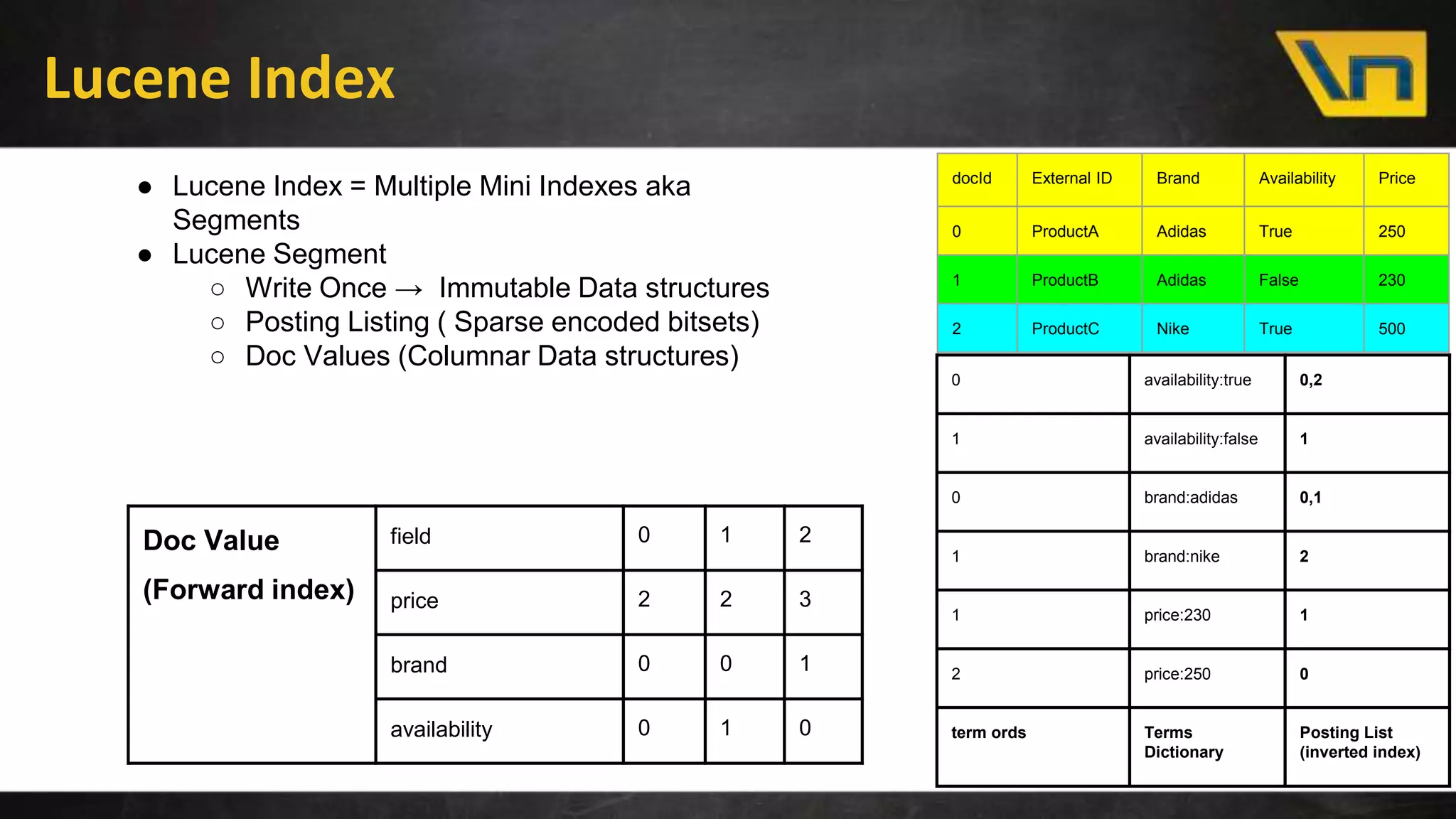
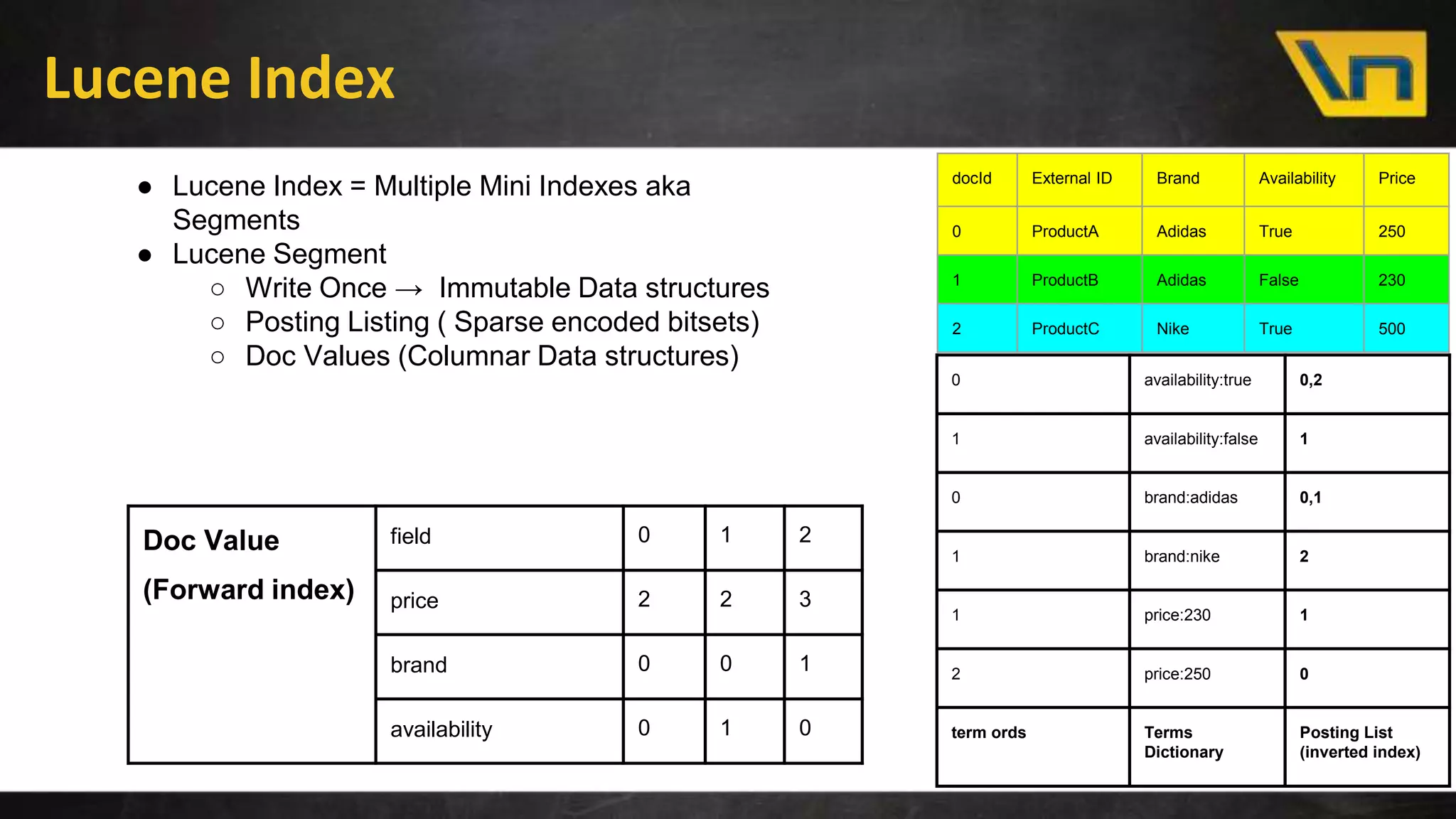




The document discusses the challenges of maintaining a real-time search index for e-commerce, highlighting issues like update rates and the limitations of Lucene in handling partial updates. It presents an approach to achieve near real-time indexing to improve query performance and user experience by addressing outdated availability and stale data. Additionally, it outlines the architecture and components of the proposed solution, including the use of solr, Kafka, and a near-real-time inverted store.



































































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)













