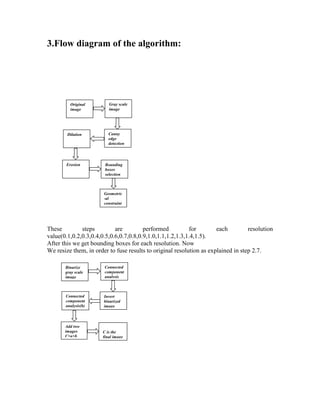
The document describes an algorithm for detecting text in camera-captured images. It begins with preprocessing steps like converting the color image to grayscale, applying edge detection and morphological operations like dilation and erosion. This gives initial bounding boxes containing candidate text regions. Further processing includes applying geometrical constraints to filter boxes, performing multiresolution analysis, connected component analysis and filtering by area to get the final text regions. Inversion and addition steps are used to handle text against different backgrounds.




![Abstract:
Text data in images contain useful information. In this paper, we present an approach to
detect text in color images. The proposed approach is based on combination of edge
detection, connected component analysis at multiple resolutions. First, we utilize an
image edge detection algorithm to extract all possible text edge pixels. Dilation by a
specific structuring element is performed on the edge map. The dilation is followed by
erosion by a specific structuring element. Following some geometrical constraints we get
initial bounding boxes containing text regions. Then connected component analysis is
performed on corresponding binarized image to recover whole text portions.Finally,
multiresolution approach is used to make the approach applicable for large range of font
sizes.
1. Introduction:
The retrieval of text information from color images has gained increasing attention in
recent years. Text appearing in images can provide very useful semantic information and
may be a good key to describe the image content. Text detection can be found in many
applications, such as road sign detection, map interpretation and engineering drawings
interpretations etc. Many papers about text detection from images have been
published[2,4,5,6,7]. Text detection generally can be classified into two categories:
Bottom-up methods: they segment images into regions and group character region into
words[1].
Due to the difficulty of developing efficient segmentation algorithm for text in
complex background, the methods are not robust for detecting text in many camera based
images.
Top-down methods: they first detect text regions in images using filters and then perform
bottom- up techniques inside the text regions[2]. These methods are able to process more
complex images than bottom–up approaches. Top down methods are also divided into
two categories:
Heuristic methods: they use heuristic filters
Machine learning methods: they use trained filters.
Shortcomings of many current methods include their inability to perform well in the
case of variant text orientation, size, language and low resolution image, where characters
may be touching.](https://image.slidesharecdn.com/samplepapertechscribe-100401122002-phpapp01/85/Sample-Paper-Techscribe-4-320.jpg)

![2.5 Computation of initial bounding boxes of the candidate text areas:
Now after erosion step we compute the bounding boxes containing the white pixel
portion of the image. Bounding boxes just contain the 8-connected white pixel
components inside them. We place bounding boxes on the corresponding color image.
So after this step we get the bounding boxes on the corresponding color image.
2.6 Applying geometrical constraints:
Now we discard some boxes on the following geometrical constraints:
1) Height is lower than a threshold (set to 12)
2) Height is greater than a threshold (set to 48)
3) Ratio of width to height is lower than a threshold (set to 1.5)
After this step we reduce number of bounding boxes.
2.7 Multiresolution analysis:
The whole algorithm till now is applied in a multiresolution fashion to ensure text
detection with size variability[9]. In other words the methodology described above is
applied to image in different scales and finally results are fused to initial resolution. The
size of the element for the morphological operations (dilation, erosion) and the
geometrical constraints give to the algorithm the ability to detect text in a specific range
of character sizes(12-48 pixels). To overcome this problem we adopt multiresolution
approach .The algorithm above is applied to the images in different resolutions and
finally the results are fused to initial resolution. In this way we get a set of bounding
boxes on the color image for each resolution. We took resolution range from 0.1 to 1.5 at
the gapping of 0.1.For example if we have resolution parameter m, then fusing results to
the original resolution means that, size of the resized bounding box(x coordinate, y
coordinate, width, height) will be (x coordinate/m, y coordinate/m, width/m, height/m).
Similarly we do this for all resolutions in the range, resize the bounding boxes and then
fuse them on original image.
2.8 Selection of final bounding boxes:
We discard a smaller bounding box, if it is inside the bigger one. This way we reduce
drastically the number of bounding boxes. And these bounding boxes constitute final
region of interest. The reason behind this step is that, by doing this we can benefit in
terms of running time. Because now we have less number of bounding boxes and that
means less object to deal with without missing any significant text regions.
2.9 Binarization:
Now we binarize the grayscale image to get the corresponding binarized image. We used
Otsu’s method to perform thresholding, or the reduction of a gray level image to a binary
image[3].](https://image.slidesharecdn.com/samplepapertechscribe-100401122002-phpapp01/85/Sample-Paper-Techscribe-6-320.jpg)




![Acknowledgement
This work has been done at the Computer Vision and Pattern Recognition Unit, Indian
Statistical Institute, Kolkata under direct supervision of Ujjwal Bhattacharya.
6.References:
[1] Rainer Lienhart and Frank Stuber, “Automatic text recognition in digital videos”,
Technical Report / Department for Mathematics and Computer Science, University of
Mannheim ; TR-1995-036
[2] Du, Yingzi, Chang, Chein-I Thouin, Paul D. “Automated system for text detection in
individual video Images”, Journal of Electronic Imaging, 12(3), 410 - 422. 2003.
[3] N.Otsu, "A Threshold Selection Method from Gray-Level Histogram," IEEE Trans.
Systems,
Man, and Cybernetics, vol. 9, pp. 62-66, 1979.
[4] C. Li, X. Ding, and Y. Wu, “Automatic text location in natural scene
images,” Proc. Sixth International Conference on Document Analysis and Recognition,
pp.1069–1073, Sept. 2001.
[5] K. In Kim, K. Jung, and J. Hyung, “Texture-based approach for text detection in
images using support vector machines and continuously adaptive mean shift algorithm,”
IEEE Trans. Pattern Anal. Mach.Intell., vol.25, no.12, pp.1631
1639, Dec. 2003.
[6] X. Tang, X. Gao, J. Liu, and H. Zhang, “A spatial-temporal approach for video
caption detection and recognition,” IEEE Trans. Neural Netw., vol.13, no.4, pp.961–971,
July 2002.
[7] O. Hori and T. Mita, “A robust video text extraction method for
character recognition,” IEICE Trans. Inf. & Syst. (Japanese Edition),
vol.J84-D-II, no.8, pp.1800–1808, Aug. 2001.
[8] Yangxing LIU, Satoshi GOTO, Takeshi IKENAGA
“A Contour-Based Robust Algorithm for TextDetection in Color
Images”
IEICE TRANS. INF. & SYST., VOL.E89–D, NO.3 MARCH 2006
[9] M. Anthimopoulos, M. Gatos, I. Pratikakis "Multiresolution text detection in video
frames“, Second international conference on computer vision theory and applications
(VISAPP).Barcelona, Spain March 8-11, 2007](https://image.slidesharecdn.com/samplepapertechscribe-100401122002-phpapp01/85/Sample-Paper-Techscribe-12-320.jpg)














































