Download as PDF, PPTX











![© 2017 Mesosphere, Inc. All Rights Reserved.
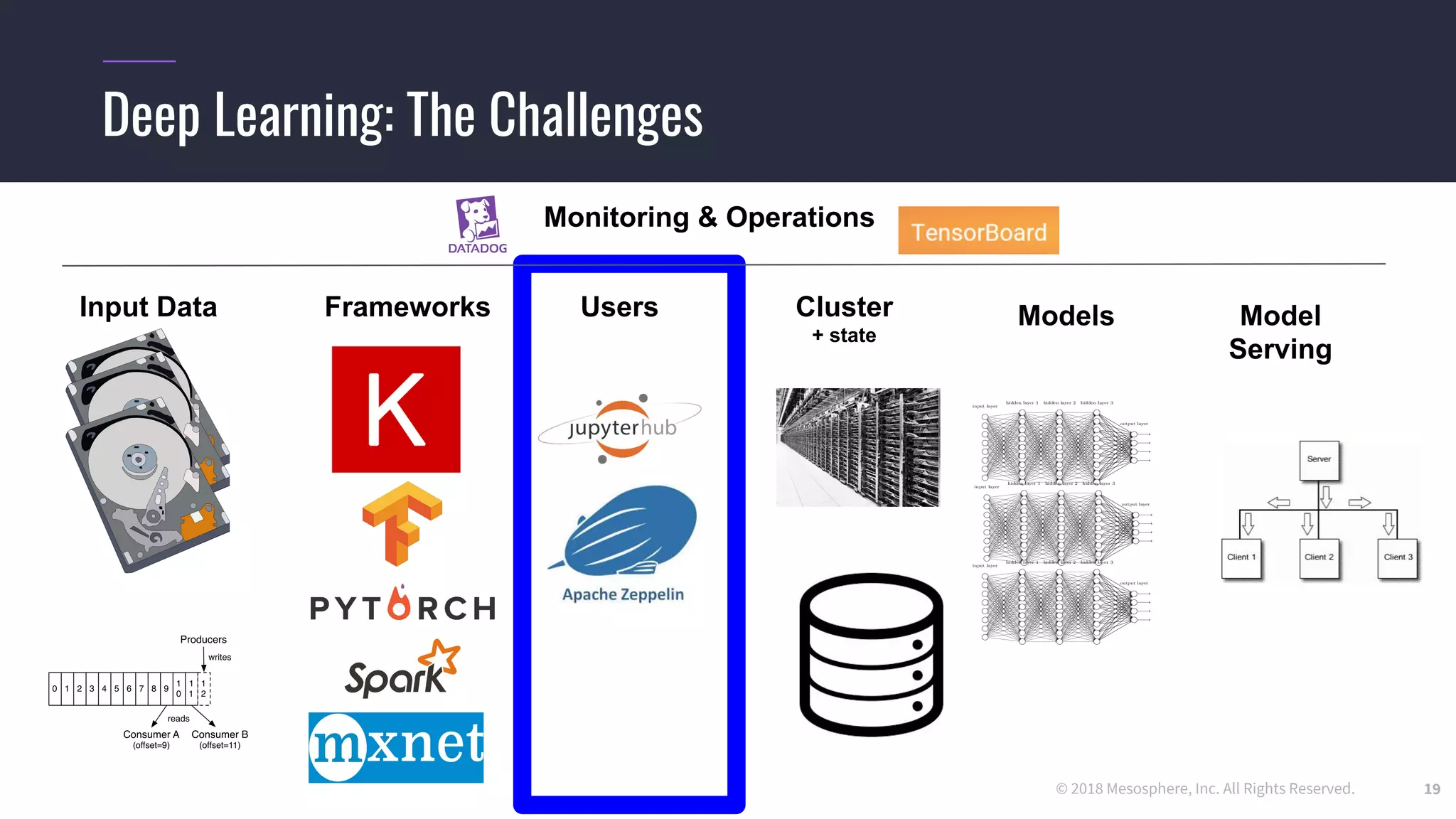
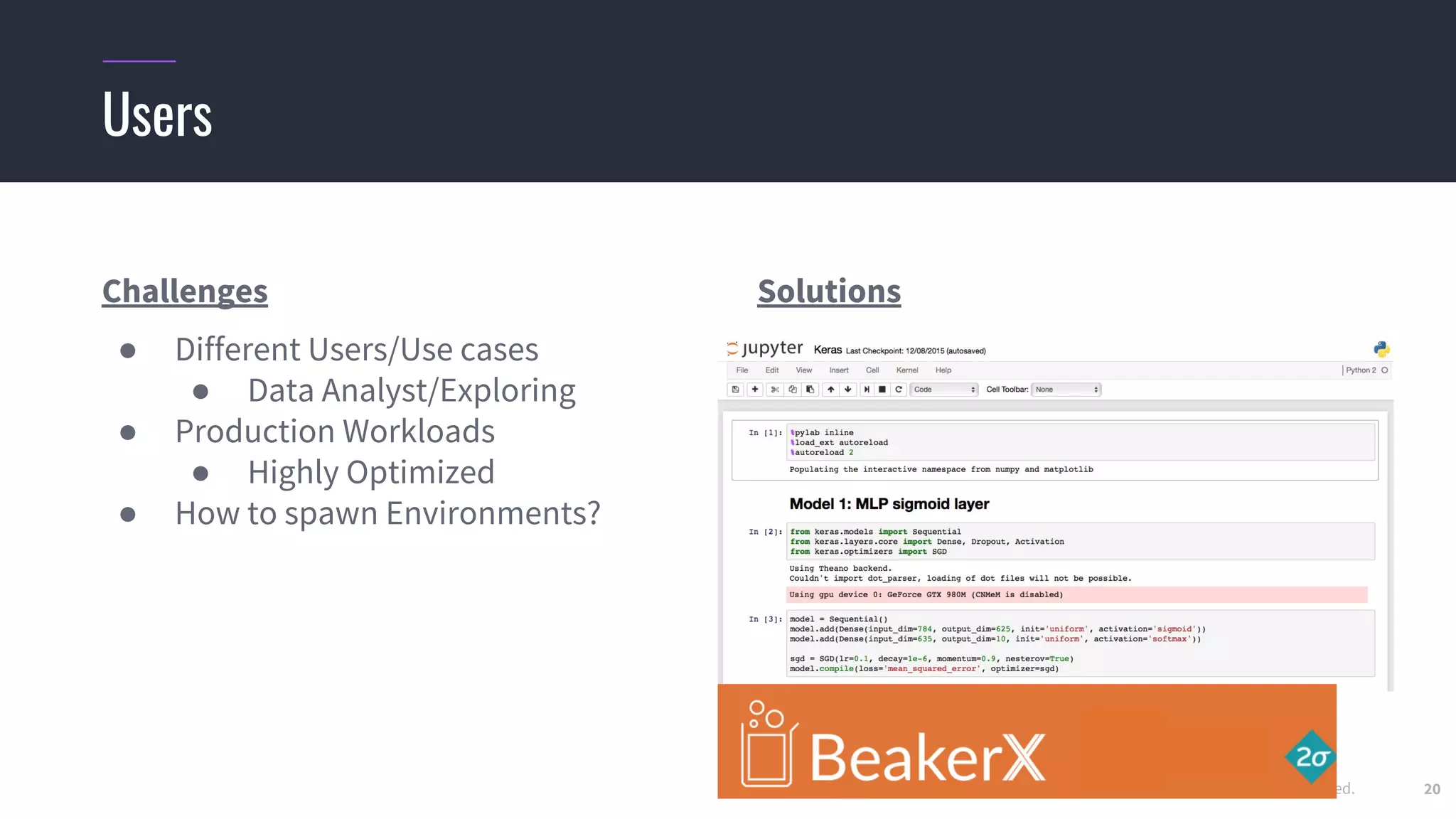
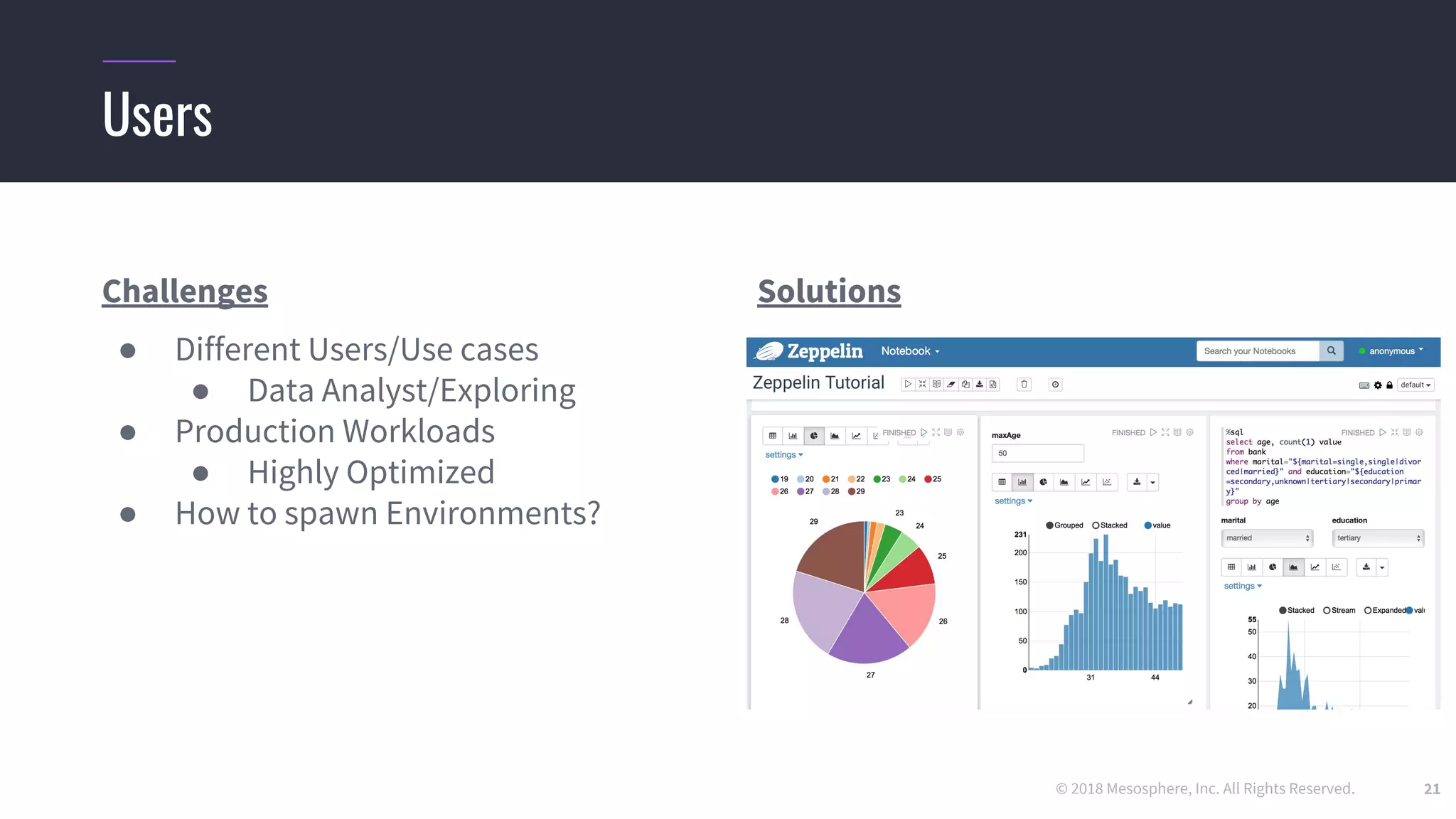
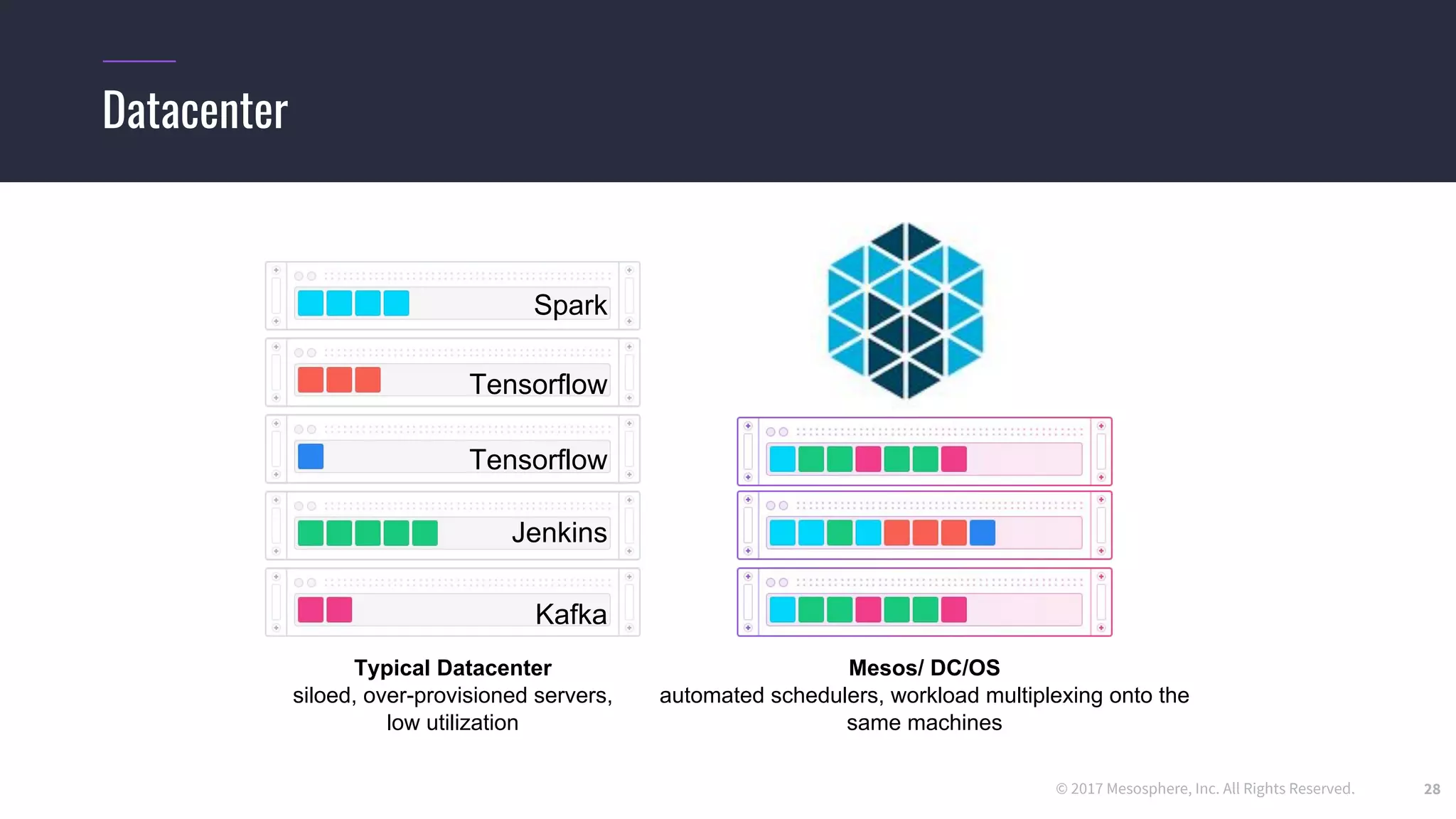
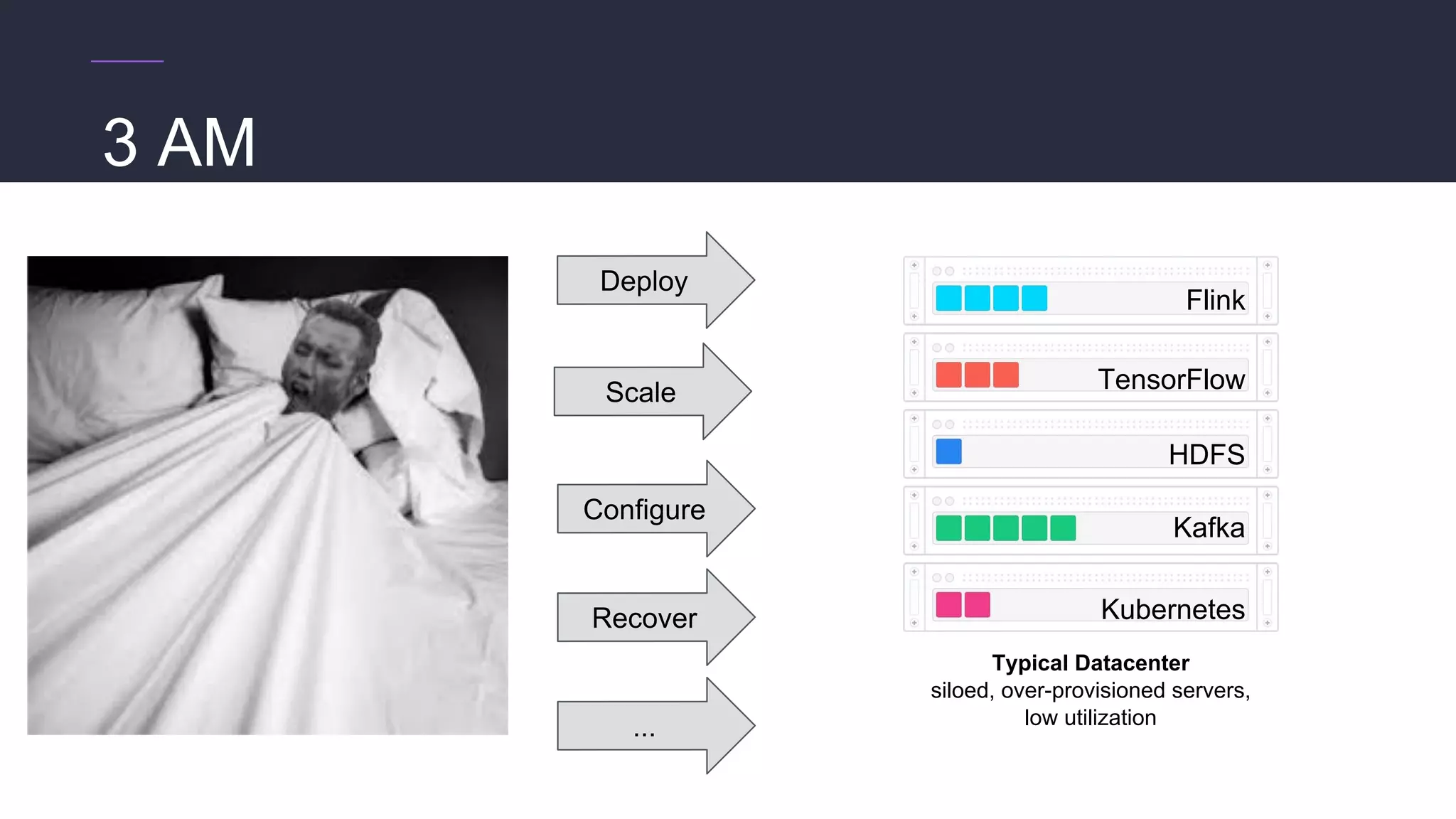
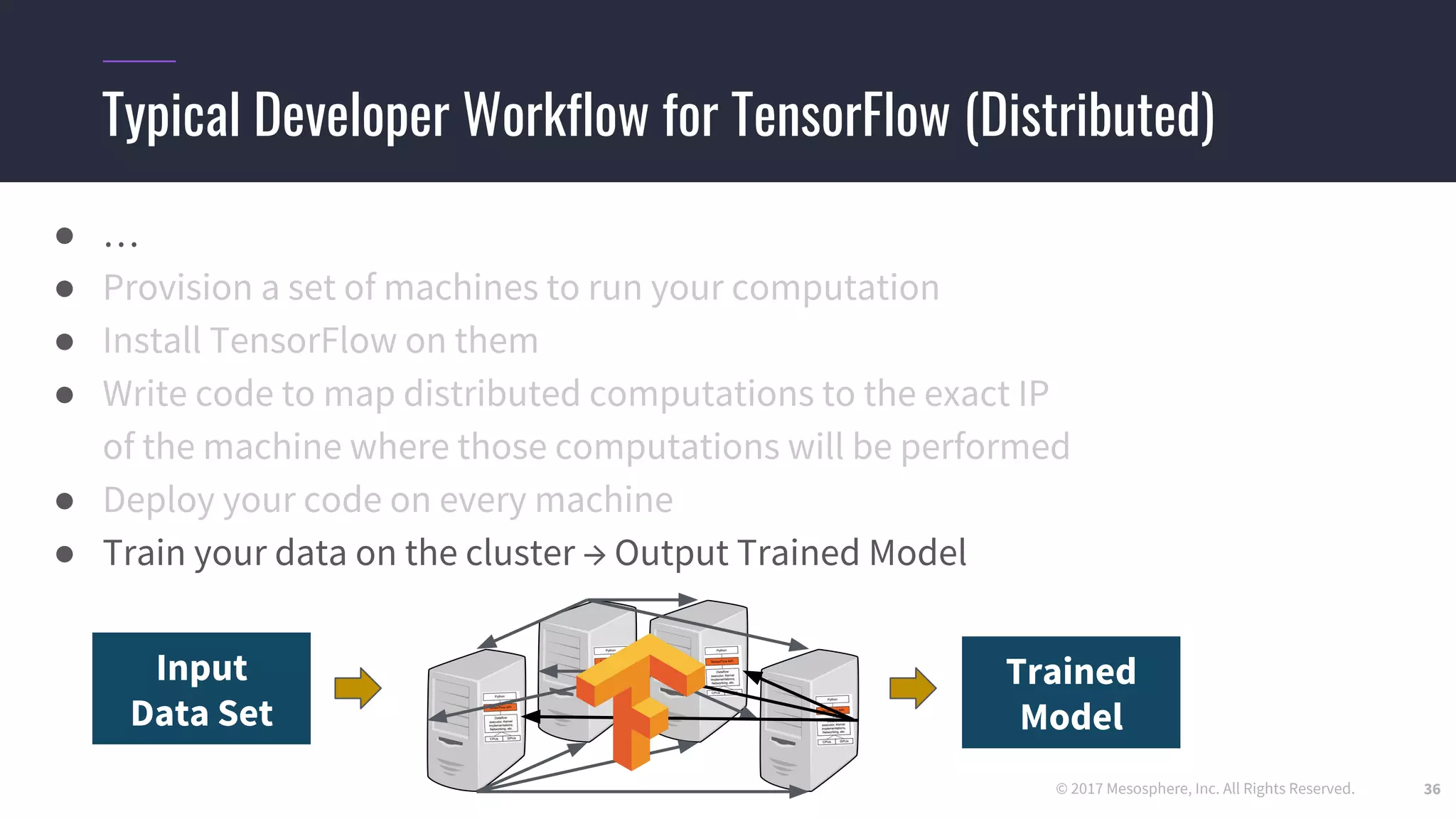
Challenges running distributed TensorFlow
34
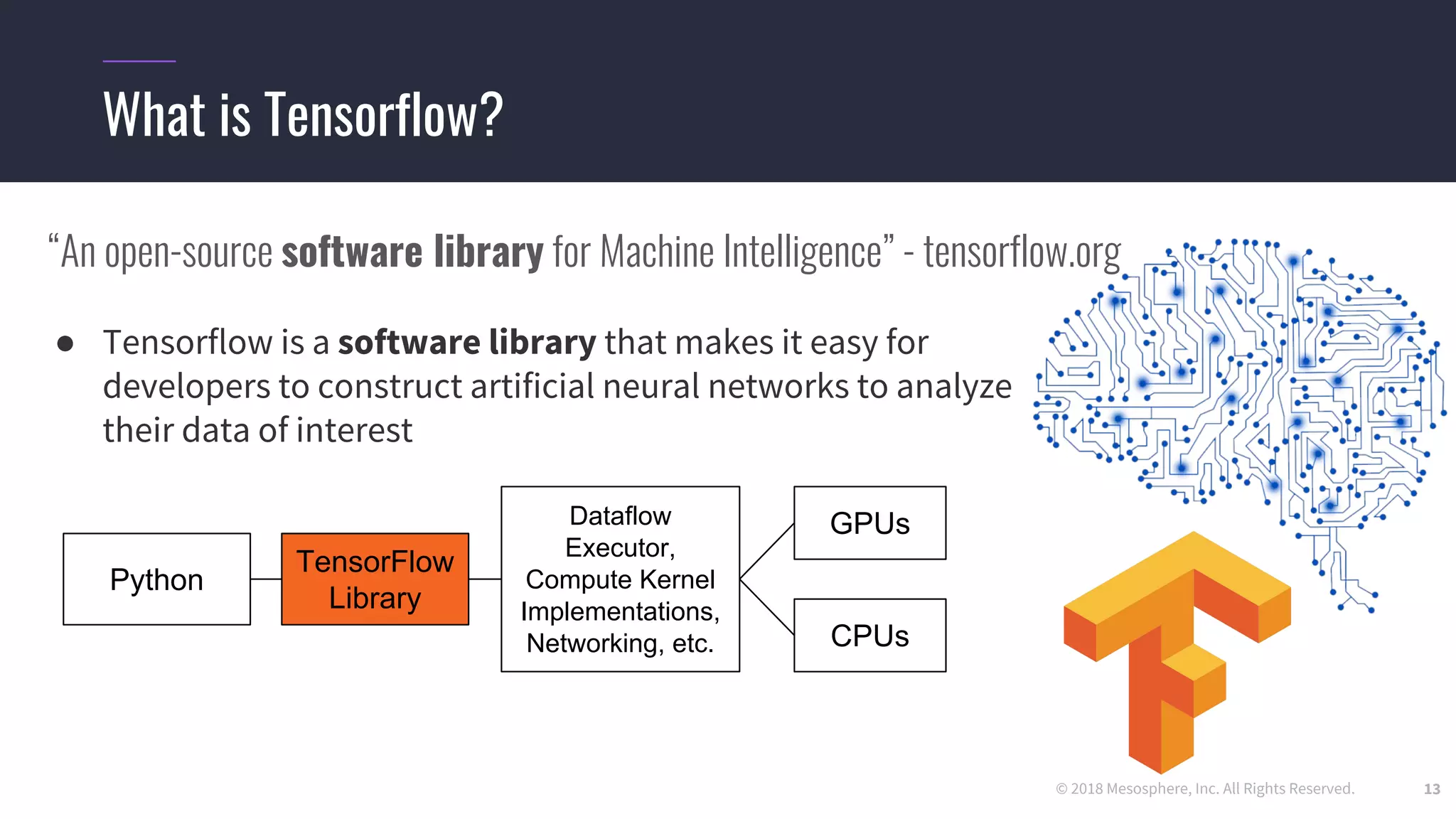
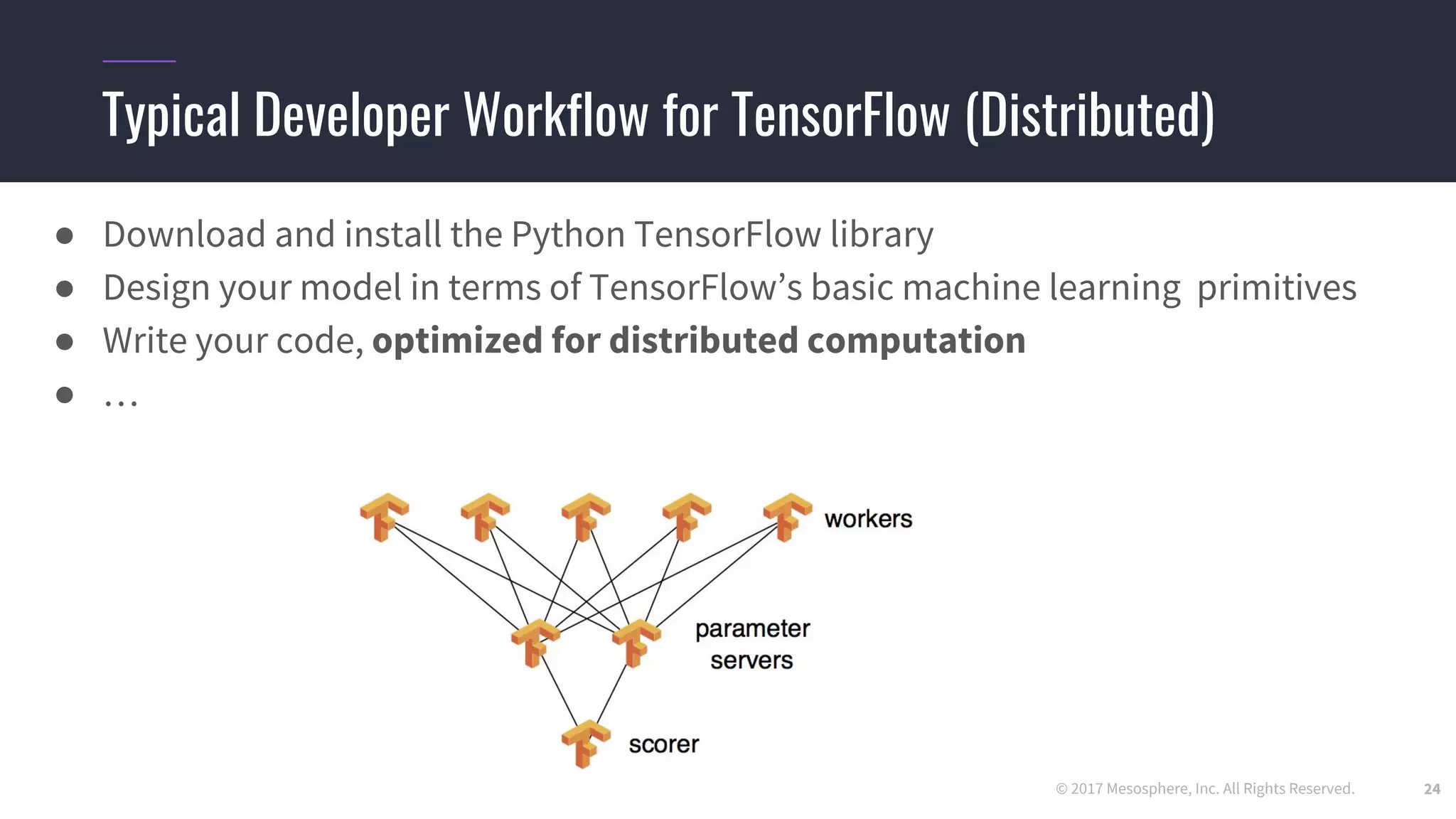
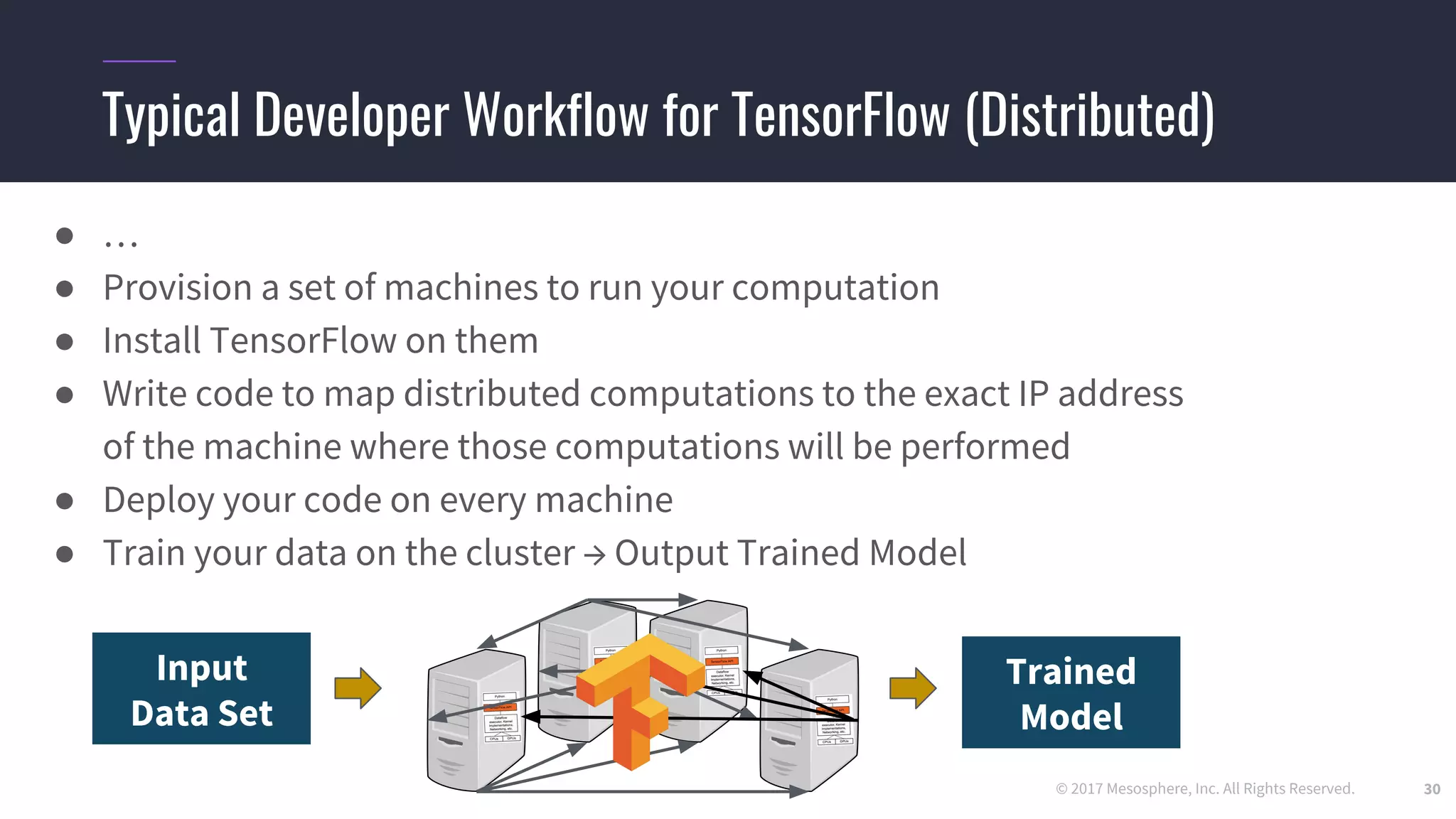
● Hard-coding a “ClusterSpec” is incredibly tedious
○ Users need to rewrite code for every job they want to run in a distributed setting
○ True even for code they “inherit” from standard models
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222",
"worker1.example.com:2222",
"worker2.example.com:2222",
"worker3.example.com:2222",
"worker4.example.com:2222",
"worker5.example.com:2222",
...
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222",
"ps2.example.com:2222",
"ps3.example.com:2222",
...
]})
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222",
"worker1.example.com:2222",
"worker2.example.com:2222",
"worker3.example.com:2222",
"worker4.example.com:2222",
"worker5.example.com:2222",
...
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222",
"ps2.example.com:2222",
"ps3.example.com:2222",
...
]})
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222",
"worker1.example.com:2222",
"worker2.example.com:2222",
"worker3.example.com:2222",
"worker4.example.com:2222",
"worker5.example.com:2222",
...
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222",
"ps2.example.com:2222",
"ps3.example.com:2222](https://image.slidesharecdn.com/schad-codemotionrome-endtoendmachinelearning-180709072601/75/Deep-learning-beyond-the-learning-Jorg-Schad-Codemotion-Rome-2018-34-2048.jpg)

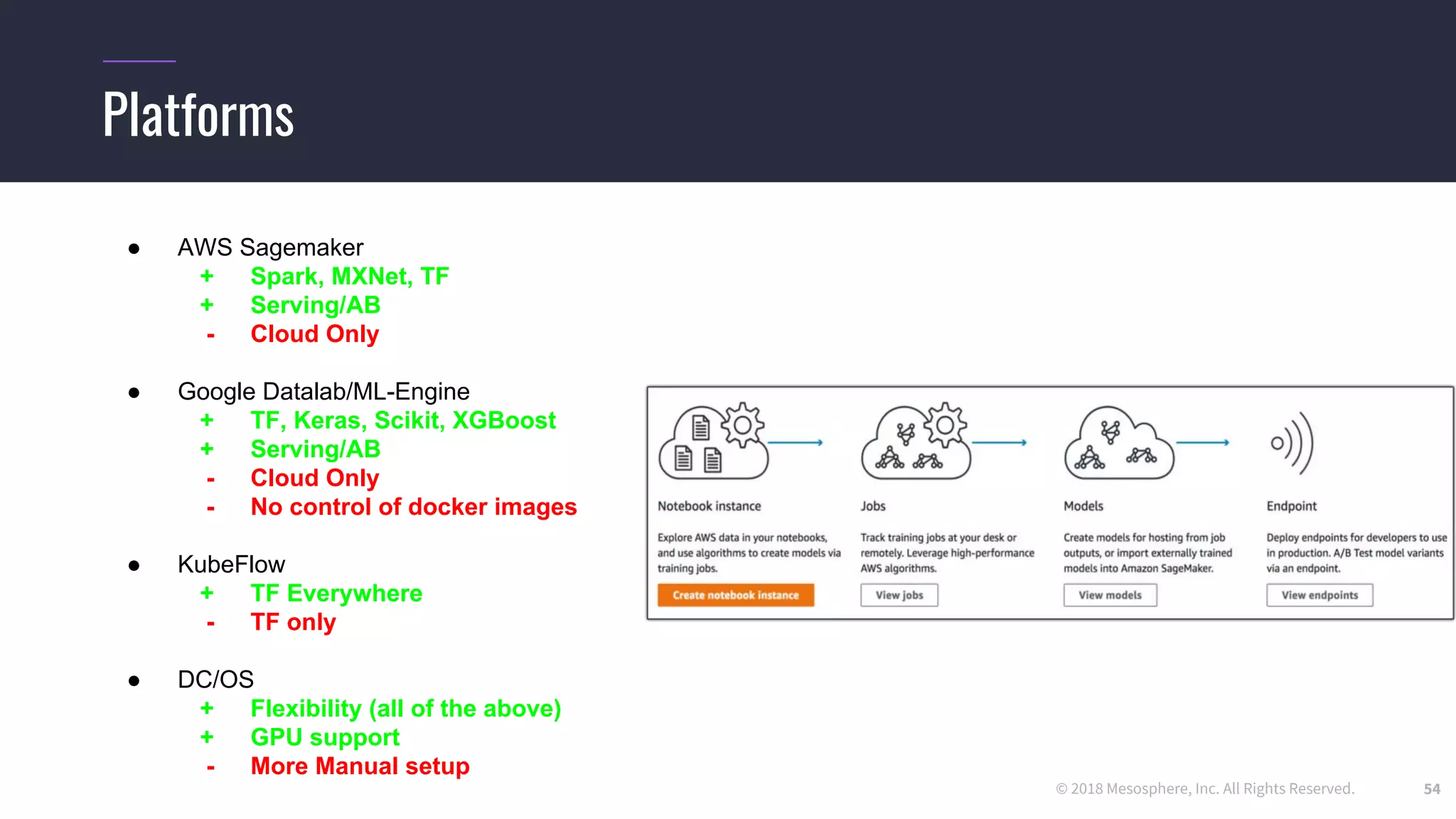
![© 2017 Mesosphere, Inc. All Rights Reserved.
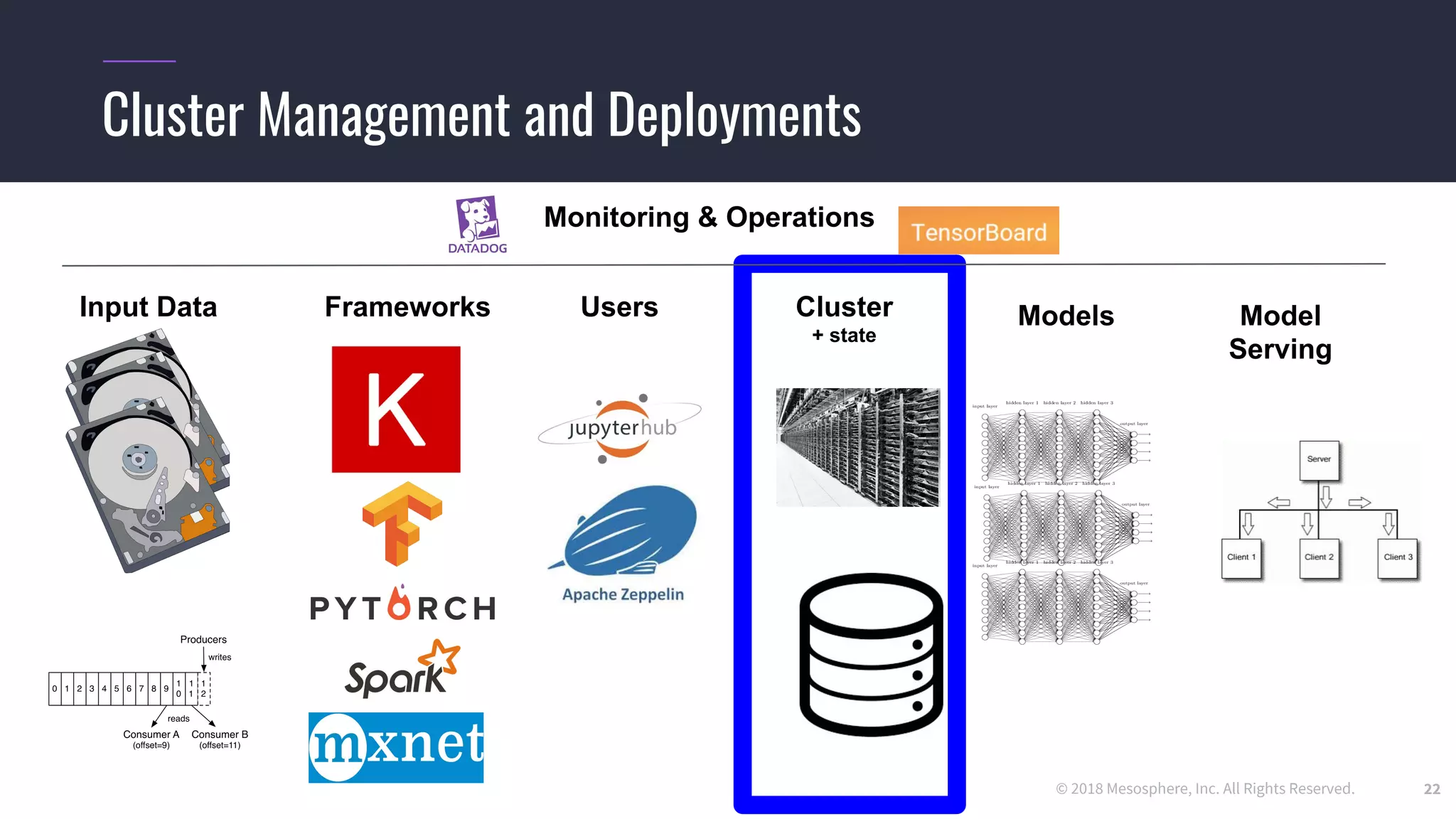
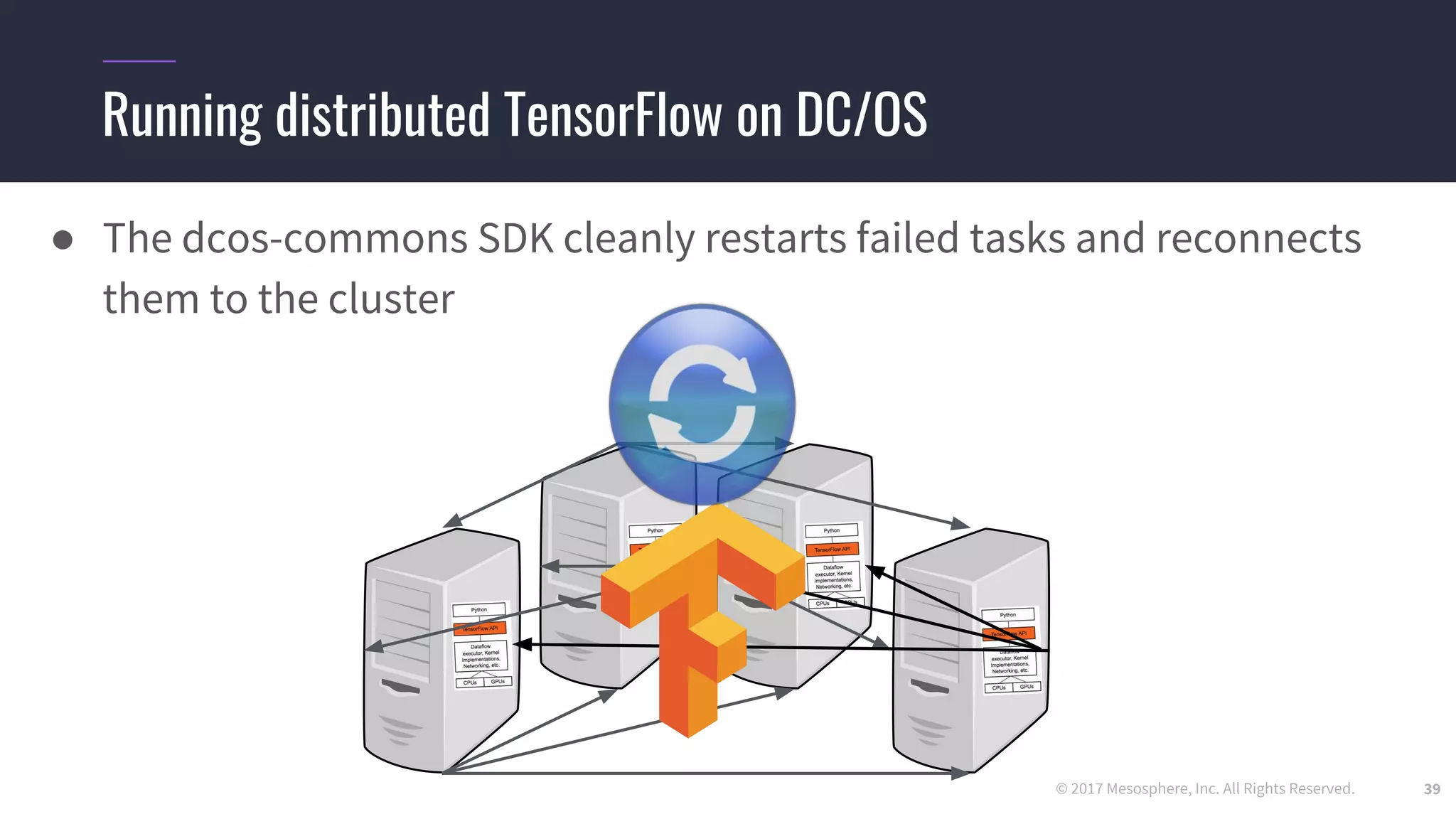
Running distributed TensorFlow on DC/OS
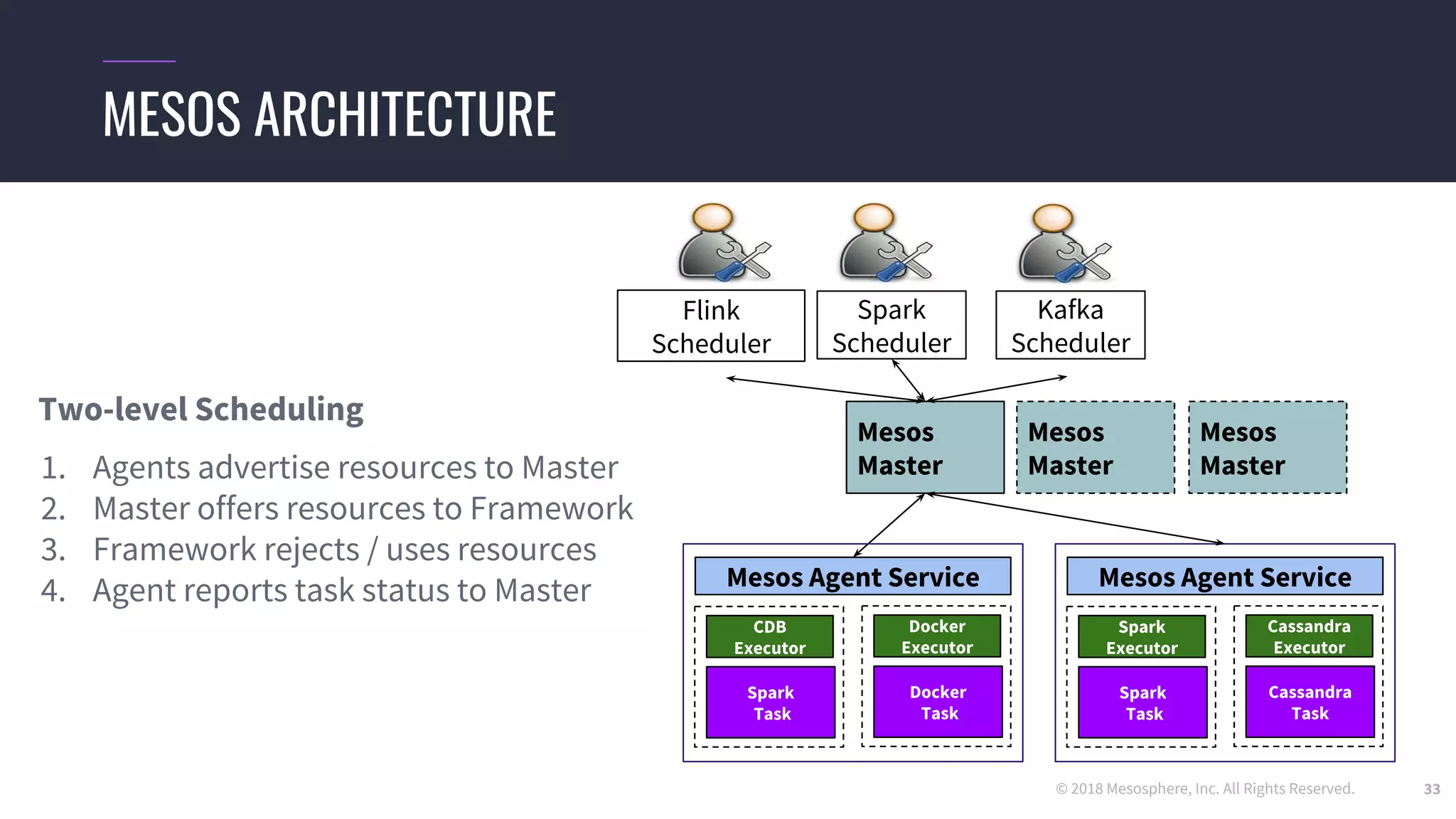
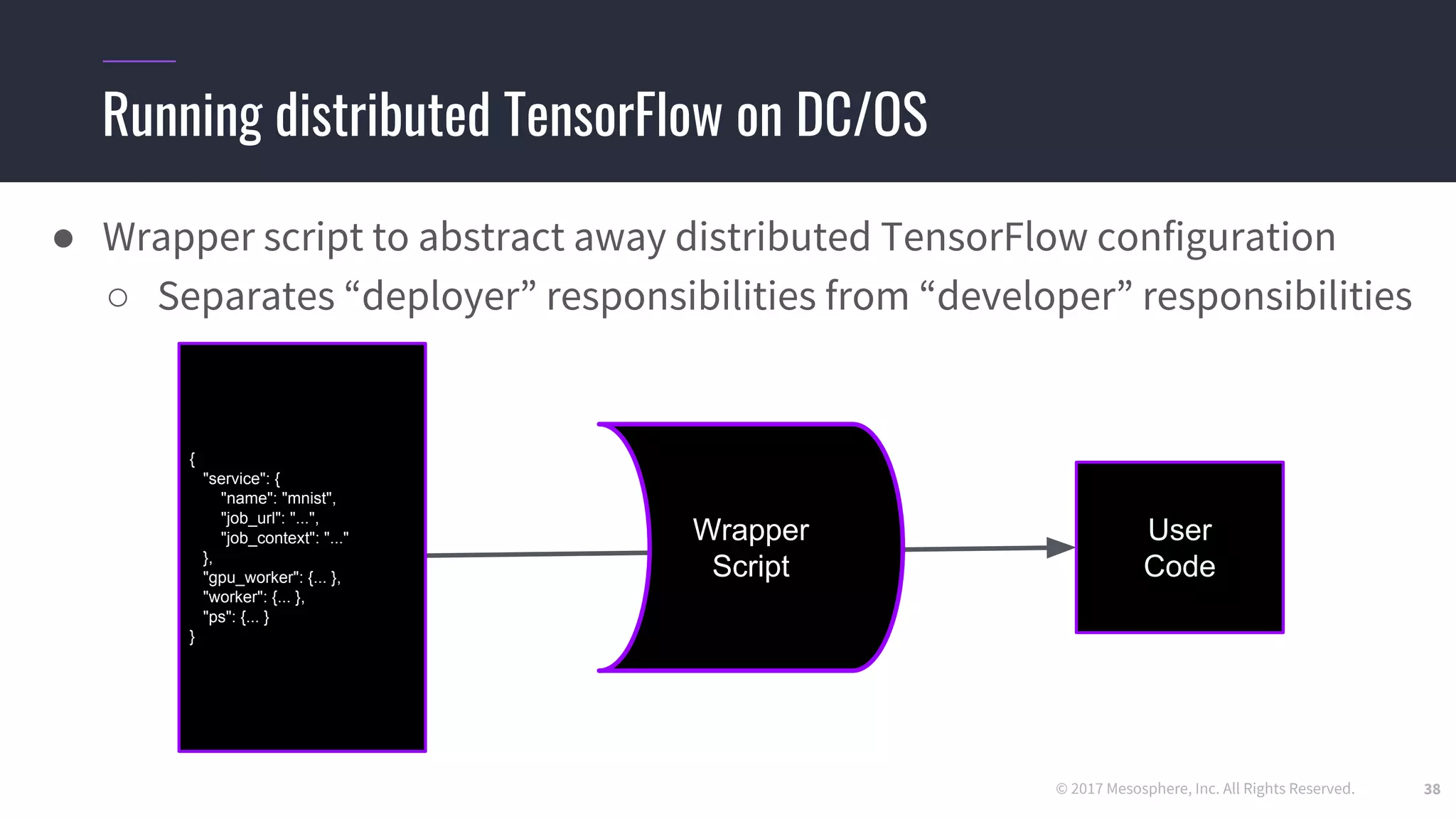
● We use the dcos-commons SDK to dynamically create the ClusterSpec
37
{
"service": {
"name": "mnist",
"job_url": "...",
"job_context": "..."
},
"gpu_worker": {... },
"worker": {... },
"ps": {... }
}
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222",
"worker1.example.com:2222",
"worker2.example.com:2222",
"worker3.example.com:2222",
"worker4.example.com:2222",
"worker5.example.com:2222",
...
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222",
"ps2.example.com:2222",
"ps3.example.com:2222",
...
]})
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222",
"worker1.example.com:2222",
"worker2.example.com:2222",
"worker3.example.com:2222",
"worker4.example.com:2222",
"worker5.example.com:2222",
...
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222",
"ps2.example.com:2222",
"ps3.example.com:2222",
...
]})
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222",
"worker1.example.com:2222",
"worker2.example.com:2222",
"worker3.example.com:2222",
"worker4.example.com:2222",
"worker5.example.com:2222",
...
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222",
"ps2.example.com:2222",
"ps3.example.com:2222](https://image.slidesharecdn.com/schad-codemotionrome-endtoendmachinelearning-180709072601/75/Deep-learning-beyond-the-learning-Jorg-Schad-Codemotion-Rome-2018-37-2048.jpg)
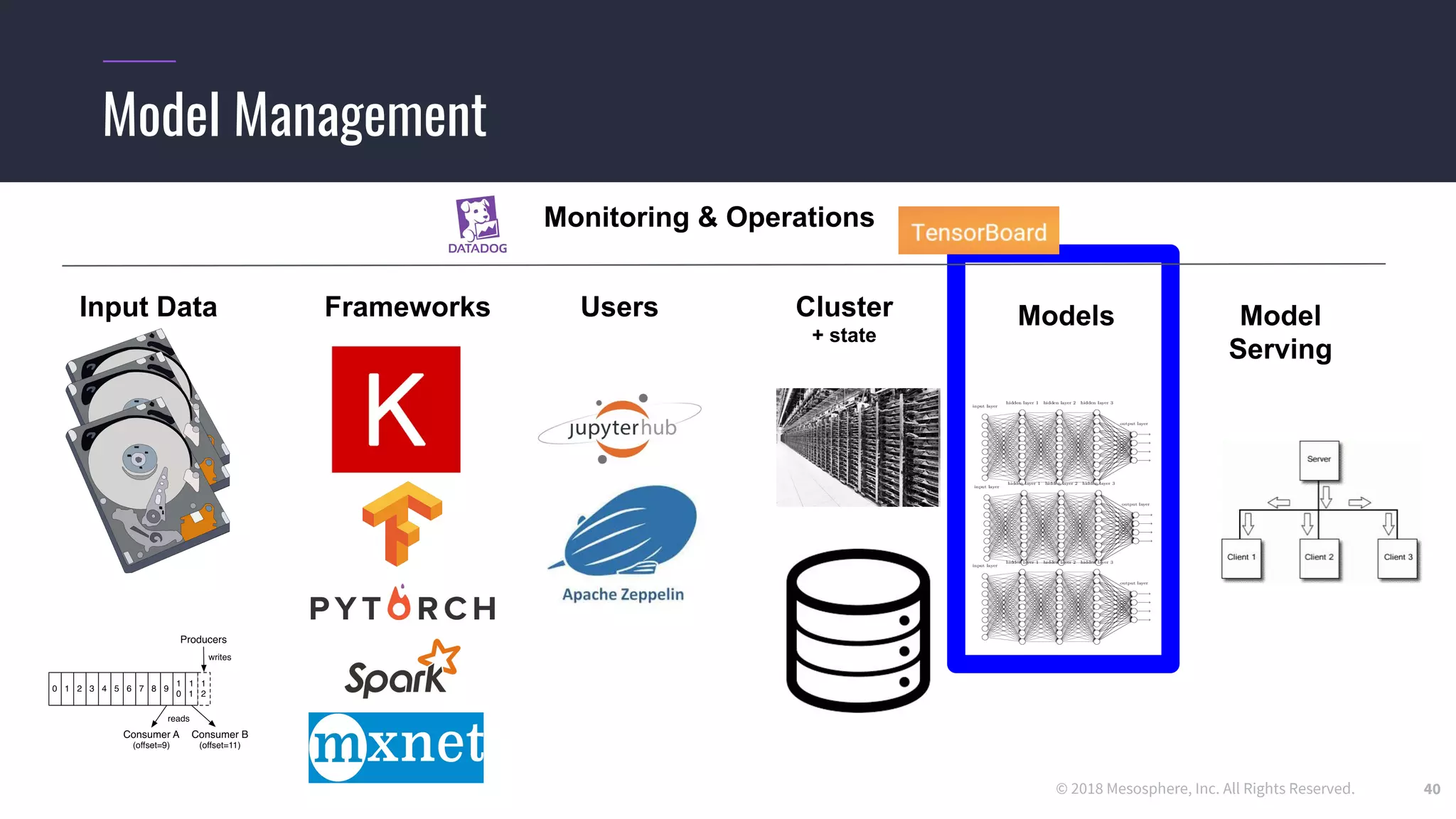
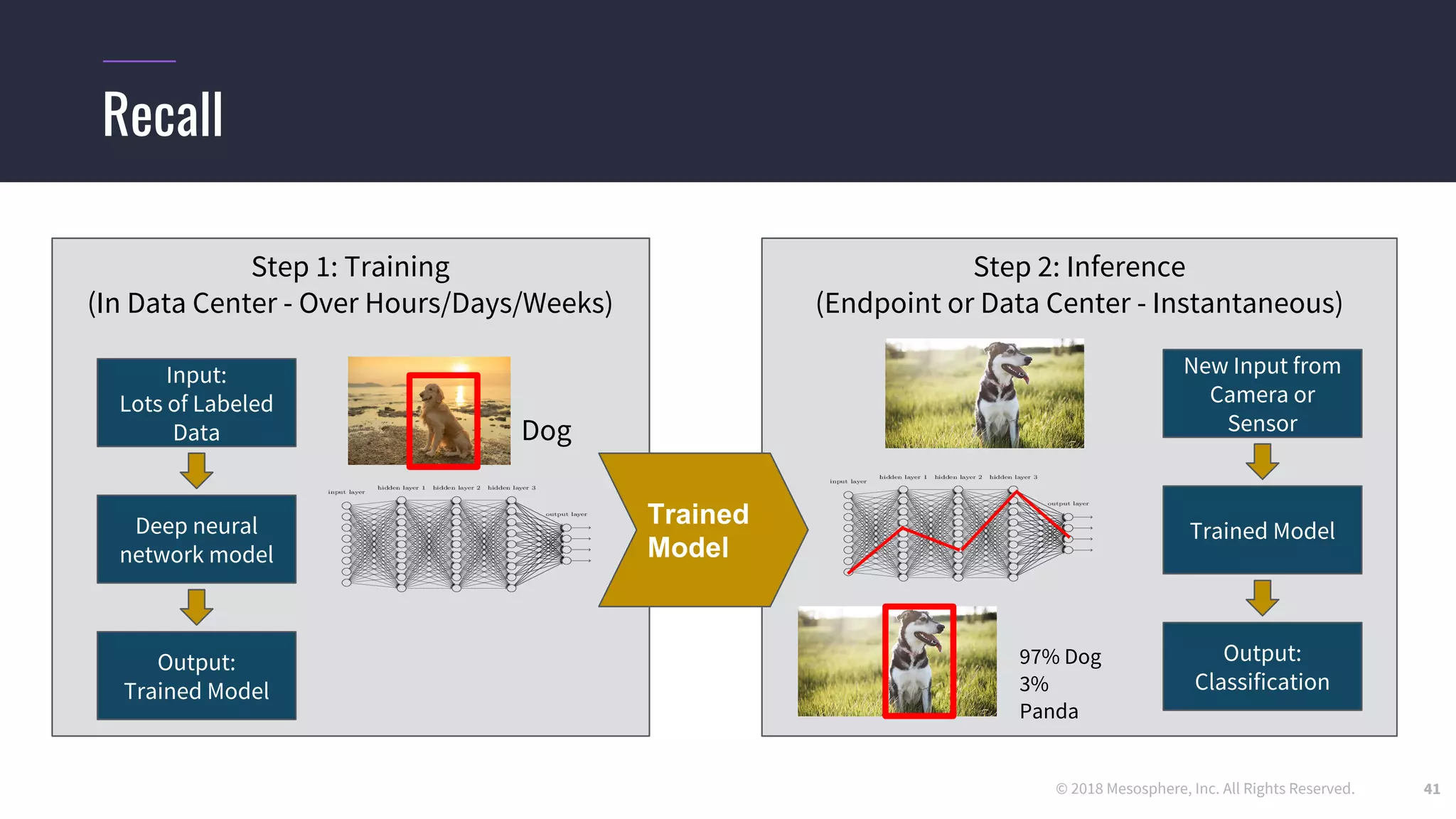
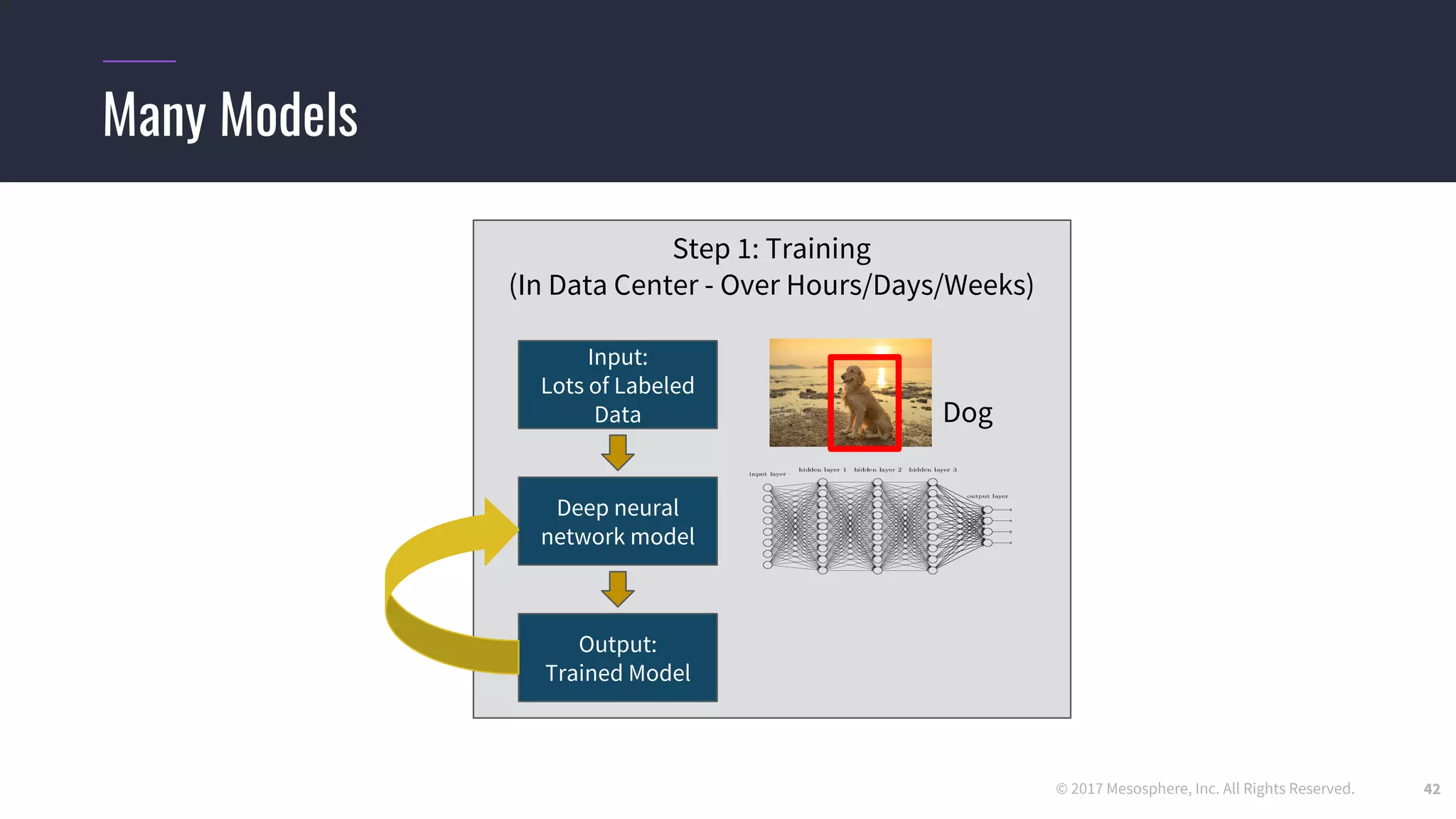

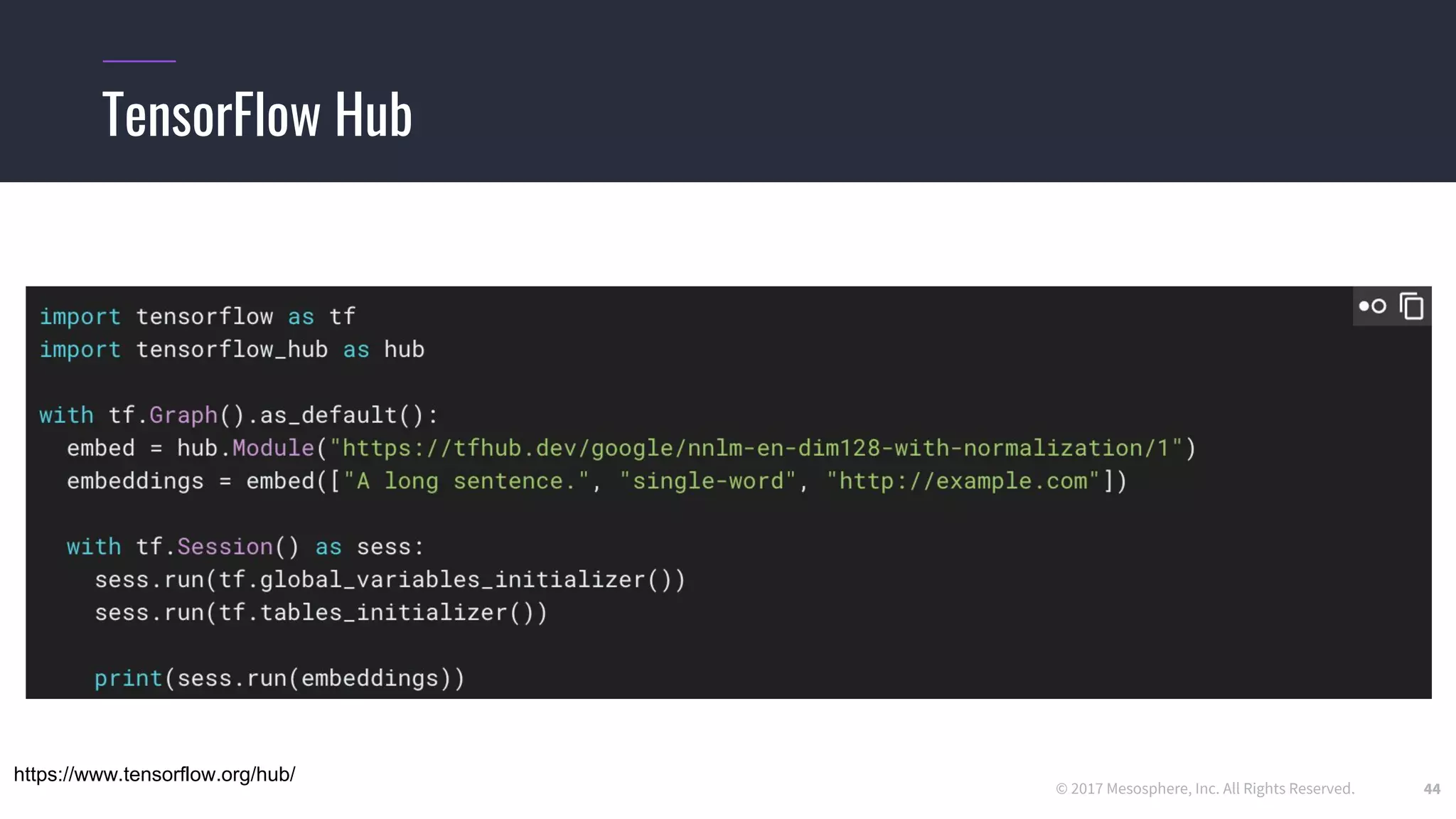
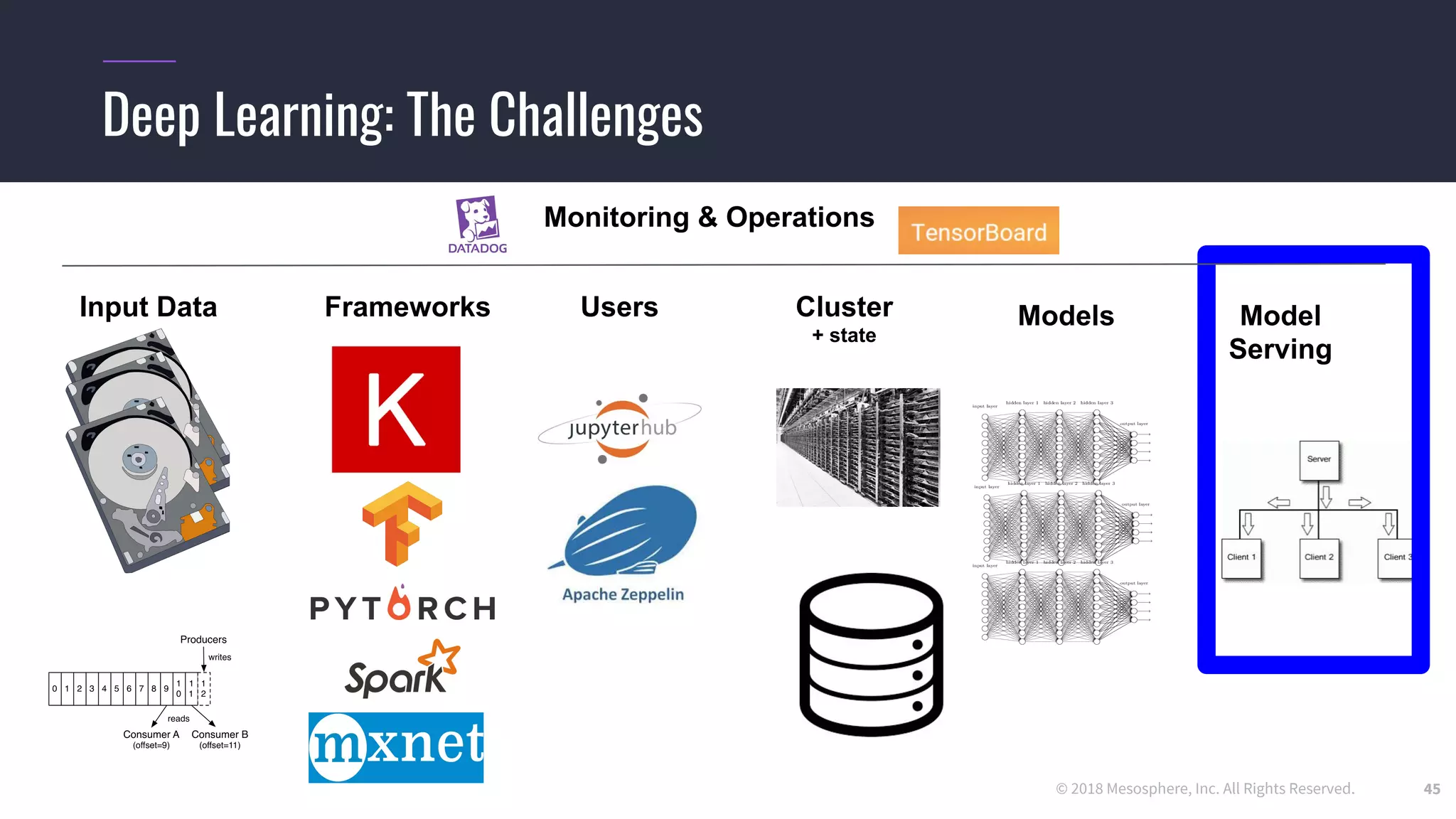
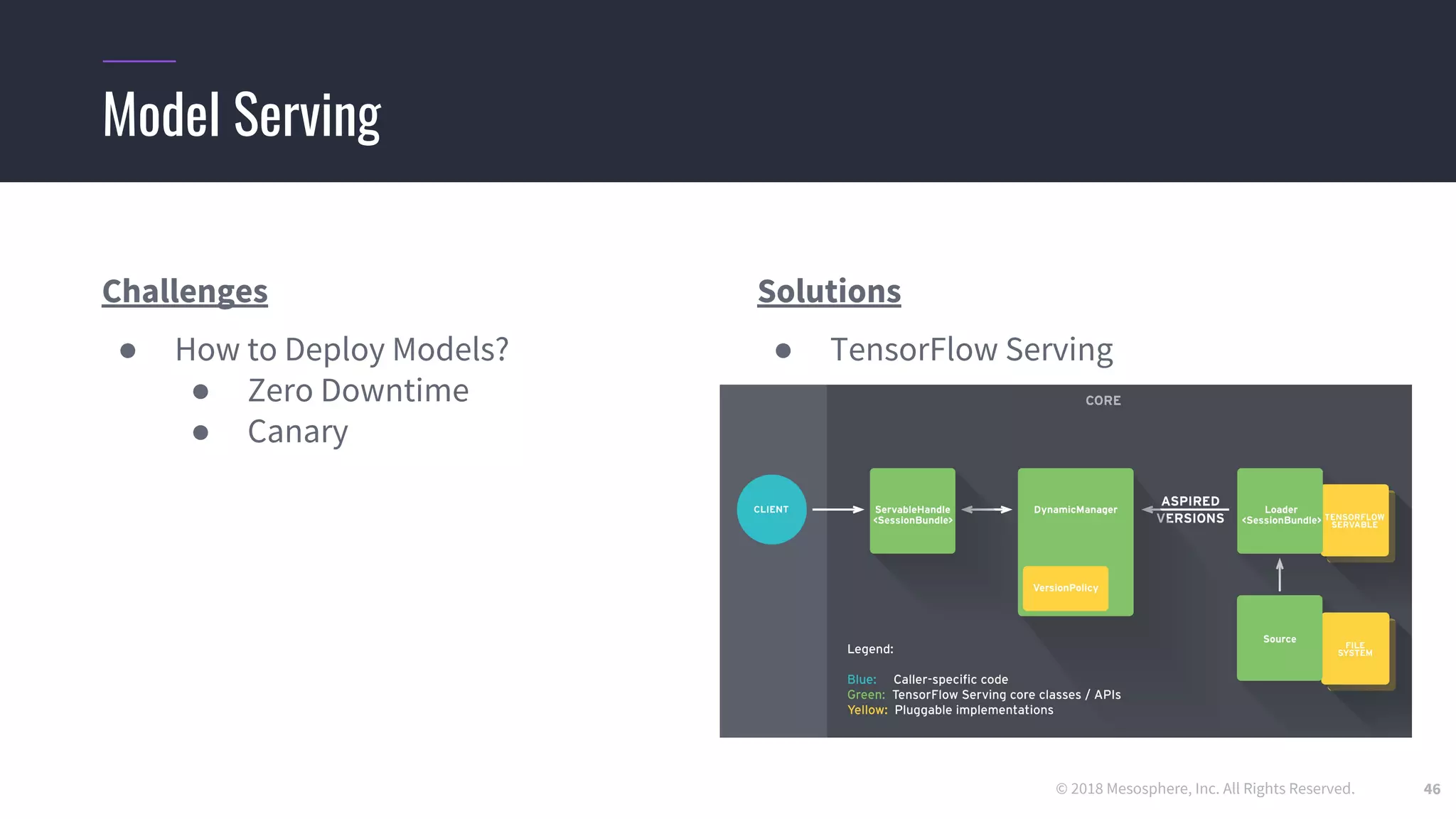

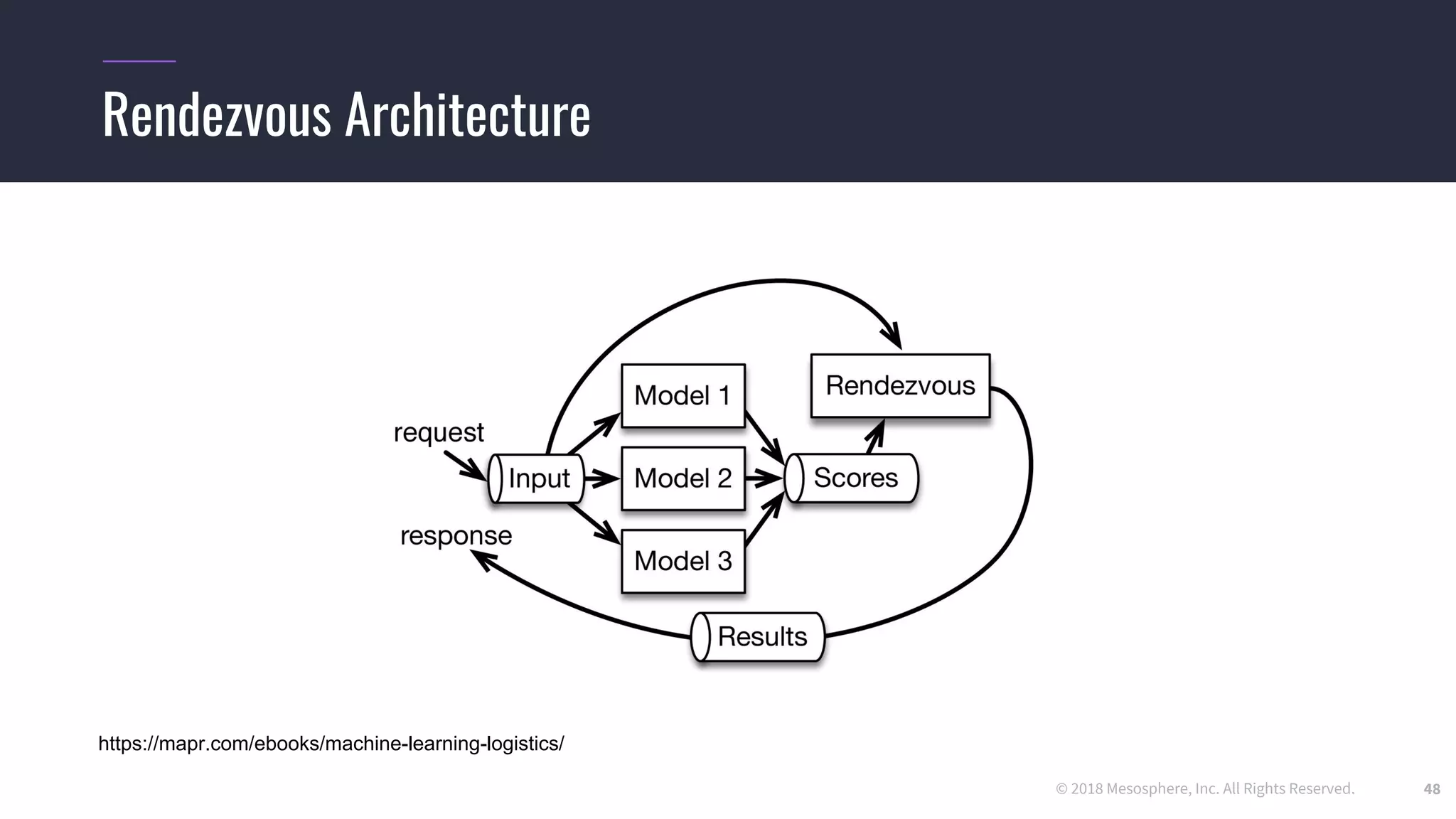
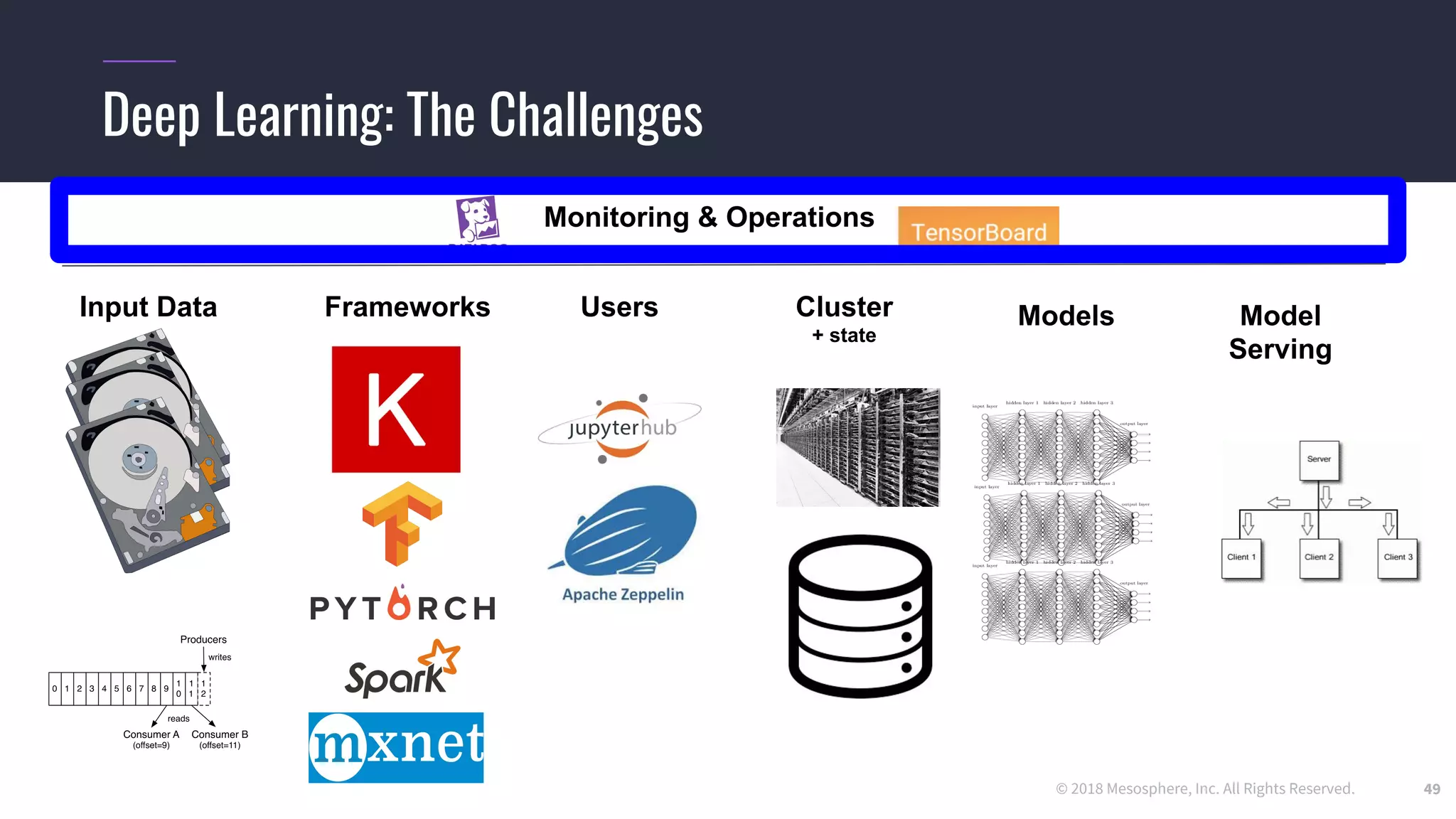

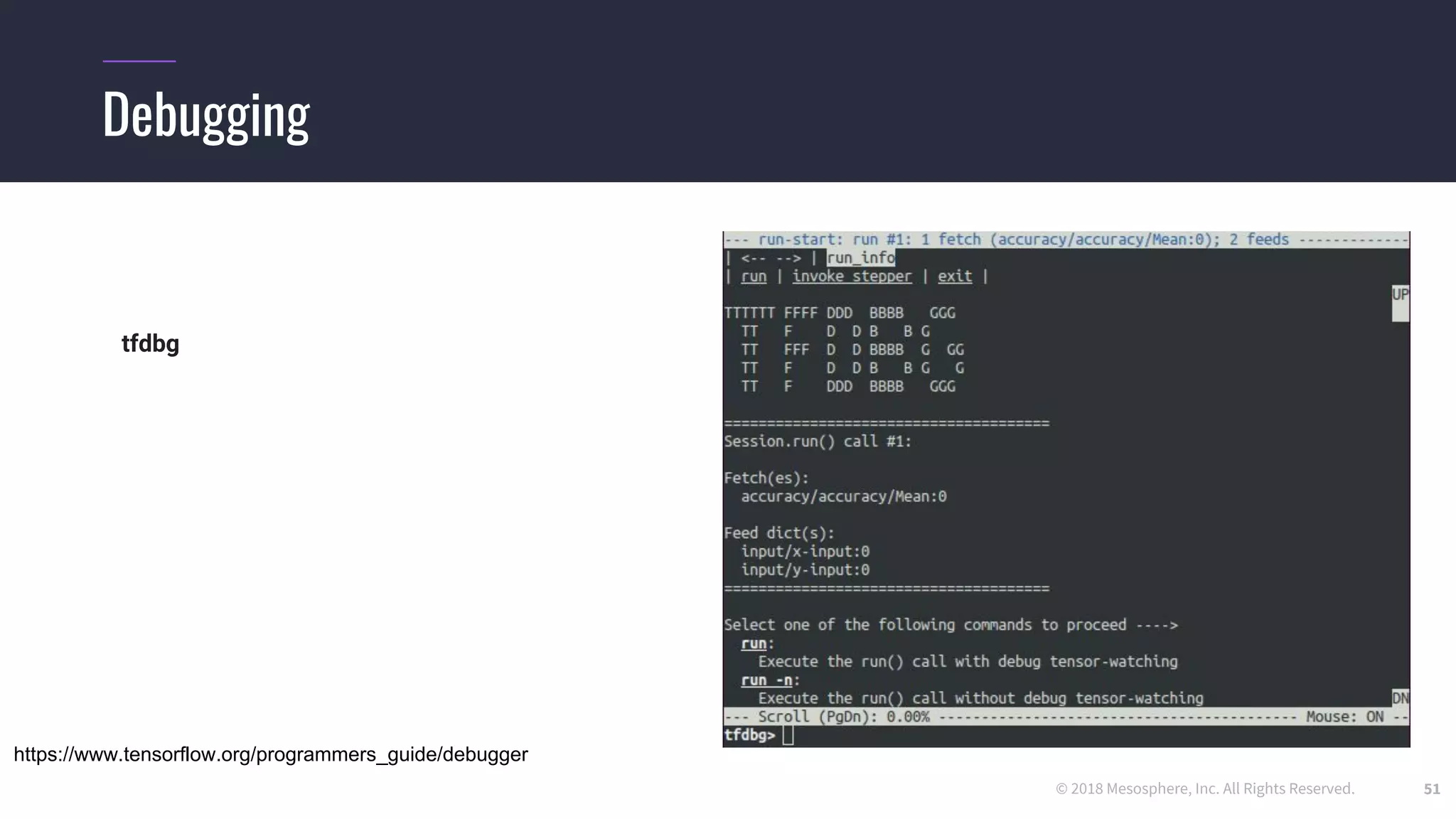
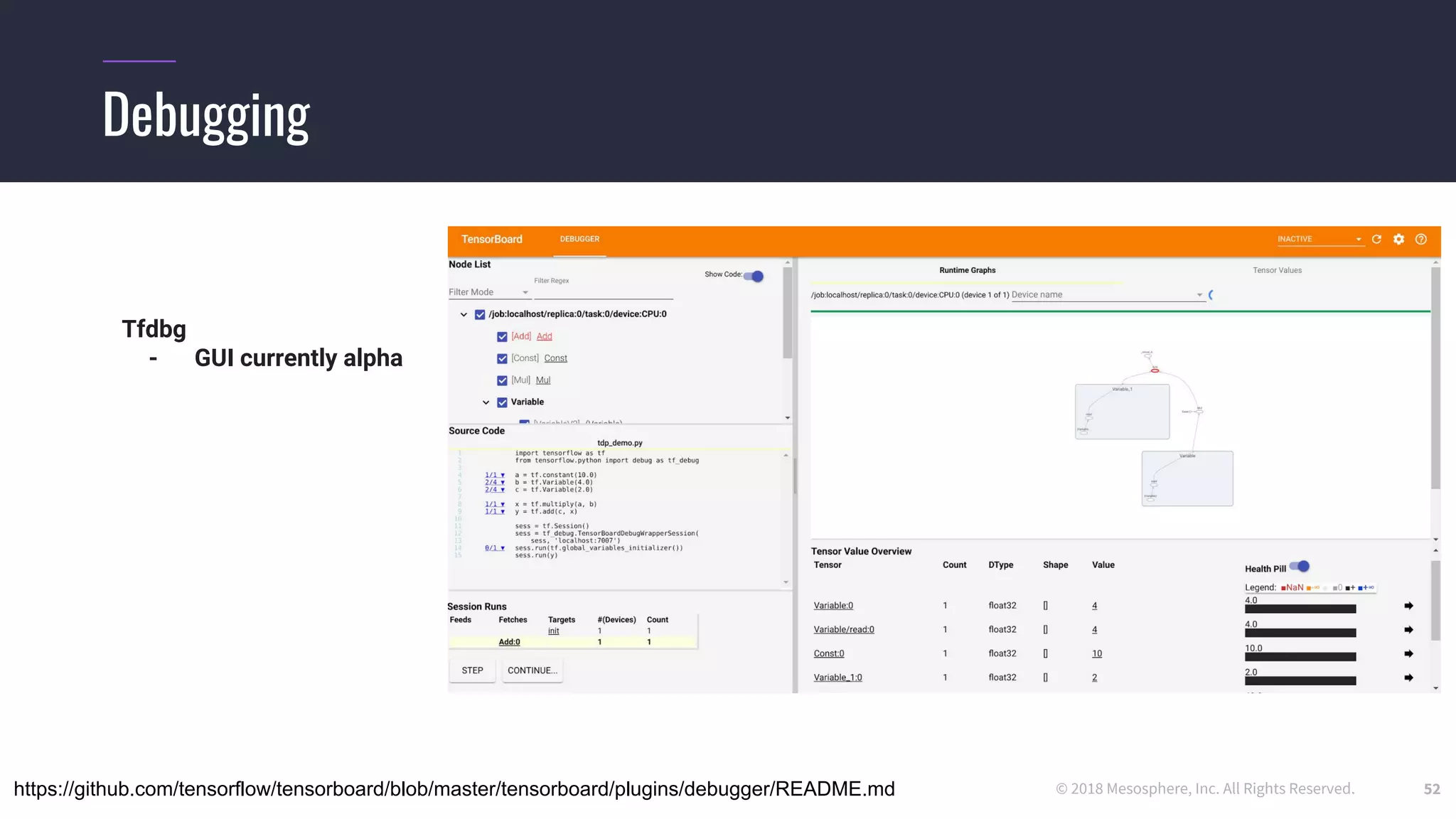
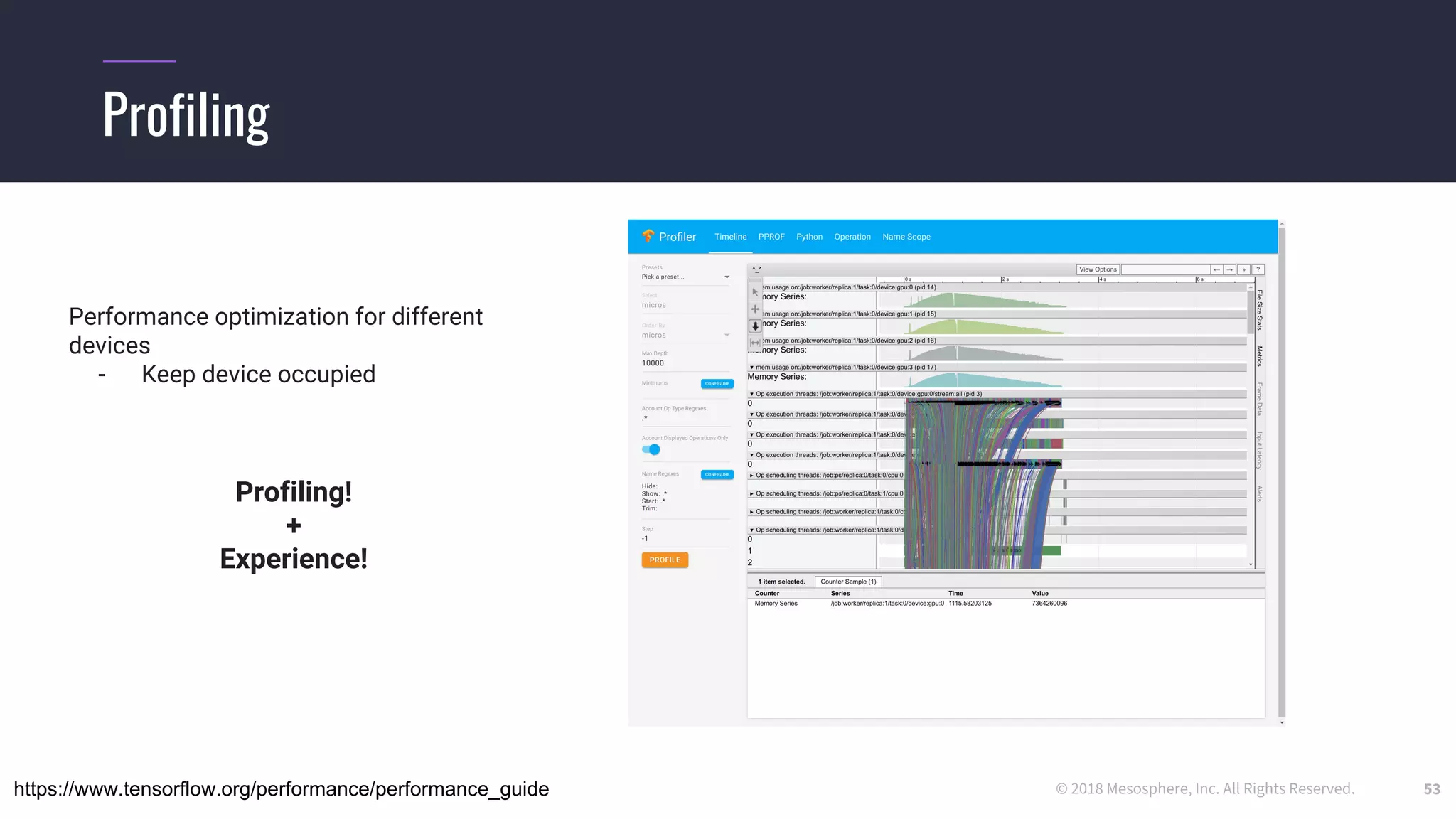





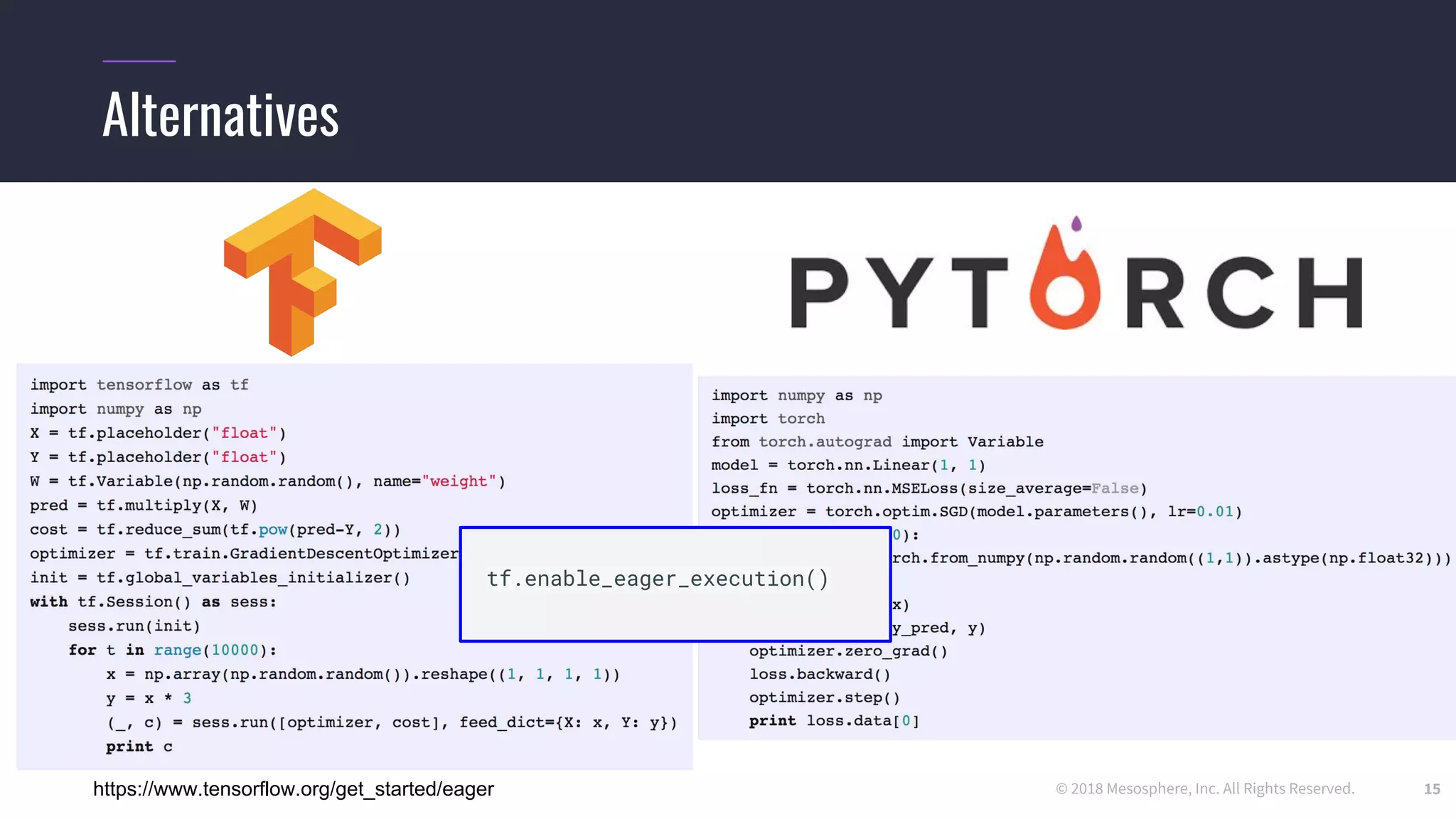
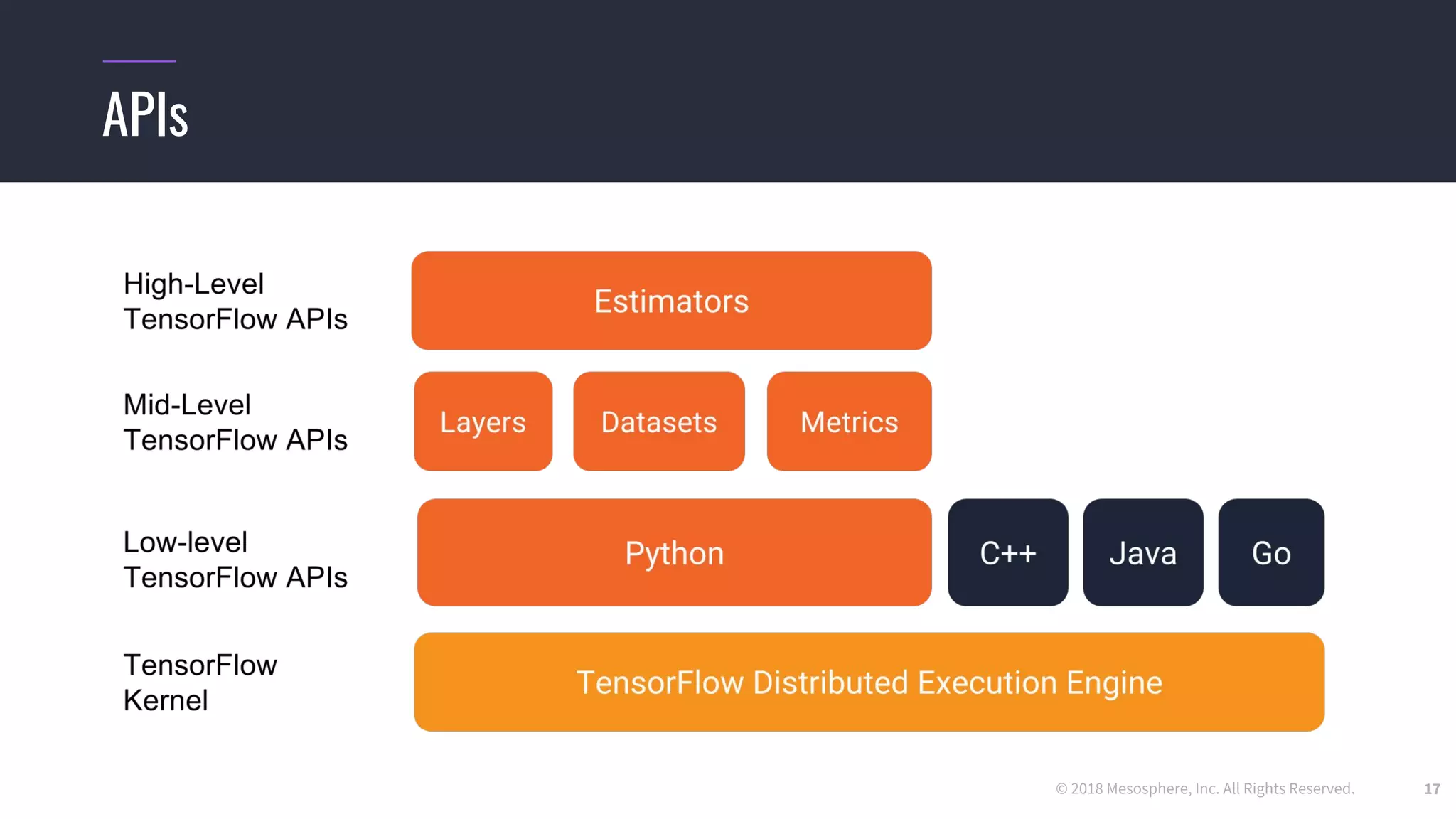
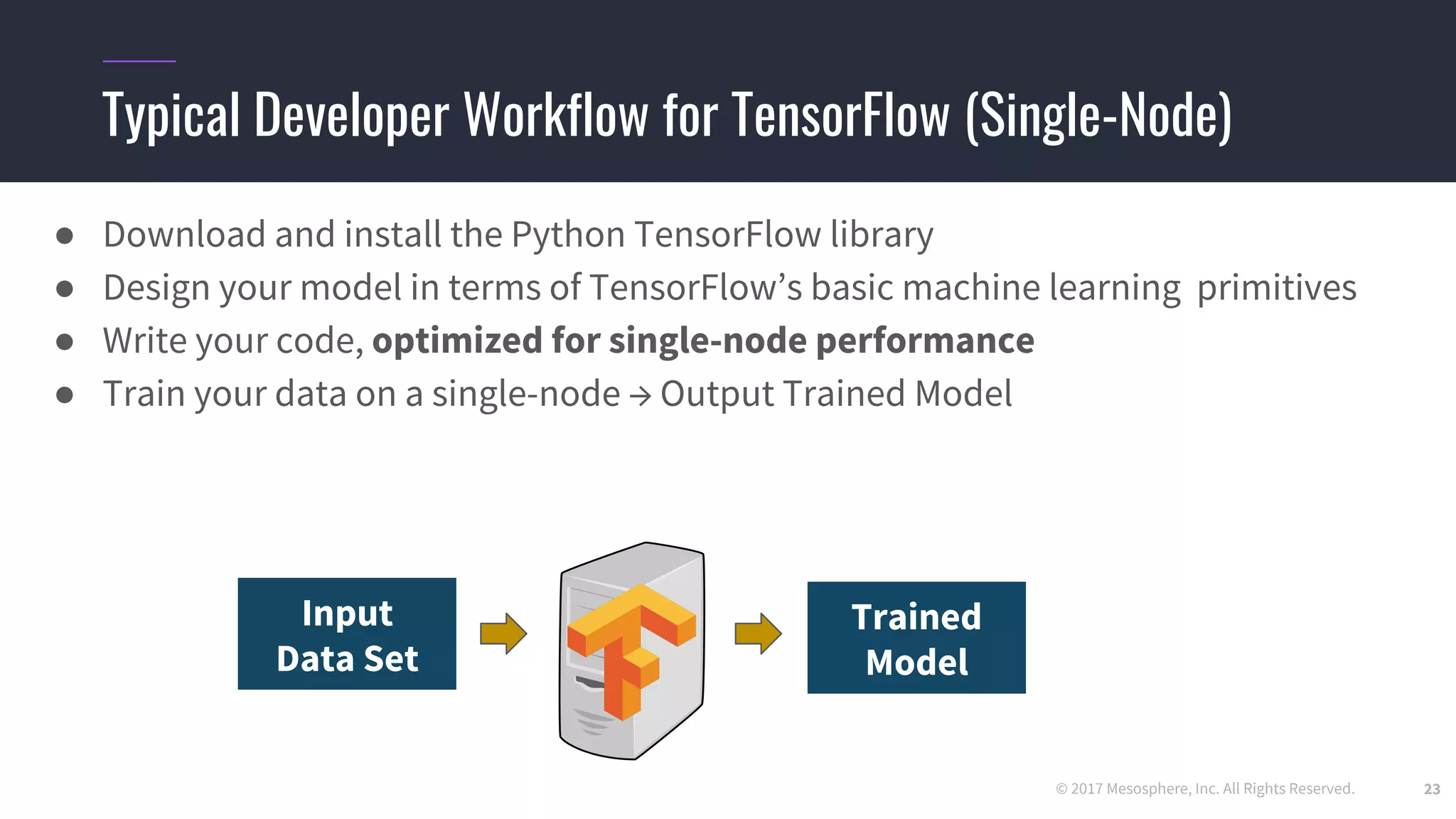
The document outlines the process and challenges of implementing deep learning pipelines, particularly focusing on TensorFlow usage within data centers. It discusses key steps such as model training, inference, and the importance of managing data frameworks, as well as the complexities of distributed machine learning. Additionally, it touches upon various strategies and tools for model serving and management, including TensorFlow Hub and TensorFlow Lite.























































































