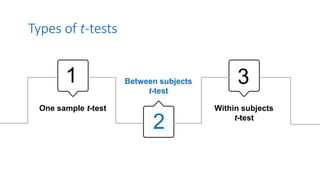
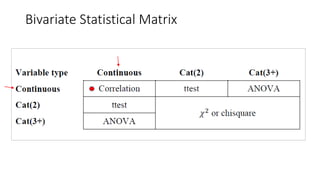
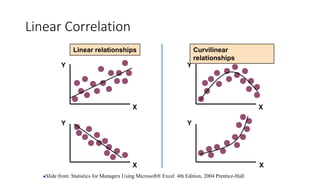
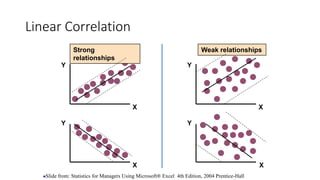
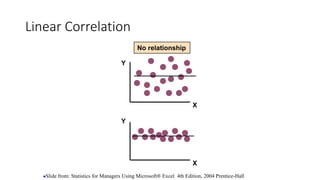
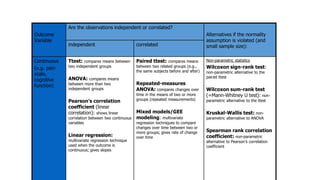
1. The document discusses different types of t-tests including the between subjects t-test.
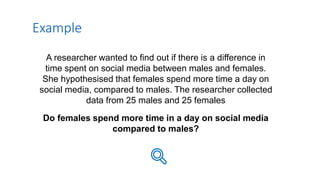
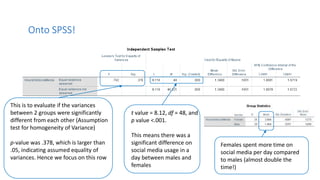
2. It provides an example of using a between subjects t-test to compare time spent on social media between males and females, with results showing females spent significantly more time than males.
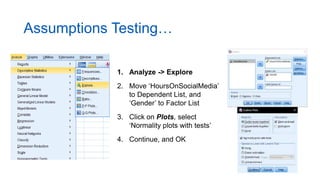
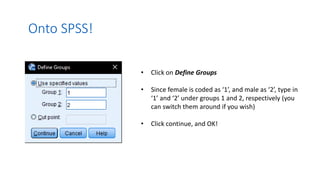
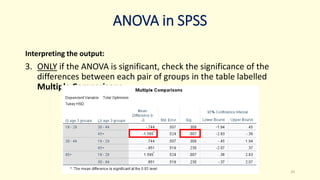
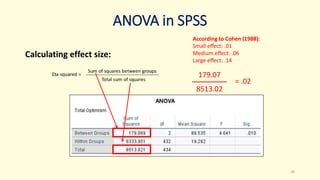
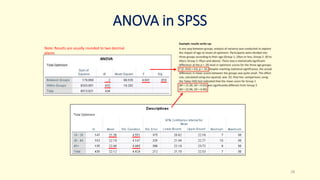
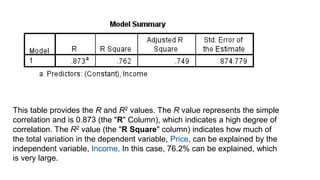
3. Guidance is given on testing assumptions, conducting the t-test in SPSS, and interpreting the results including a significant difference found between the groups.















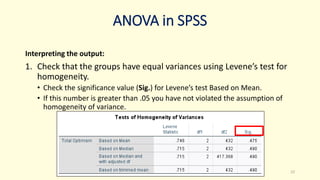
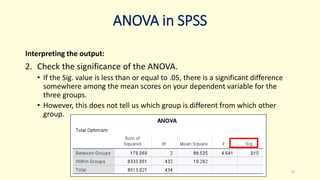










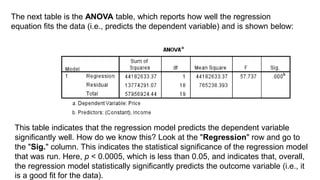
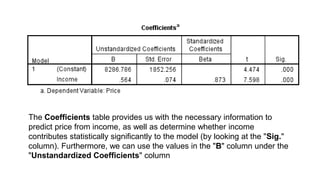















































![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)
