Downloaded 10 times








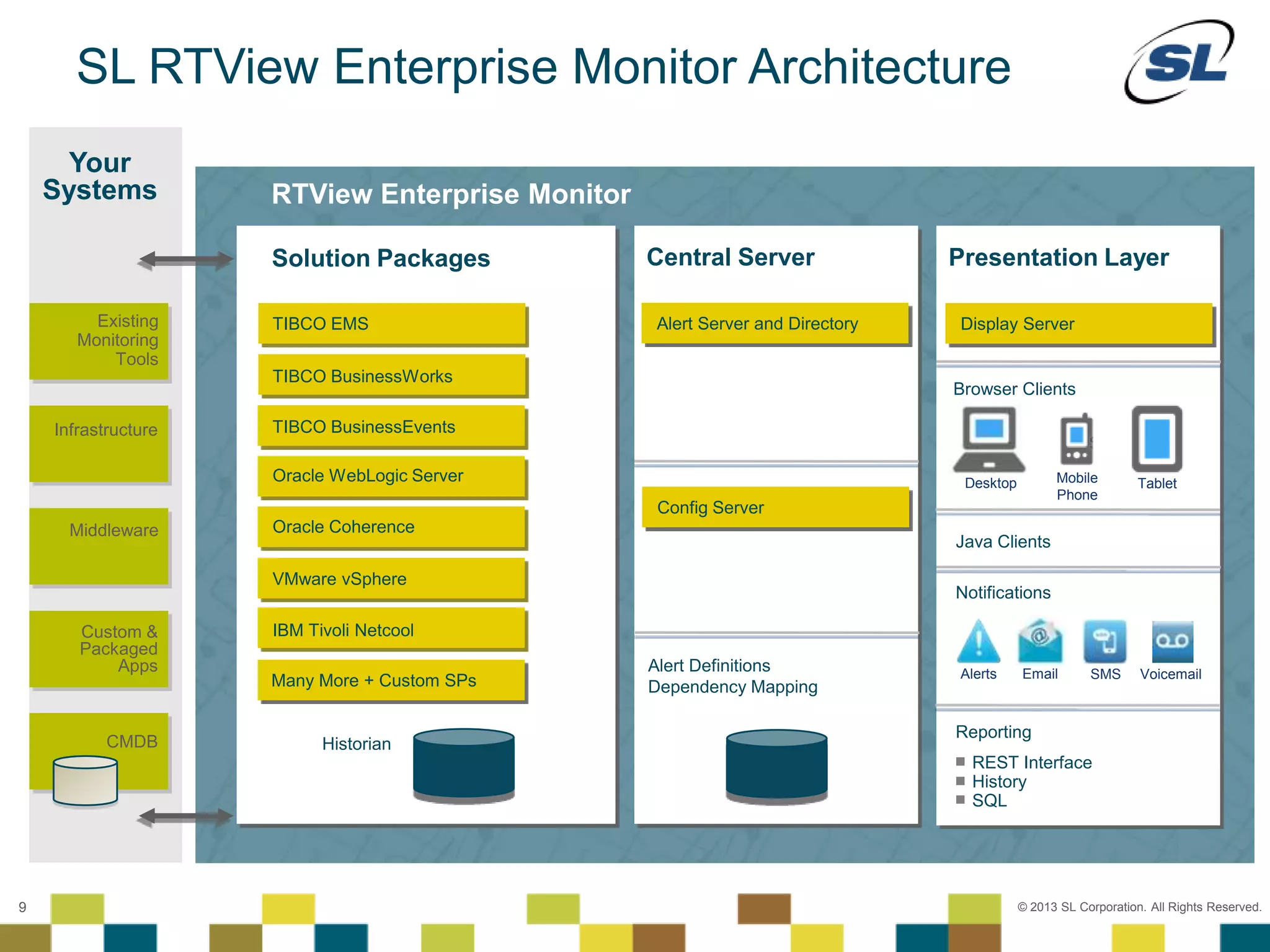
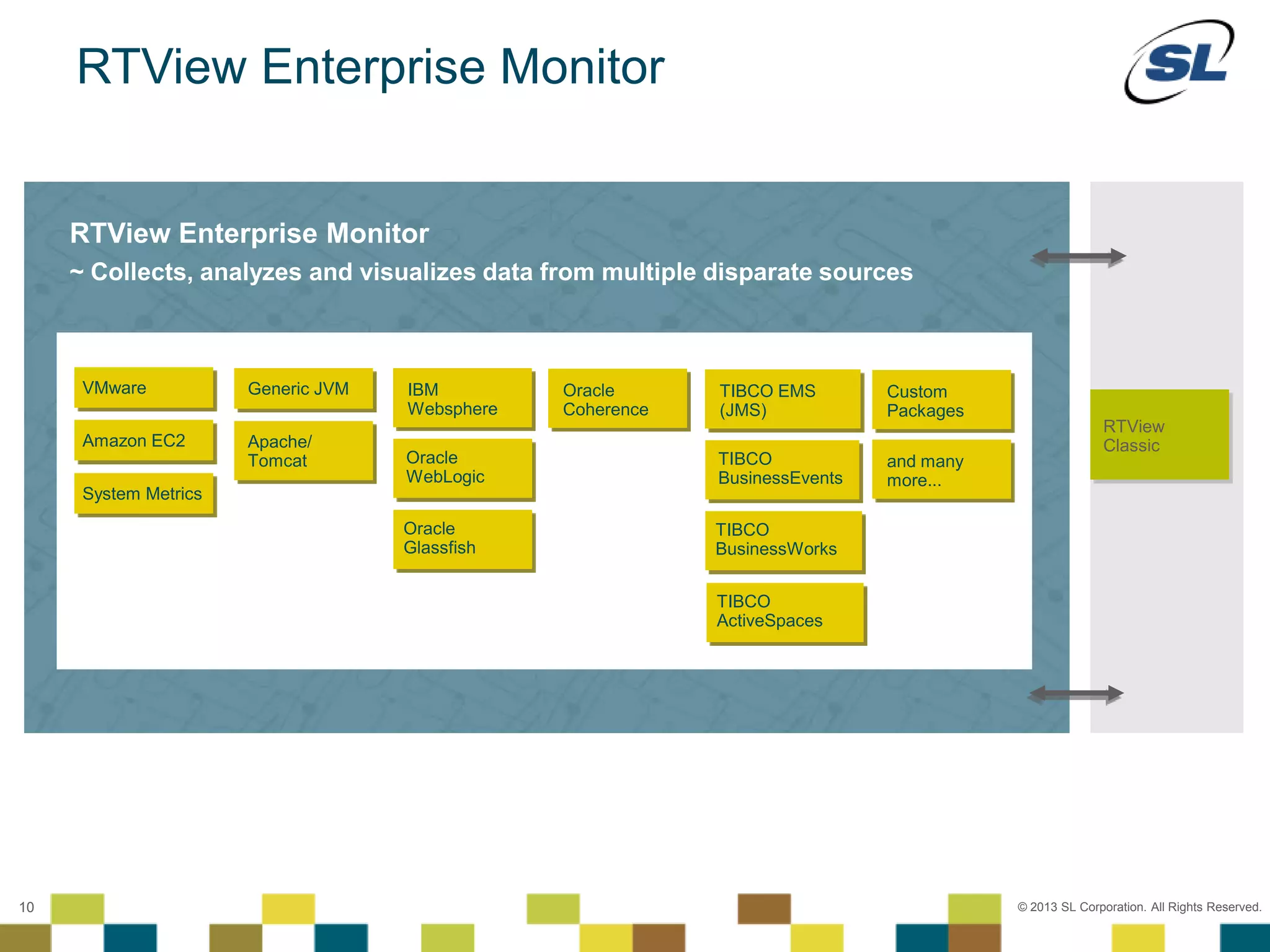
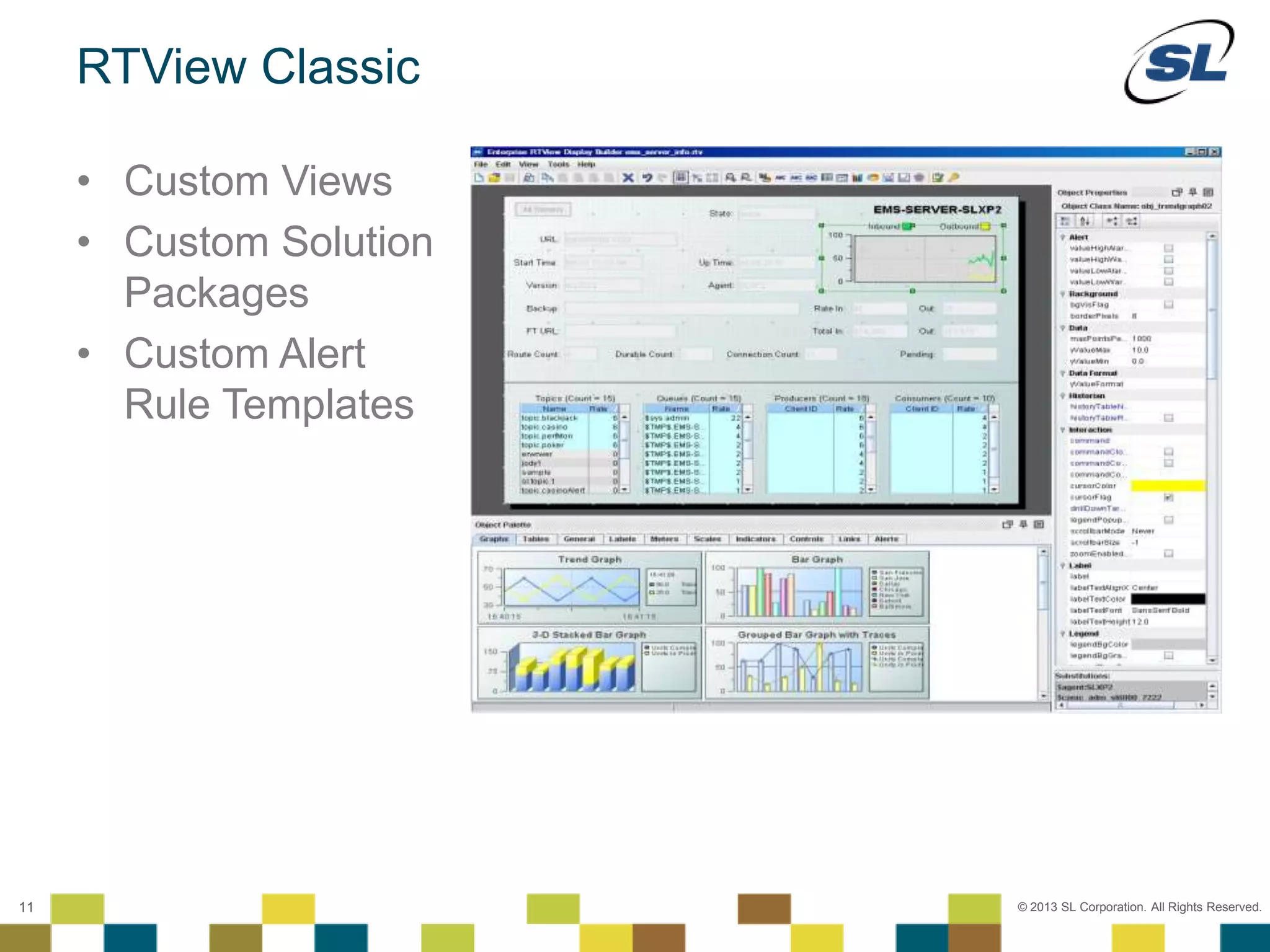

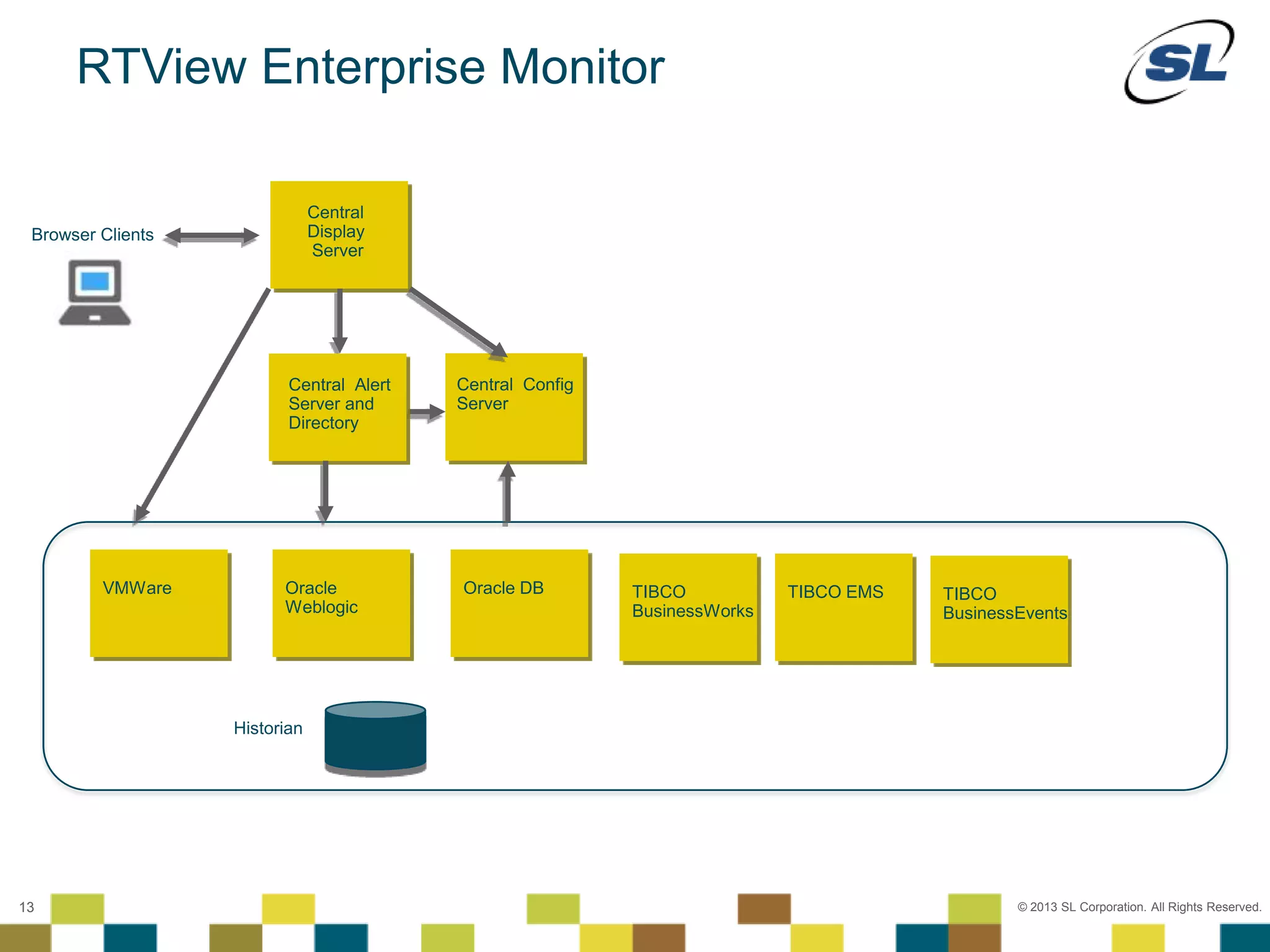
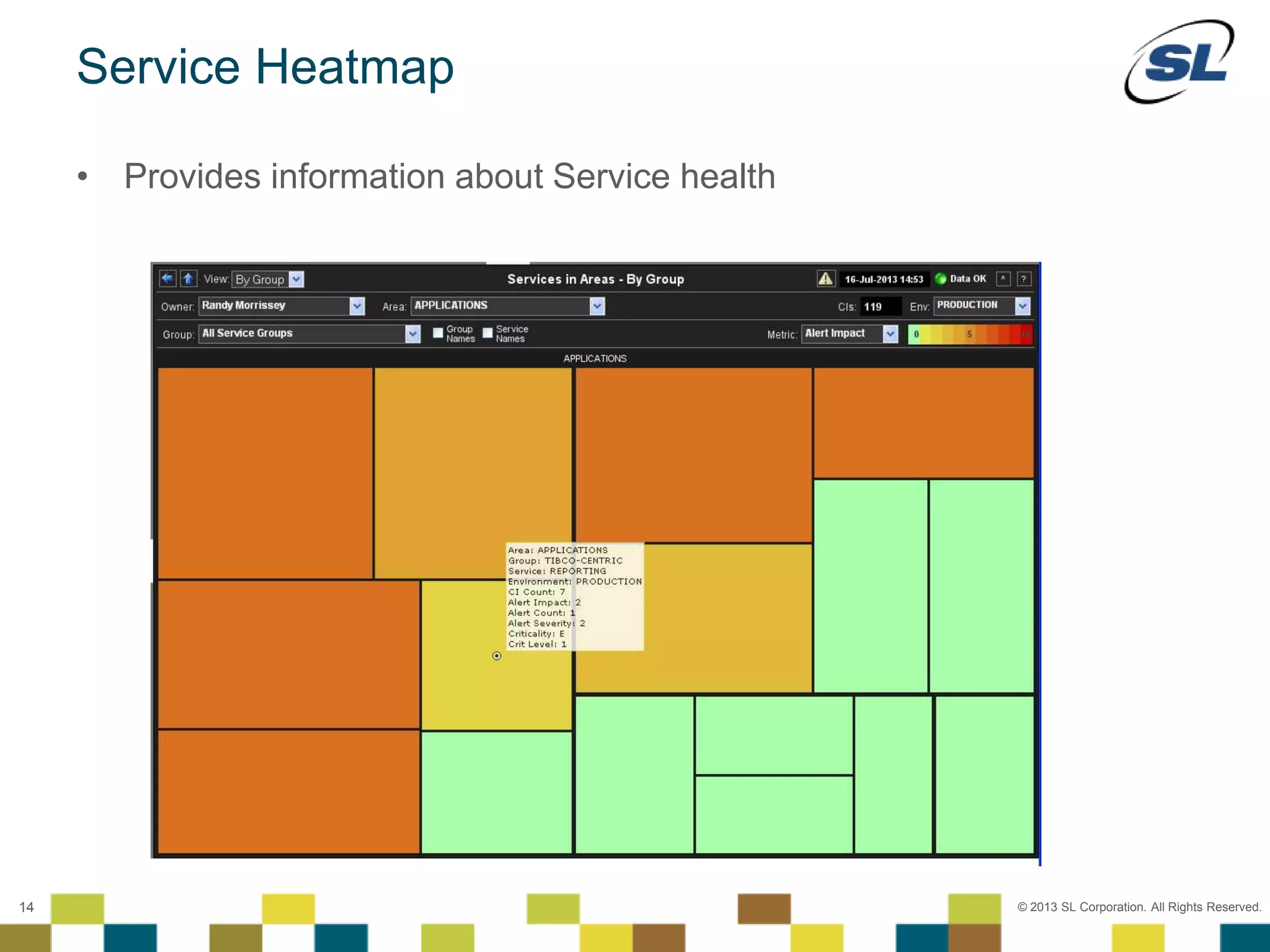
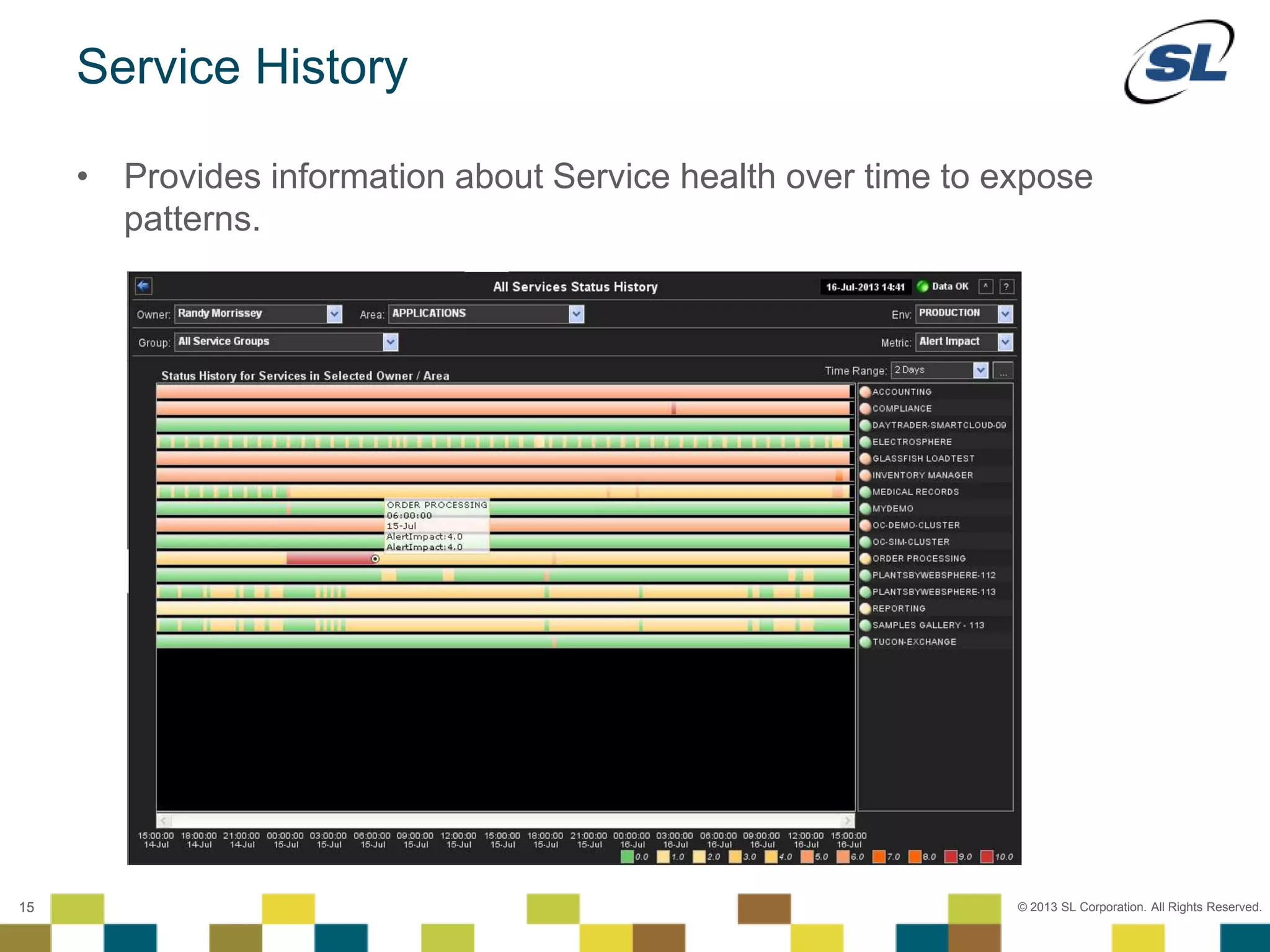
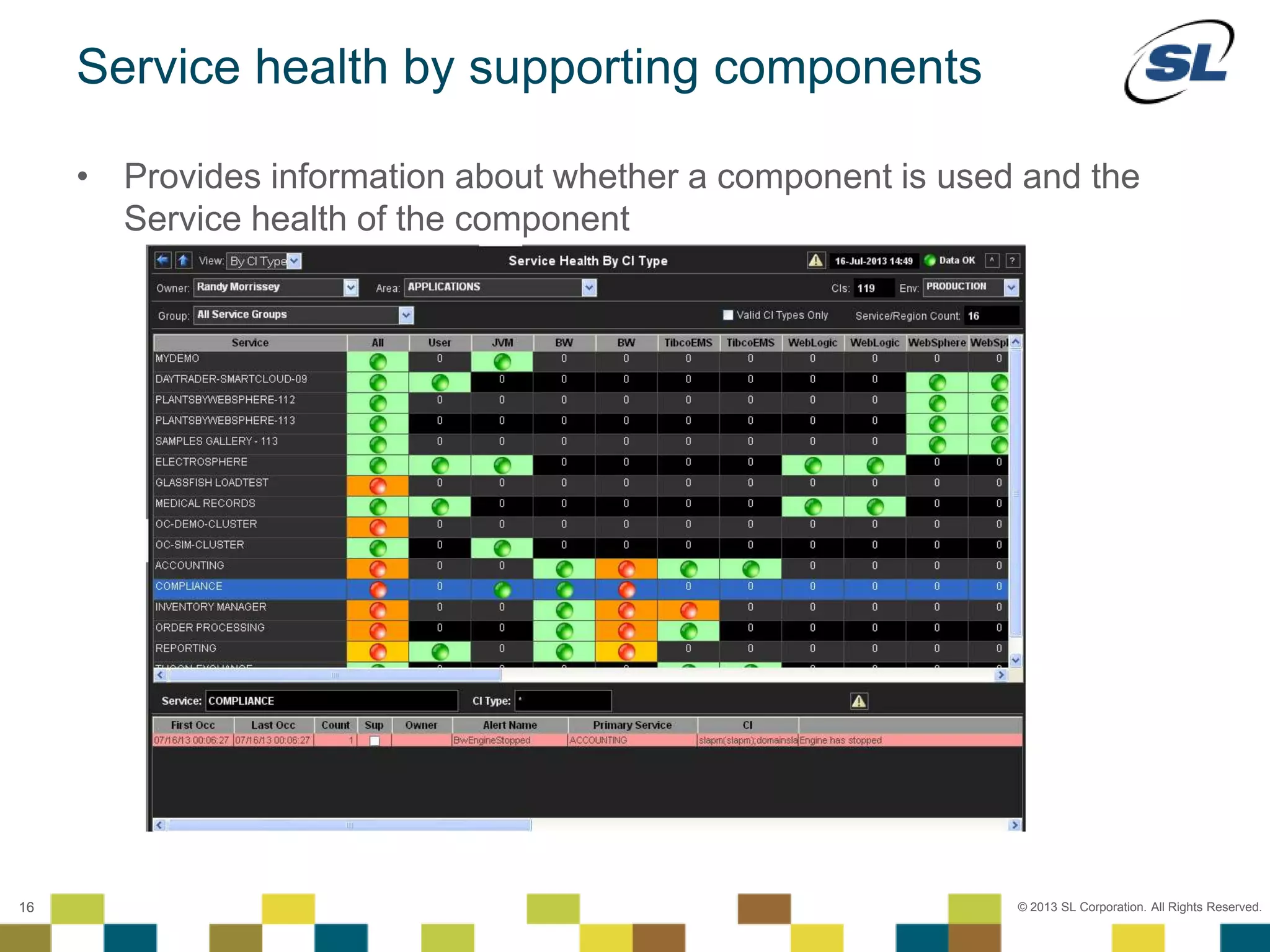
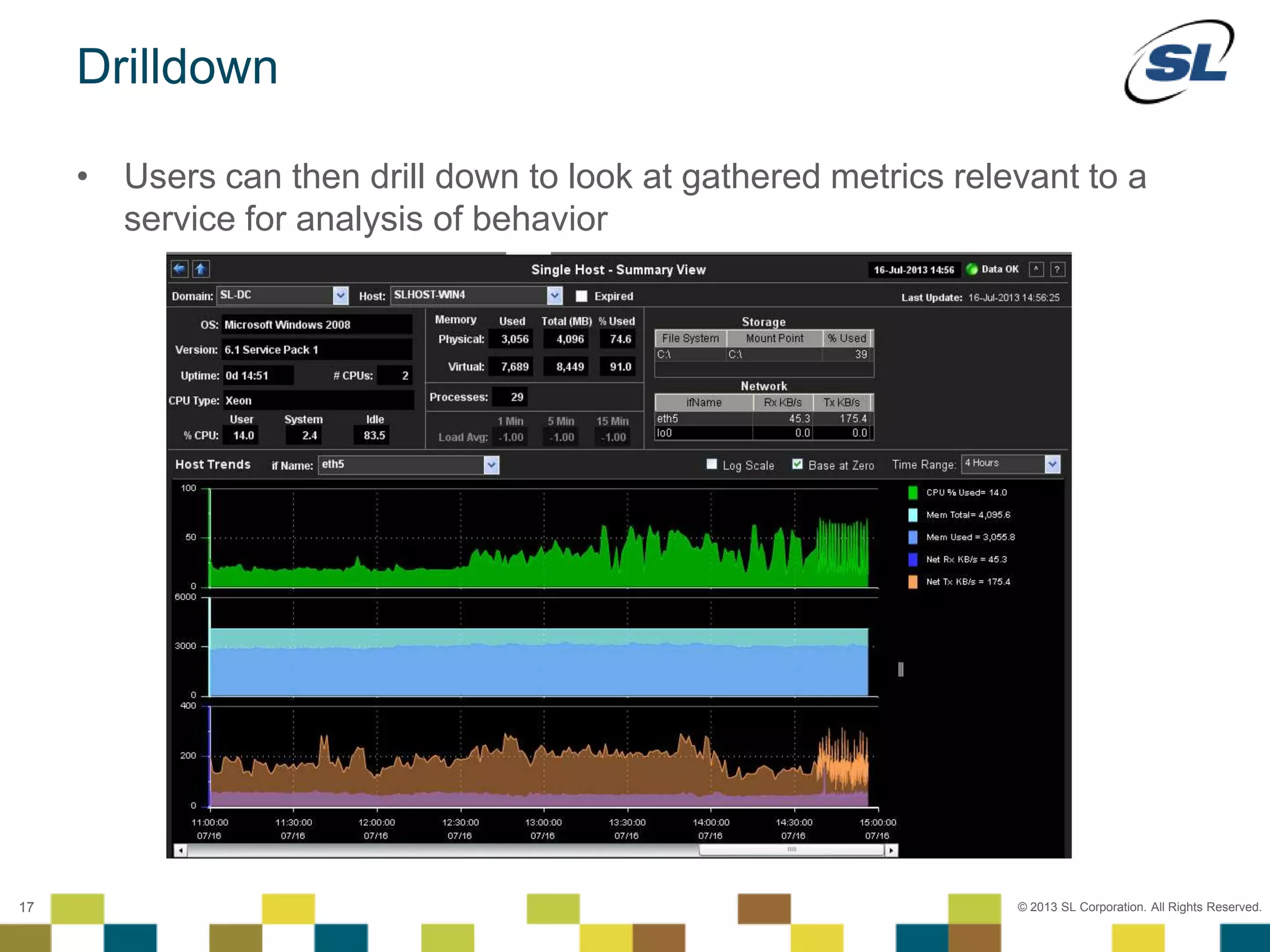


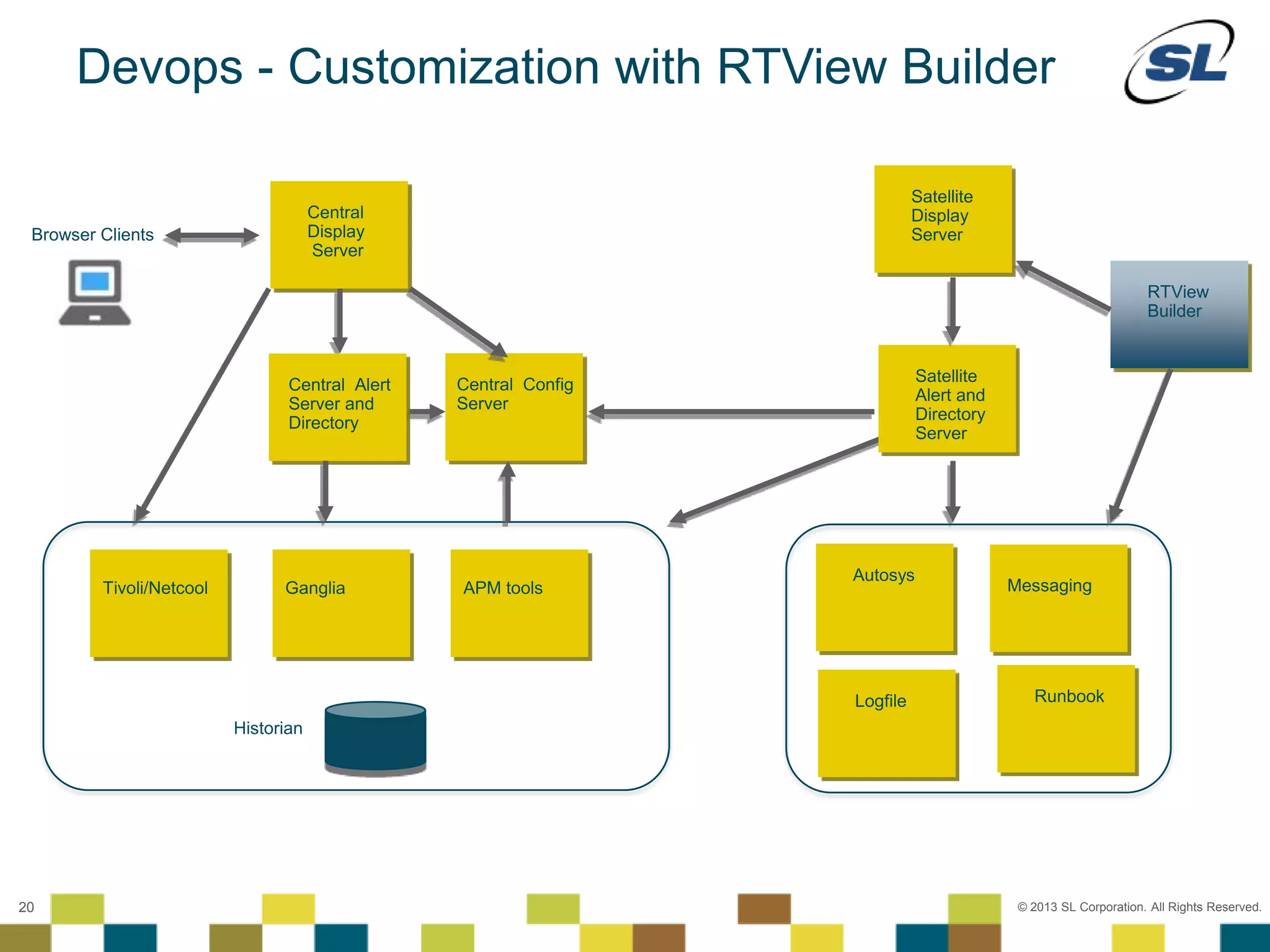
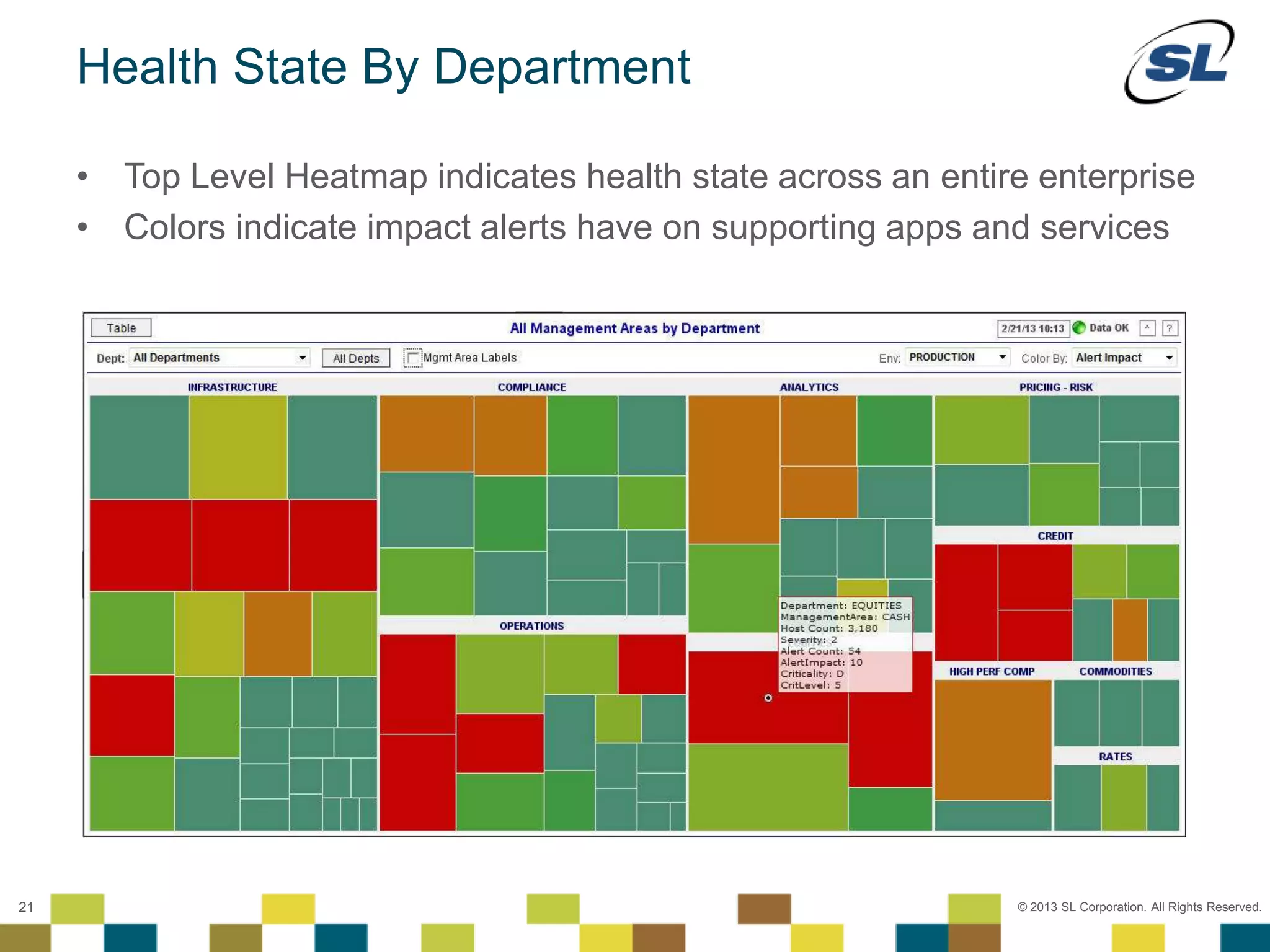
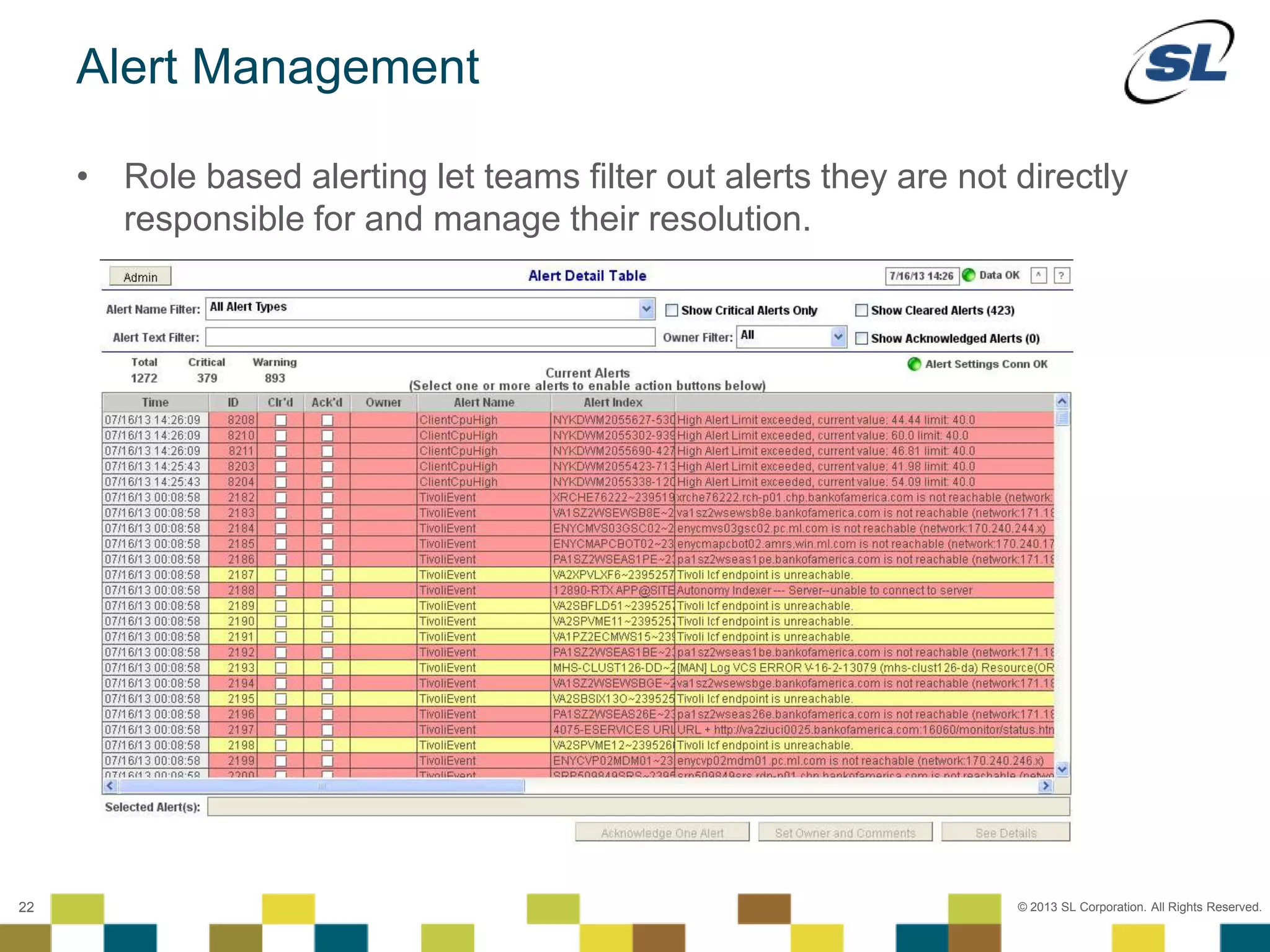




The document discusses Application Performance Management (APM), highlighting its limitations and the need for end-to-end visibility in monitoring. It presents trends in monitoring technologies and showcases RTView Enterprise Monitor as a solution for integrating diverse performance data. Several case studies illustrate the implementation and benefits of the RTView solution in optimizing operations in various organizational contexts.








































































































