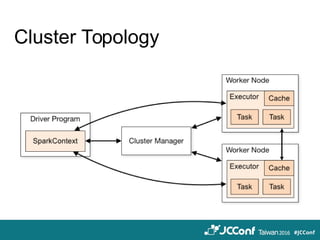
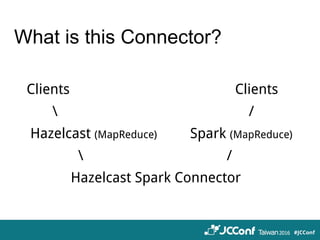
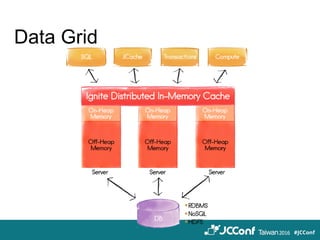
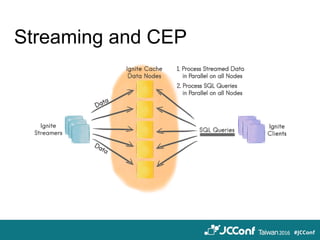
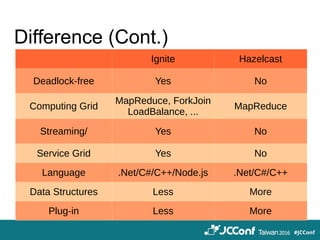
The document provides an overview of cloud computing technologies focused on Hazelcast, Spark, and Ignite, detailing their features, applications, and integration strategies. It explains Hazelcast as an in-memory data grid supporting distributed data caching and computation, while Spark is presented as a fast general-purpose cluster computing system, and Ignite is described as an in-memory data fabric for real-time data processing. The document also includes code examples, dependencies for integration, and comparisons between Hazelcast and Ignite regarding their functionalities and performance.






















![Sample Code
public class GetStartedMain {
public static void main(final String[] args) {
Config cfg = new Config();
HazelcastInstance instance =
Hazelcast.newHazelcastInstance(cfg);
Map<Long, String> map = instance.getMap("test");
map.put(1L, "Demo");
System.our.println(map.get(1L));
}
}](https://image.slidesharecdn.com/jcconf2016hazelcastandspark-161016104229/85/JCConf-2016-Cloud-Computing-Applications-Hazelcast-Spark-and-Ignite-23-320.jpg)
























































































![[OracleCode SF] In memory analytics with apache spark and hazelcast](https://cdn.slidesharecdn.com/ss_thumbnails/in-memoryanalyticswithapachesparkandhazelcast-oraclecode-03-01-2017-170302180618-thumbnail.jpg?width=640&height=640&fit=bounds)















































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)










