Downloaded 38 times











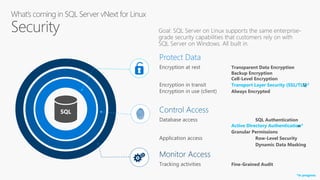


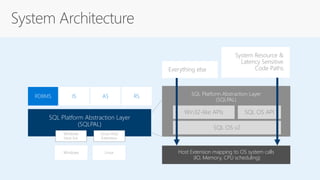


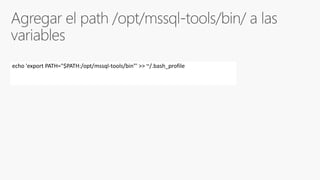


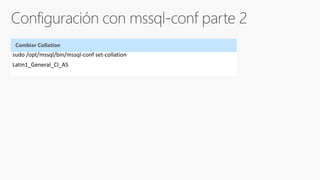


SQL Server 2017 on Linux - SQL Server 2017 will run natively on Linux - It provides the same features and capabilities as SQL Server on Windows - It supports the same editions as Windows and can be licensed with the same license - It has the same database engine and core services as Windows - Some advanced features like PolyBase and Stretch Database are not yet supported on Linux - It uses a new platform abstraction layer to run on Linux









































































































